
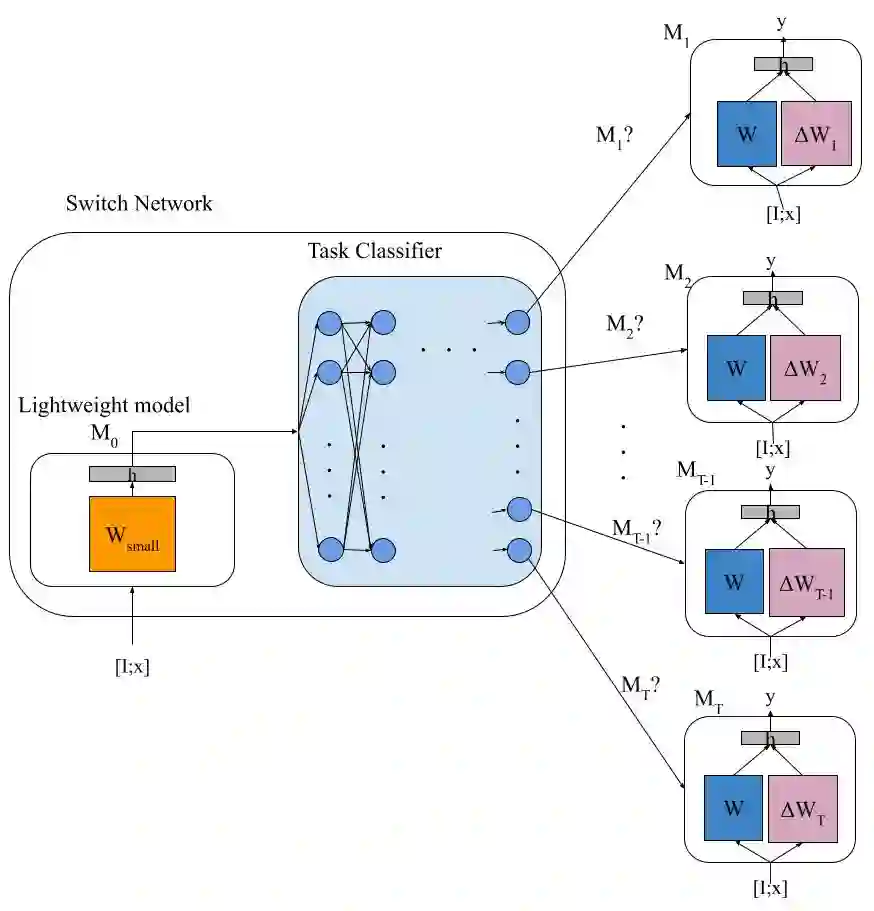
Large language models (LLMs) and multimodal models (MMs) have exhibited impressive capabilities in various domains, particularly in general language understanding and visual reasoning. However, these models, trained on massive data, may not be finely optimized for specific tasks triggered by instructions. Continual instruction tuning is crucial to adapt a large model to evolving tasks and domains, ensuring their effectiveness and relevance across a wide range of applications. In the context of continual instruction tuning, where models are sequentially trained on different tasks, catastrophic forgetting can occur, leading to performance degradation on previously learned tasks. This work addresses the catastrophic forgetting in continual instruction learning through a switching mechanism for routing computations to parameter-efficient tuned models. We demonstrate the effectiveness of our method through experiments on continual instruction tuning of different natural language generation tasks and vision-language tasks. We also showcase the advantages of our proposed method in terms of efficiency, scalability, portability, and privacy preservation.
翻译:大型语言模型(LLM)与多模态模型(MM)在诸多领域,尤其在通用语言理解与视觉推理方面,已展现出卓越的能力。然而,这些基于海量数据训练的模型,可能并未针对指令触发的特定任务进行精细优化。持续指令调优对于使大模型适应不断演化的任务与领域至关重要,可确保其在广泛应用中的有效性与相关性。在持续指令调优的场景中,模型需按顺序在不同任务上进行训练,这可能导致灾难性遗忘,从而降低模型在已学习任务上的性能。本研究通过一种切换机制,将计算路由至参数高效调优的模型,以解决持续指令学习中的灾难性遗忘问题。我们在不同自然语言生成任务与视觉-语言任务的持续指令调优实验中验证了所提方法的有效性。同时,我们展示了该方法在效率、可扩展性、可移植性及隐私保护方面的优势。
相关内容

Source: Apple - iOS 8

