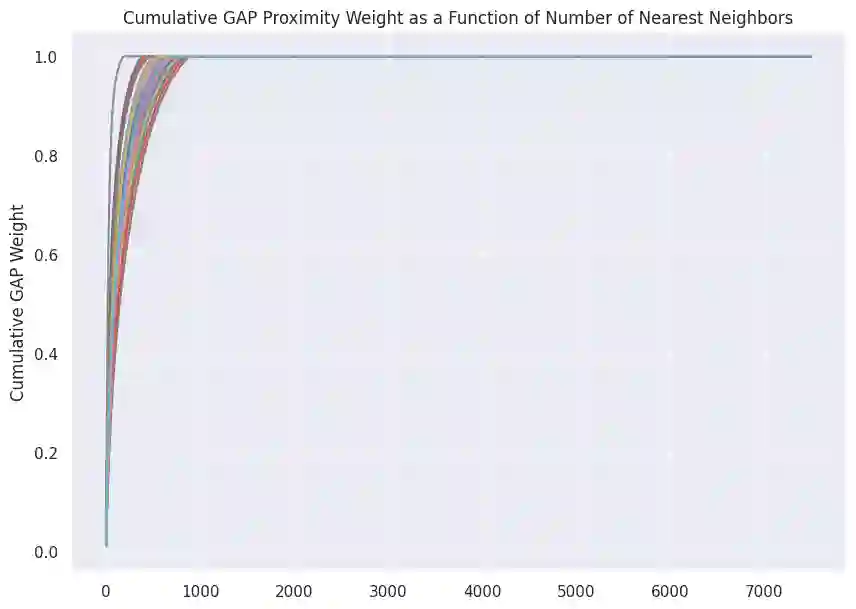
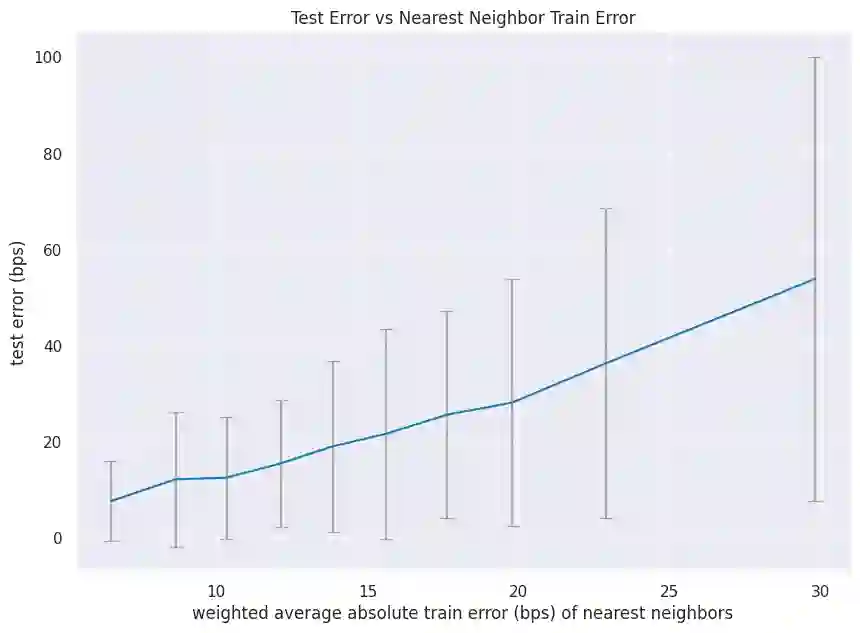
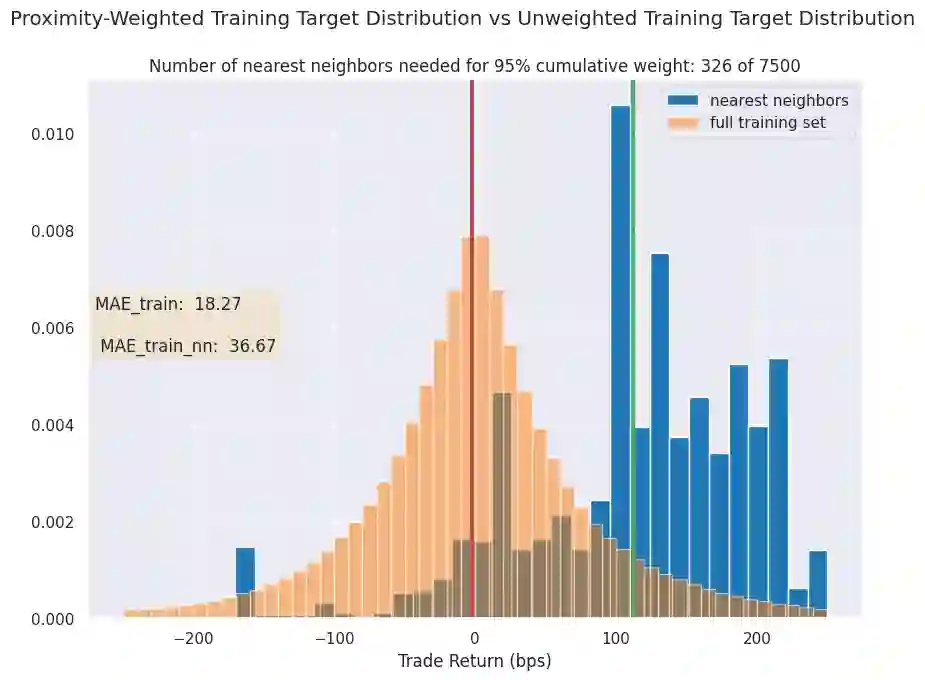
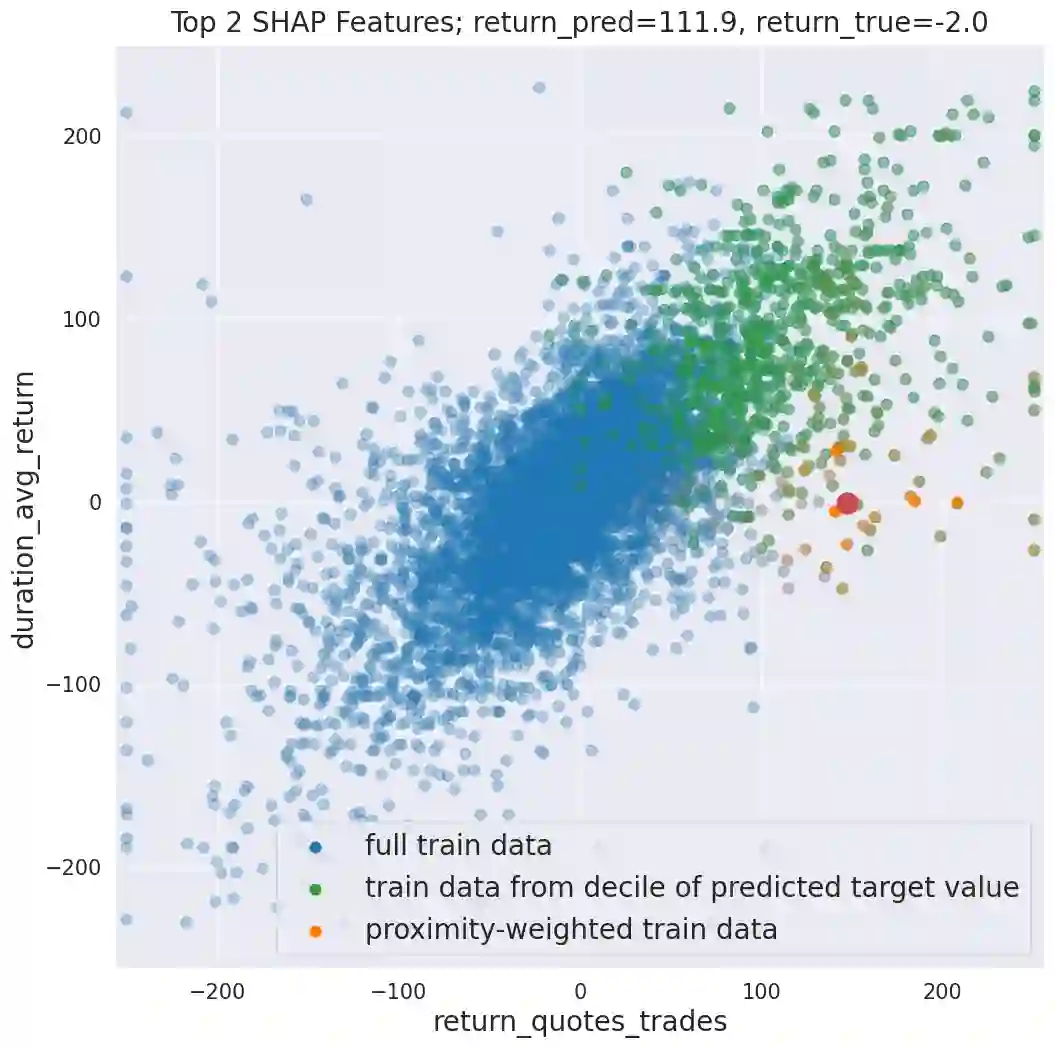
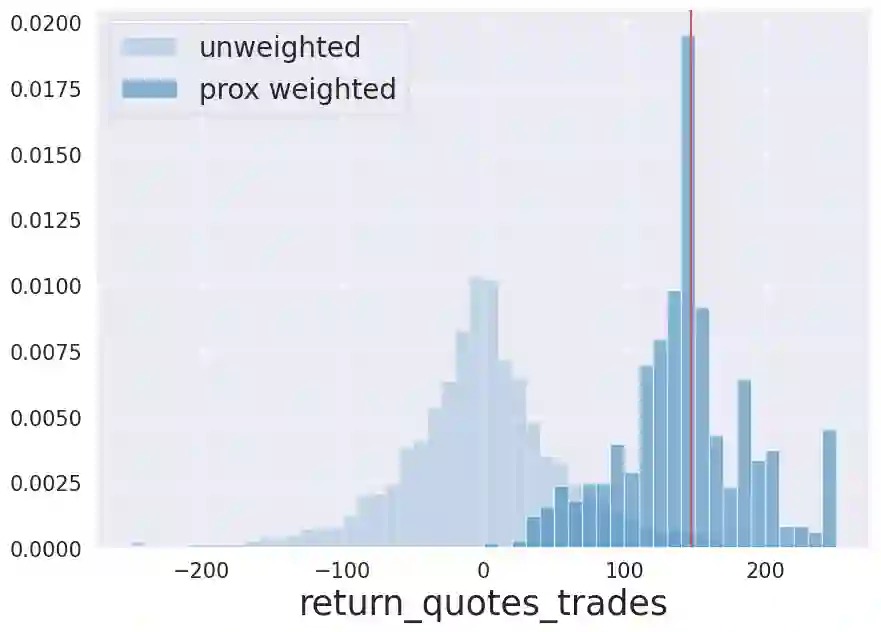
We initiate a novel approach to explain the predictions and out of sample performance of random forest (RF) regression and classification models by exploiting the fact that any RF can be mathematically formulated as an adaptive weighted K nearest-neighbors model. Specifically, we employ a recent result that, for both regression and classification tasks, any RF