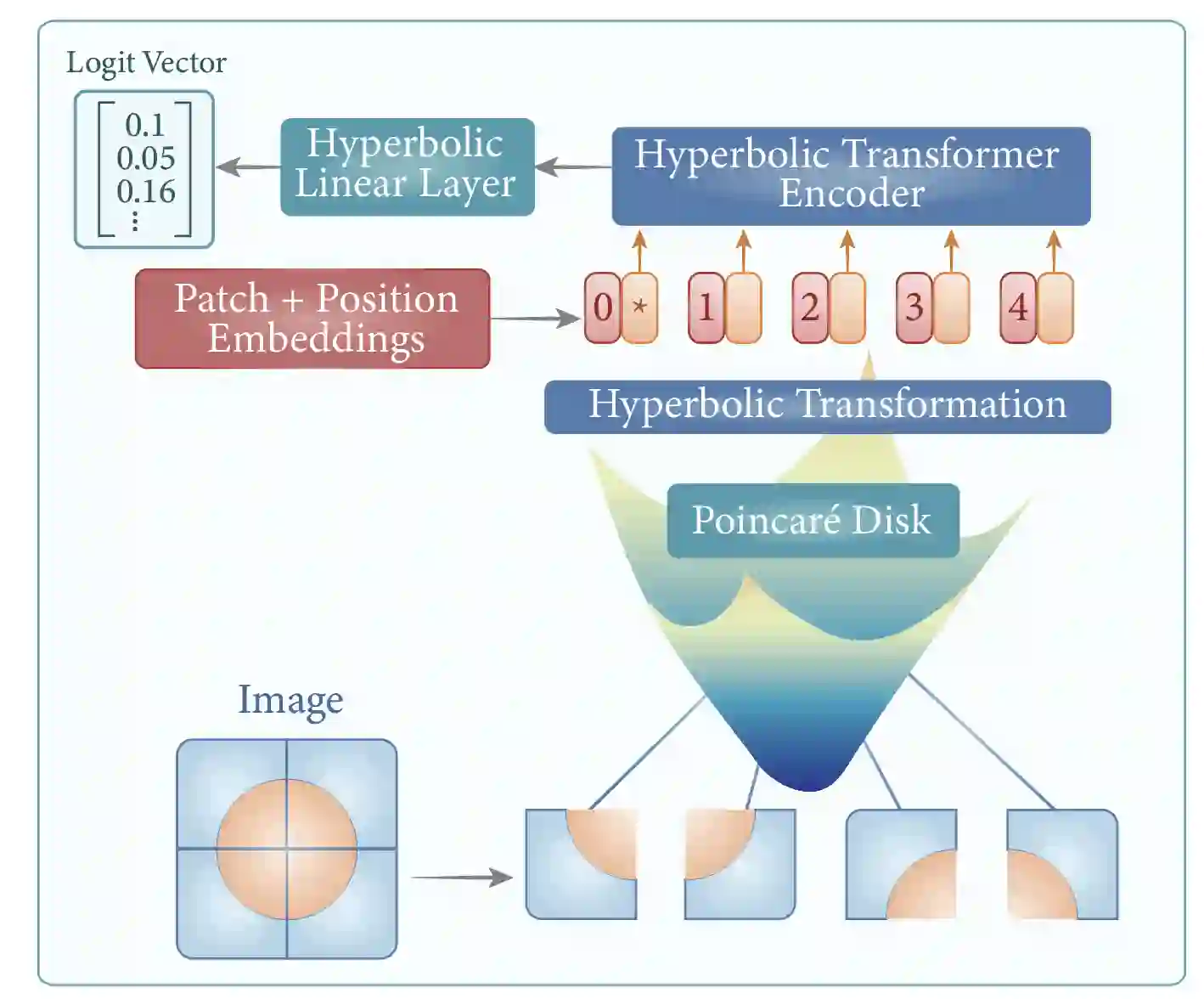
Data representation in non-Euclidean spaces has proven effective for capturing hierarchical and complex relationships in real-world datasets. Hyperbolic spaces, in particular, provide efficient embeddings for hierarchical structures. This paper introduces the Hyperbolic Vision Transformer (HVT), a novel extension of the Vision Transformer (ViT) that integrates hyperbolic geometry. While traditional ViTs operate in Euclidean space, our method enhances the self-attention mechanism by leveraging hyperbolic distance and M\"obius transformations. This enables more effective modeling of hierarchical and relational dependencies in image data. We present rigorous mathematical formulations, showing how hyperbolic geometry can be incorporated into attention layers, feed-forward networks, and optimization. We offer improved performance for image classification using the ImageNet dataset.
翻译:在非欧空间中表示数据已被证明能有效捕捉现实世界数据集中的层次化与复杂关系。双曲空间尤其为层次结构提供了高效的嵌入表示。本文提出了双曲视觉Transformer(HVT),这是视觉Transformer(ViT)的一种新颖扩展,它融合了双曲几何。传统ViT在欧氏空间中运行,而我们的方法通过利用双曲距离和Möbius变换增强了自注意力机制,从而能更有效地建模图像数据中的层次化与关系依赖。我们提出了严格的数学公式,展示了如何将双曲几何整合到注意力层、前馈网络和优化过程中。通过在ImageNet数据集上的实验,我们的方法在图像分类任务中取得了更优的性能。