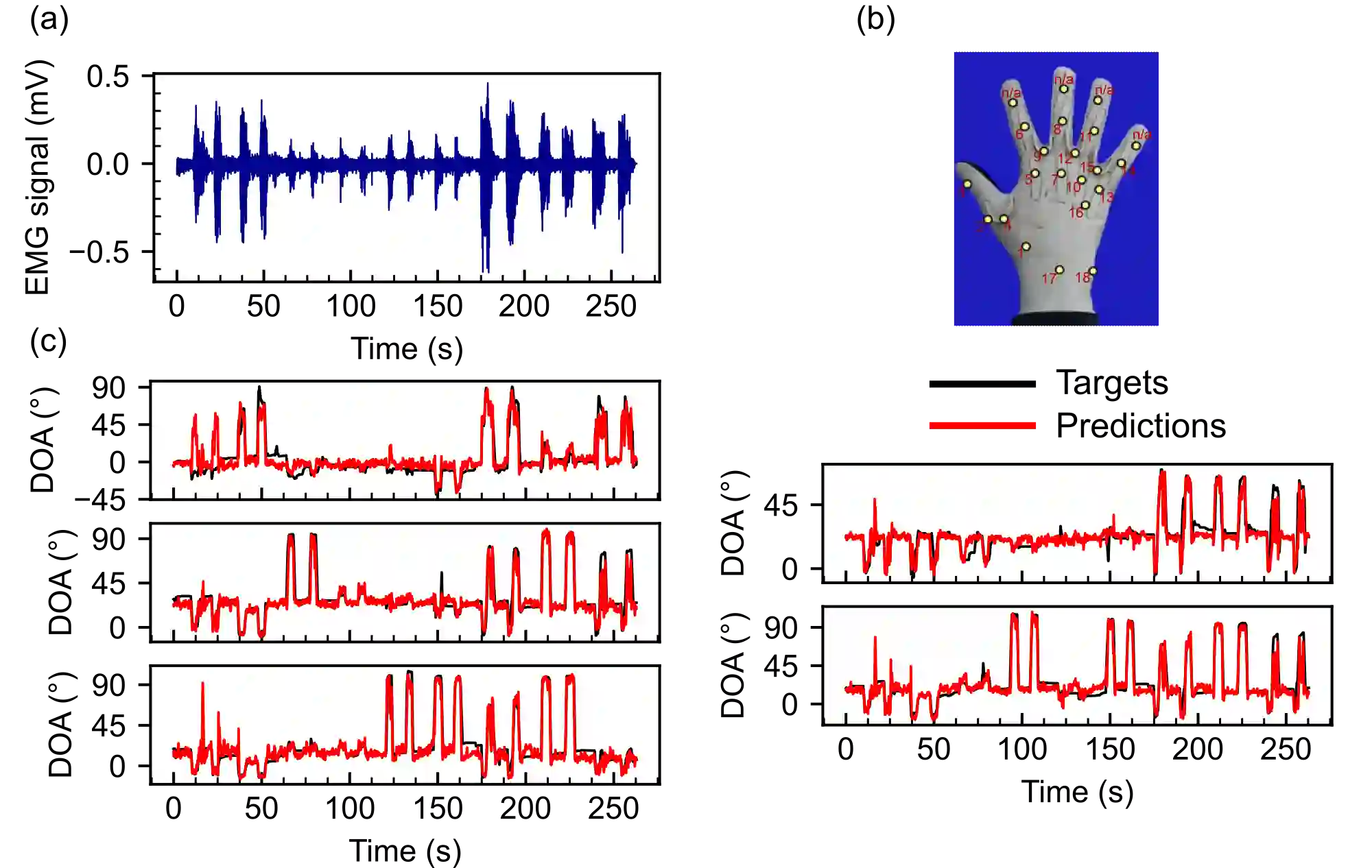
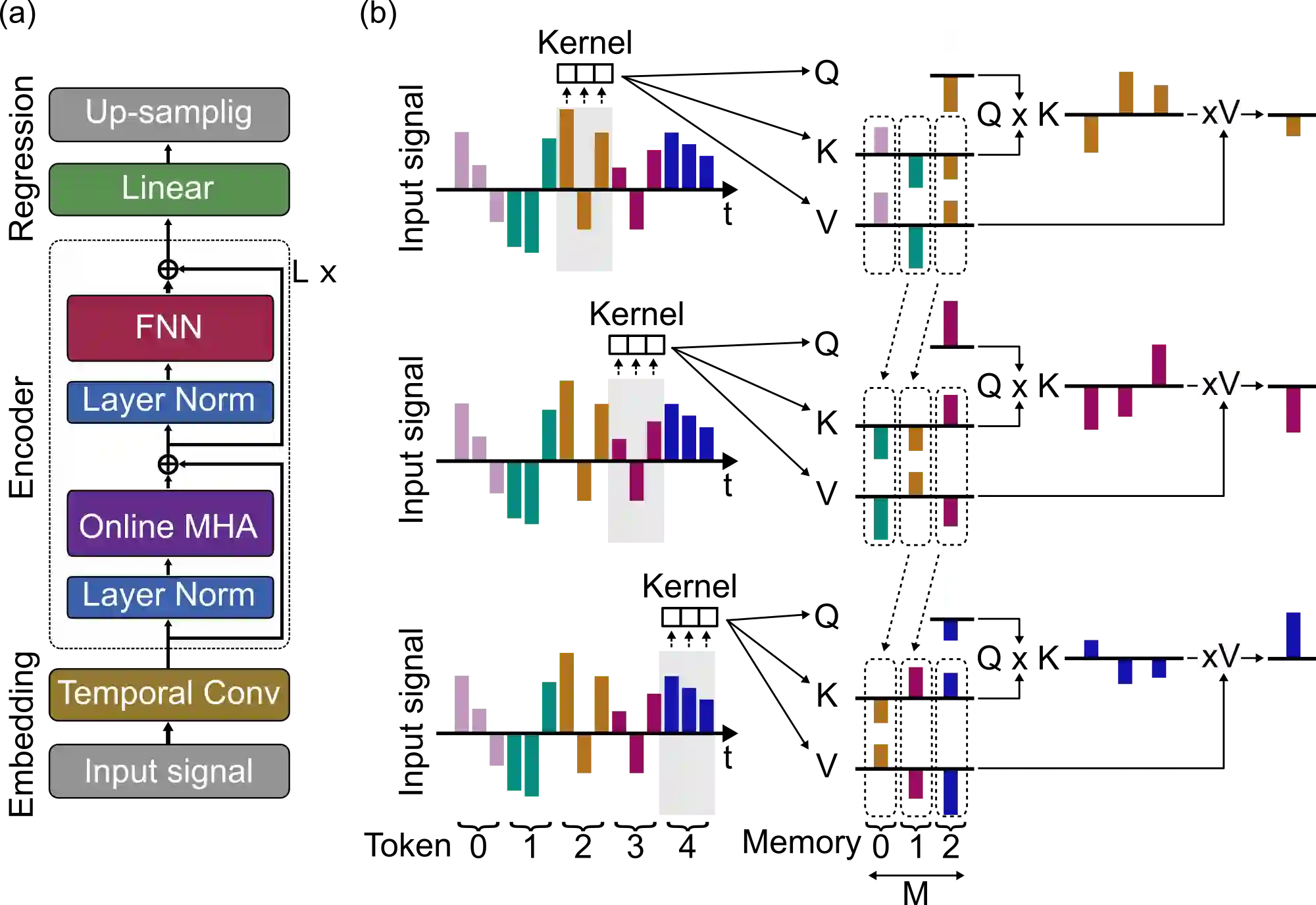
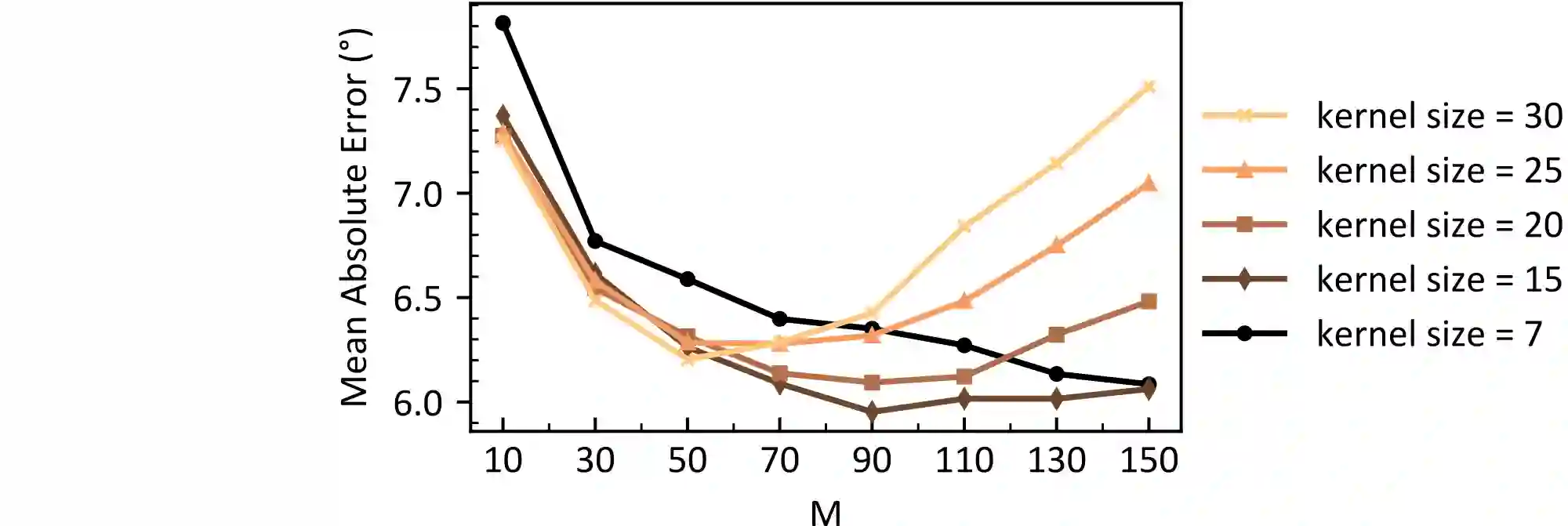
Transformers are state-of-the-art networks for most sequence processing tasks. However, the self-attention mechanism often used in Transformers requires large time windows for each computation step and thus makes them less suitable for online signal processing compared to Recurrent Neural Networks (RNNs). In this paper, instead of the self-attention mechanism, we use a sliding window attention mechanism. We show that this mechanism is more efficient for continuous signals with finite-range dependencies between input and target, and that we can use it to process sequences