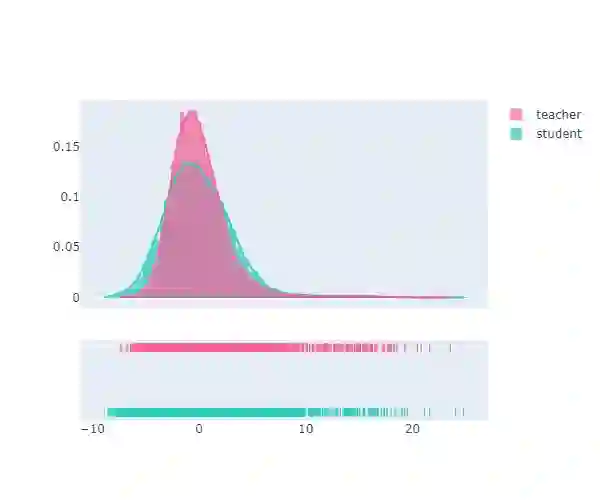
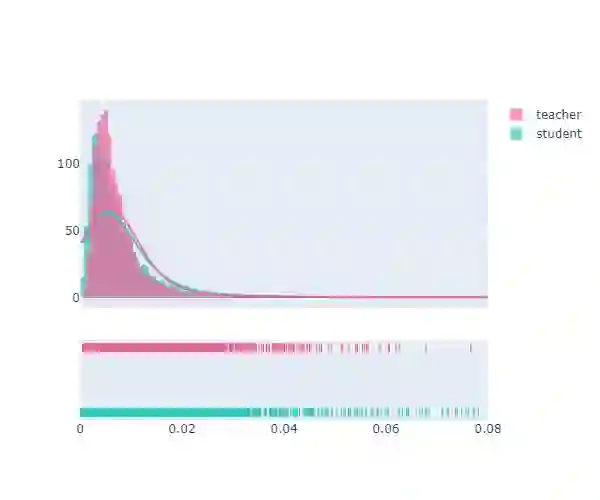
Knowledge distillation typically employs the Kullback-Leibler (KL) divergence to constrain the student model's output to match the soft labels provided by the teacher model exactly. However, sometimes the optimization direction of the KL divergence loss is not always aligned with the task loss, where a smaller KL divergence could lead to erroneous predictions that diverge from the soft labels. This limitation often results in suboptimal optimization for the student. Moreover, even under temperature scaling, the KL divergence loss function tends to overly focus on the larger-valued channels in the logits, disregarding the rich inter-class information provided by the multitude of smaller-valued channels. This hard constraint proves too challenging for lightweight students, hindering further knowledge distillation. To address this issue, we propose a plug-and-play ranking loss based on Kendall's $\tau$ coefficient, called Rank-Kendall Knowledge Distillation (RKKD). RKKD balances the attention to smaller-valued channels by constraining the order of channel values in student logits, providing more inter-class relational information. The rank constraint on the top-valued channels helps avoid suboptimal traps during optimization. We also discuss different differentiable forms of Kendall's $\tau$ coefficient and demonstrate that the proposed ranking loss function shares a consistent optimization objective with the KL divergence. Extensive experiments on the CIFAR-100 and ImageNet datasets show that our RKKD can enhance the performance of various knowledge distillation baselines and offer broad improvements across multiple teacher-student architecture combinations.
翻译:知识蒸馏通常采用Kullback-Leibler(KL)散度来约束学生模型的输出,使其精确匹配教师模型提供的软标签。然而,KL散度损失的优化方向有时并不总是与任务损失一致,较小的KL散度可能导致与软标签偏离的错误预测。这一局限常导致学生模型的优化陷入次优状态。此外,即使在温度缩放条件下,KL散度损失函数也倾向于过度关注logits中数值较大的通道,而忽视大量数值较小通道所提供的丰富类间信息。这种硬约束对轻量级学生模型而言过于严苛,阻碍了知识蒸馏的进一步优化。为解决此问题,我们提出一种基于Kendall $\tau$系数的即插即用排序损失,称为Rank-Kendall知识蒸馏(RKKD)。RKKD通过约束学生模型logits中通道值的排序,平衡对数值较小通道的关注度,从而提供更多类间关系信息。对高值通道的排序约束有助于避免优化过程中的次优陷阱。我们还探讨了Kendall $\tau$系数的不同可微形式,并证明所提出的排序损失函数与KL散度具有一致的优化目标。在CIFAR-100和ImageNet数据集上的大量实验表明,我们的RKKD能够提升多种知识蒸馏基线的性能,并在多种师生架构组合中带来广泛的改进。