prediction can be rewritten exactly as a weighted sum of the training targets, where the weights are RF proximities between the corresponding pairs of data points. We show that this linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established feature-based methods like SHAP, which generate attributions for a model prediction across input features. We show how this proximity-based approach to explainability can be used in conjunction with SHAP to explain not just the model predictions, but also out-of-sample performance, in the sense that proximities furnish a novel means of assessing when a given model prediction is more or less likely to be correct. We demonstrate this approach in the modeling of US corporate bond prices and returns in both regression and classification cases.
翻译:我们提出了一种新颖方法,通过利用随机森林(RF)回归与分类模型可被数学表述为自适应加权K最近邻模型这一特性,来解释其预测结果及样本外表现。具体而言,我们采用最新研究成果表明:对于回归和分类任务,任何RF预测均可精确重写为训练目标值的加权和,其中权重即对应数据点对之间的RF邻近度。我们证明这种线性特性促进了RF预测的局部可解释性概念,能为训练集中任意观测值的模型预测生成归因,从而与SHAP等成熟的基于特征的解释方法形成互补——后者通过输入特征维度生成模型预测归因。我们进一步展示这种基于邻近度的可解释性方法如何与SHAP结合使用,不仅能解释模型预测,还能评估样本外表现:邻近度为判断特定模型预测正确概率提供了全新度量依据。我们通过美国公司债券价格与收益的回归及分类建模案例验证了该方法的有效性。