element-by-element, this making it compatible with online processing. We test our model on a finger position regression dataset (NinaproDB8) with Surface Electromyographic (sEMG) signals measured on the forearm skin to estimate muscle activities. Our approach sets the new state-of-the-art in terms of accuracy on this dataset while requiring only very short time windows of 3.5 ms at each inference step. Moreover, we increase the sparsity of the network using Leaky-Integrate and Fire (LIF) units, a bio-inspired neuron model that activates sparsely in time solely when crossing a threshold. We thus reduce the number of synaptic operations up to a factor of $\times5.3$ without loss of accuracy. Our results hold great promises for accurate and fast online processing of sEMG signals for smooth prosthetic hand control and is a step towards Transformers and Spiking Neural Networks (SNNs) co-integration for energy efficient temporal signal processing.
翻译:Transformer是当前大多数序列处理任务中最先进的网络架构。然而,Transformer中常用的自注意力机制需要较大的时间窗口进行每次计算,这使得其相较于循环神经网络(RNN)更不适用于在线信号处理。本文提出采用滑动窗口注意力机制替代自注意力机制。实验表明,该机制对于输入与目标间具有有限范围依赖性的连续信号更为高效,且支持逐元素序列处理,从而兼容在线计算模式。我们在基于前臂皮肤表面肌电(sEMG)信号测量肌肉活动的手指位置回归数据集(NinaproDB8)上测试了模型。该方法在仅需每次推理步骤中3.5毫秒极短时间窗口的条件下,在此数据集上实现了新的准确率标杆。此外,我们采用泄漏积分与点火(LIF)单元——一种仅在跨过阈值时稀疏激活的仿生神经元模型——提升网络稀疏性。由此在不损失准确率的前提下将突触操作次数减少至多$\times5.3$倍。研究结果为实现平滑假肢手控制中sEMG信号的精确快速在线处理提供了重要前景,并为Transformer与脉冲神经网络(SNN)协同集成以实现高能效时序信号处理迈出了关键一步。