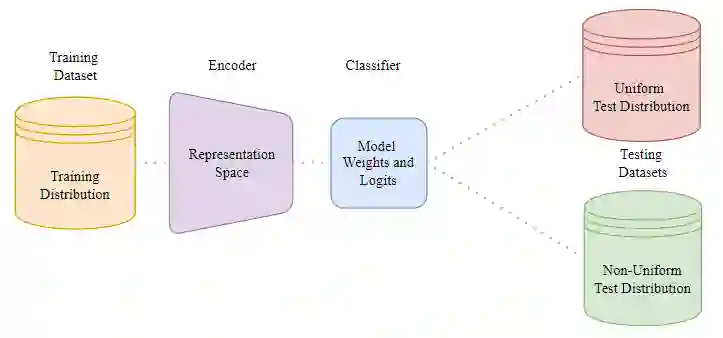
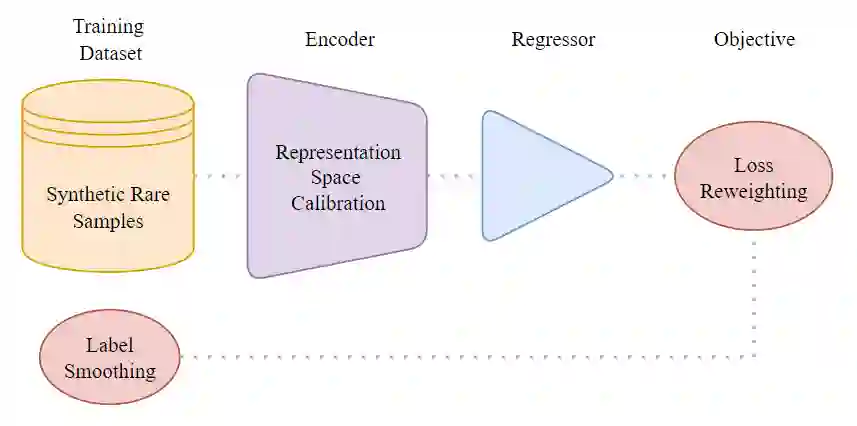
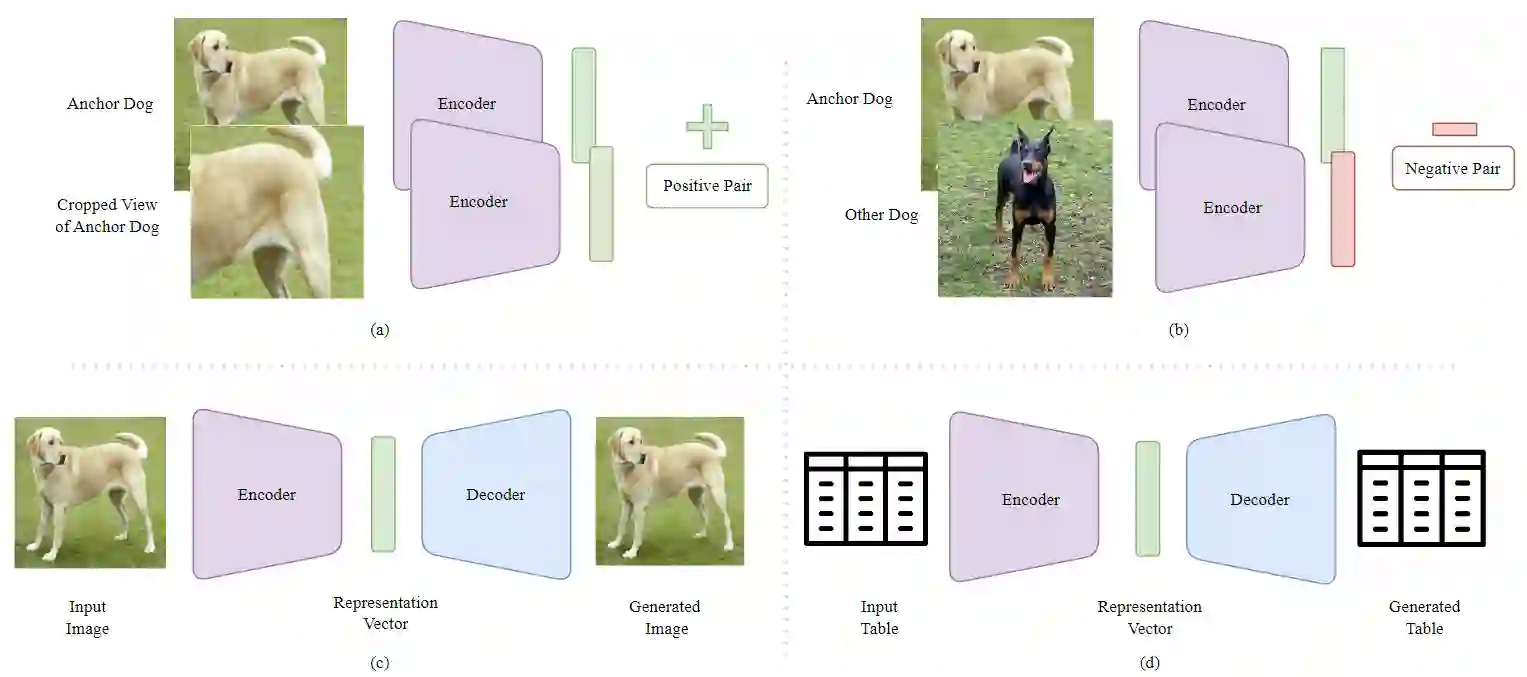
Deep Learning methods have significantly advanced various data-driven tasks such as regression, classification, and forecasting. However, much of this progress has been predicated on the strong but often unrealistic assumption that training datasets are balanced with respect to the targets they contain. This misalignment with real-world conditions, where data is frequently imbalanced, hampers the effectiveness of such models in practical applications. Methods that reconsider that assumption and tackle real-world imbalances have begun to emerge and explore avenues to address this challenge. One such promising avenue is representation learning, which enables models to capture complex data characteristics and generalize better to minority classes. By focusing on a richer representation of the feature space, these techniques hold the potential to mitigate the impact of data imbalance. In this survey, we present deep learning works that step away from the balanced-data assumption, employing strategies like representation learning to better approximate real-world imbalances. We also highlight a critical application in SEP forecasting where addressing data imbalance is paramount for success.
翻译:深度学习方法显著提升了回归、分类和预测等各类数据驱动任务的表现。然而,这些进展大多建立在训练数据集相对于所包含的目标分布是平衡的这一强烈但往往不切实际的假设之上。这种与现实世界常存在数据不平衡条件的脱节,削弱了此类模型在实际应用中的有效性。近年来,开始出现重新审视该假设并处理现实不平衡问题的方法,并探索应对这一挑战的途径。其中颇具前景的一个方向是表示学习,它使模型能够捕捉复杂的数据特征,并对少数类具有更好的泛化能力。通过聚焦于特征空间的更丰富表示,这些技术有望减轻数据不平衡的影响。本综述回顾了深度学习领域中摒弃平衡数据假设、采用诸如表示学习等策略以更贴近现实不平衡场景的研究工作。此外,我们还重点介绍了太阳高能粒子(SEP)预测这一关键应用领域,其中解决数据不平衡问题对成功至关重要。