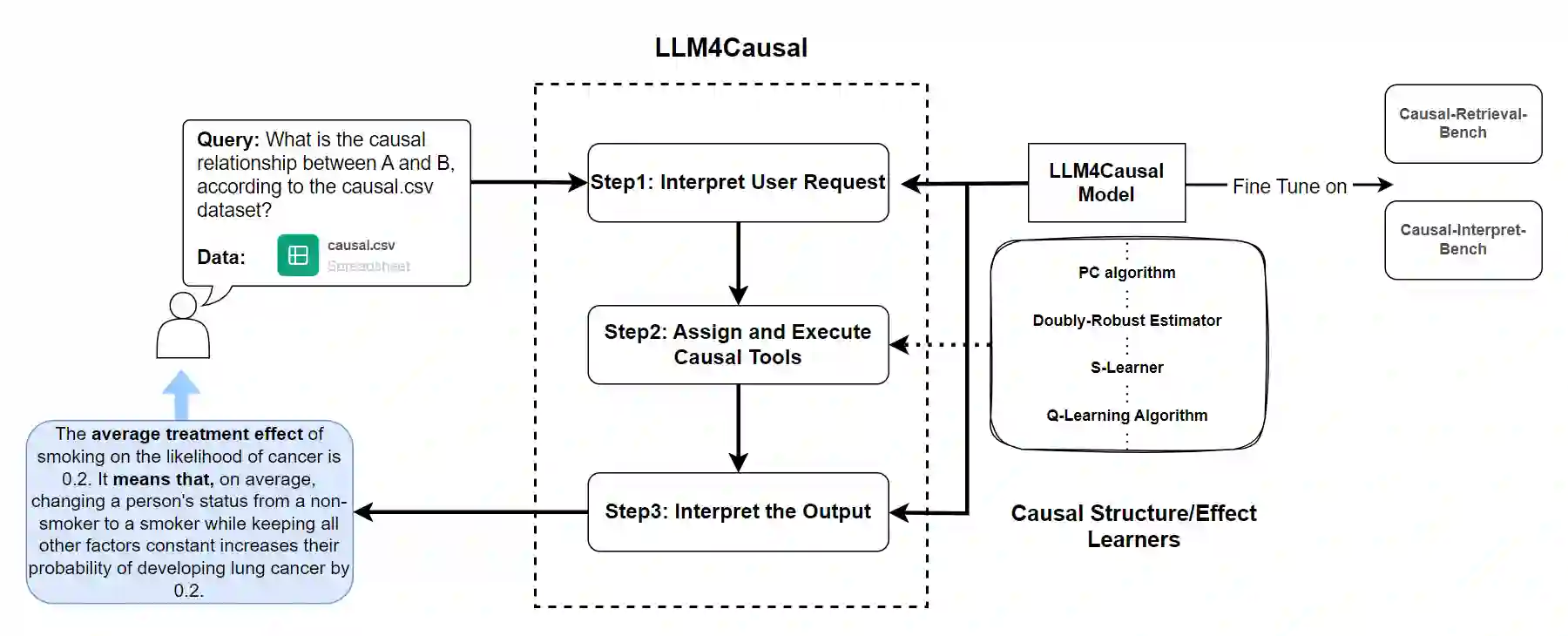
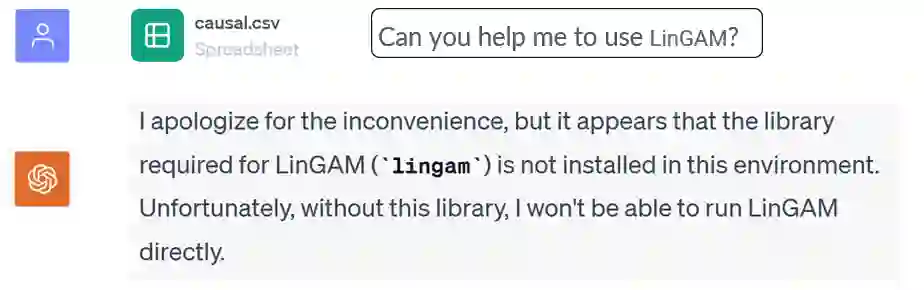
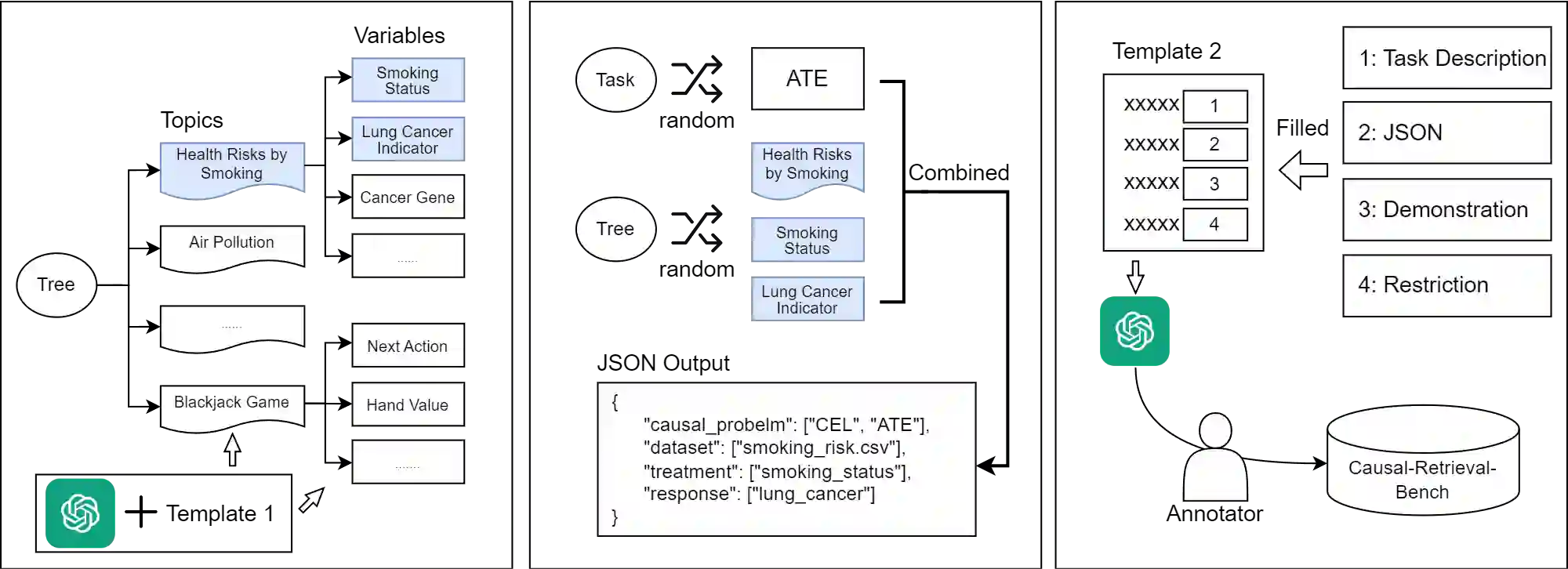
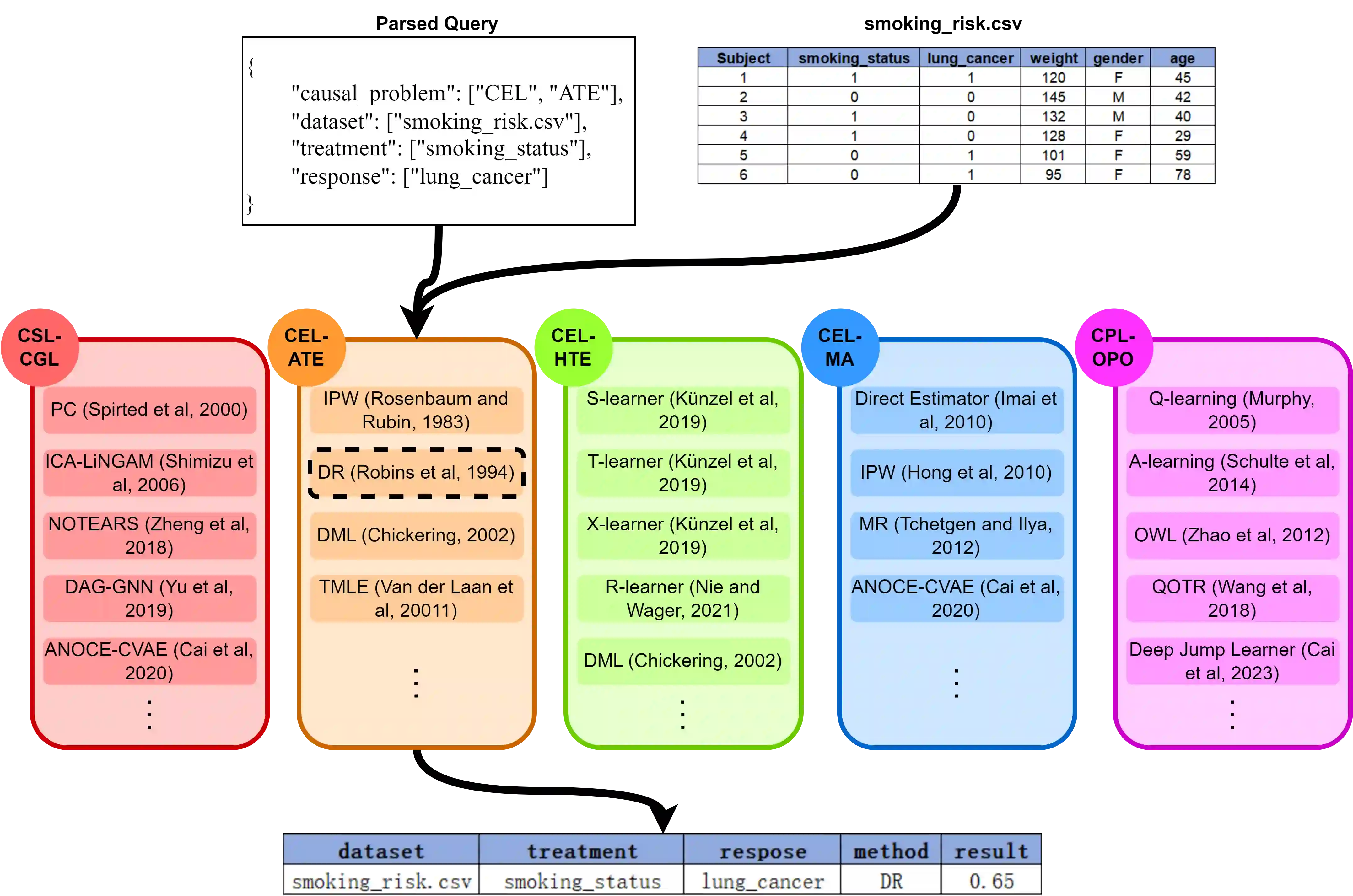
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to inference based on user-specified structured data and knowledge in corpus-rare concepts like causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. With three case studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers. Numerical studies also reveal that it has a remarkable ability to identify the correct causal task given a query.
翻译:大型语言模型(LLMs)在通用主题的语言理解与推理中已展现出成功。然而,它们在基于用户指定的结构化数据和因果决策等语料稀缺概念上的推理能力仍有限。本研究探索将开源LLM微调为LLM4Causal的可能性,该模型能根据用户查询和所提供数据集识别因果任务、执行相应函数并解释数值结果。同时,我们提出一种更可控的GPT提示数据生成流程,并构建两个指令微调数据集:(1)Causal-Retrieval-Bench用于因果问题识别及因果函数调用的输入参数提取,(2)Causal-Interpret-Bench用于上下文因果解释。通过三个案例研究,我们证明LLM4Causal能为因果问题提供端到端解决方案并输出易理解的答案。数值研究还揭示其在给定查询时识别正确因果任务的显著能力。