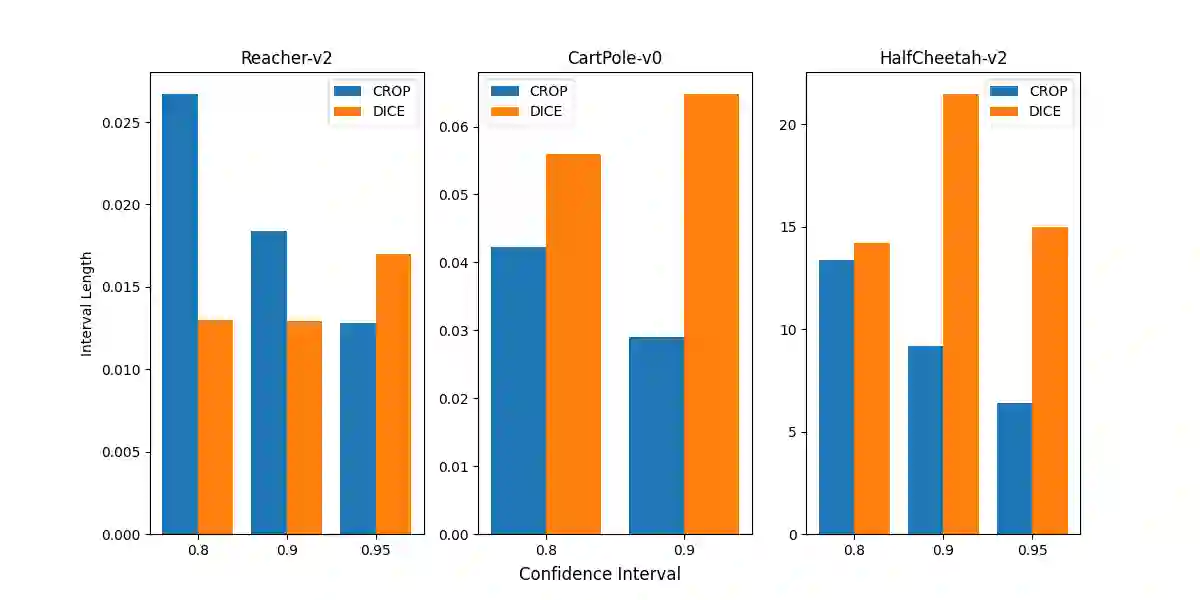
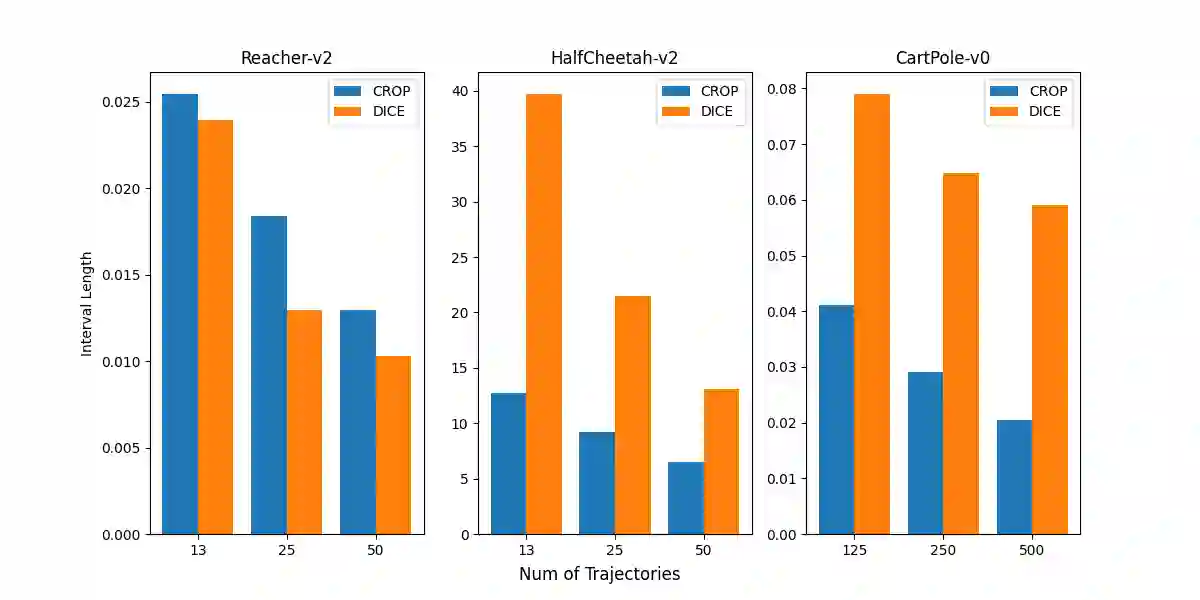
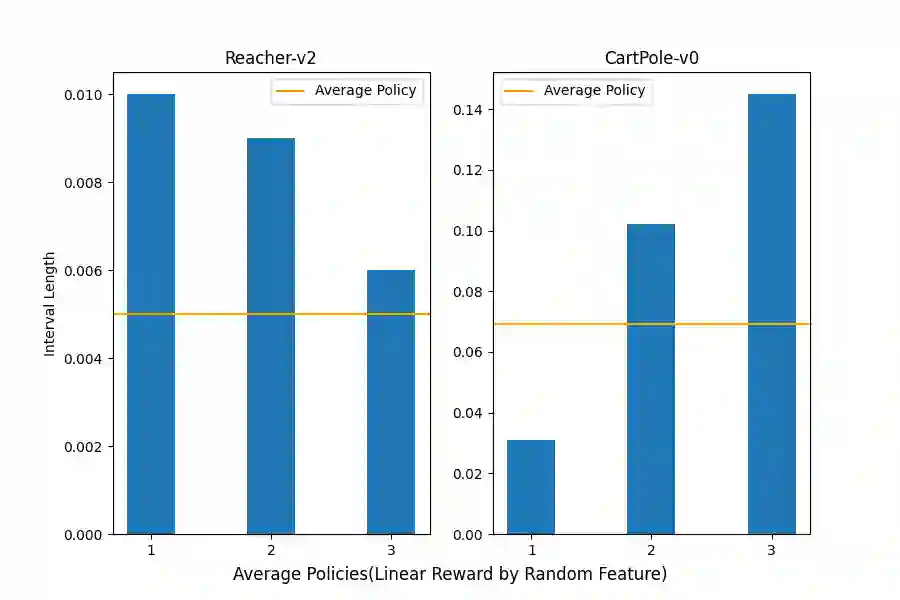
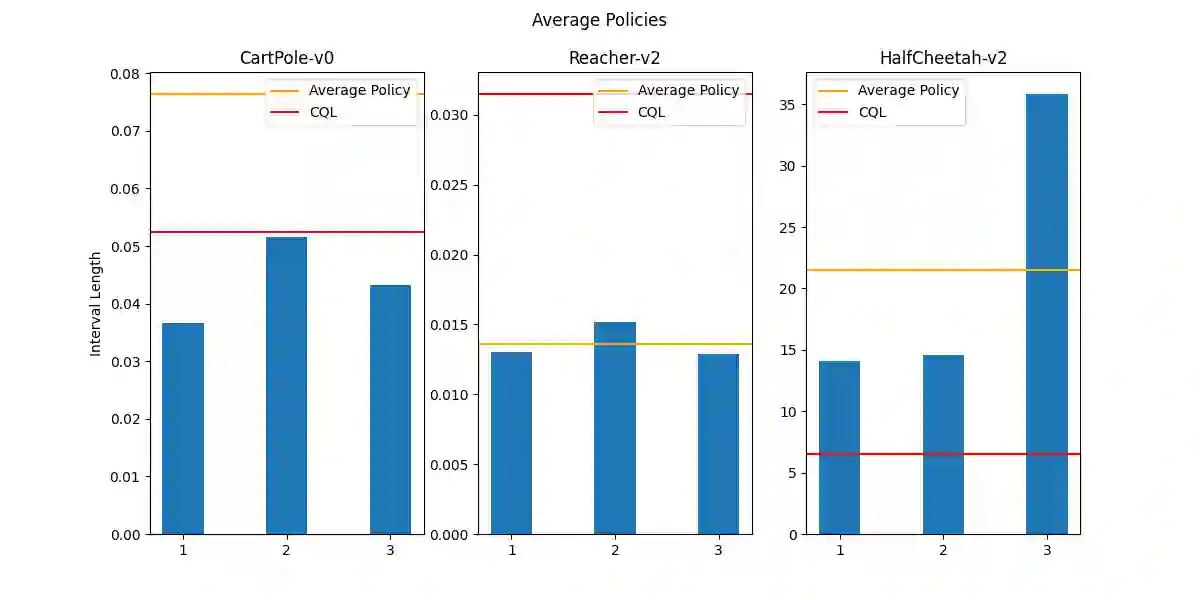
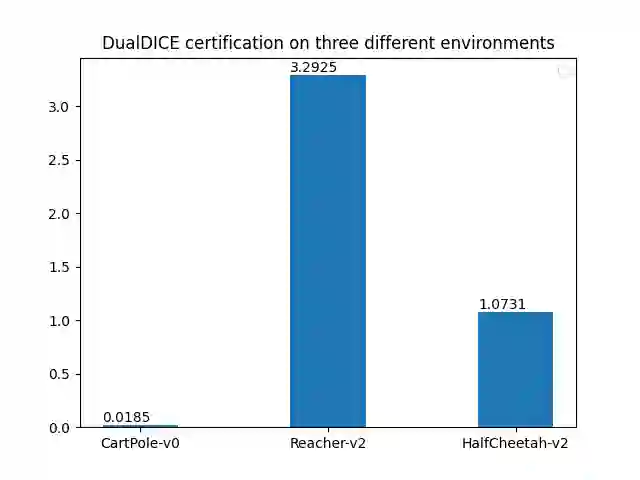
Currently, reinforcement learning (RL), especially deep RL, has received more and more attention in the research area. However, the security of RL has been an obvious problem due to the attack manners becoming mature. In order to defend against such adversarial attacks, several practical approaches are developed, such as adversarial training, data filtering, etc. However, these methods are mostly based on empirical algorithms and experiments, without rigorous theoretical analysis of the robustness of the algorithms. In this paper, we develop an algorithm to certify the robustness of a given policy offline with random smoothing, which could be proven and conducted as efficiently as ones without random smoothing. Experiments on different environments confirm the correctness of our algorithm.
翻译:当前,强化学习(尤其是深度强化学习)在研究领域受到越来越多的关注。然而,由于攻击手段日趋成熟,强化学习的安全性已成为一个突出问题。为抵御此类对抗性攻击,研究者开发了多种实用方法,如对抗训练、数据过滤等。但这些方法大多基于经验算法与实验,缺乏对算法鲁棒性的严格理论分析。本文提出一种算法,通过随机平滑离线认证给定策略的鲁棒性,该算法可被证明其有效性,且执行效率与未使用随机平滑的方法相当。在不同环境上的实验验证了我们算法的正确性。