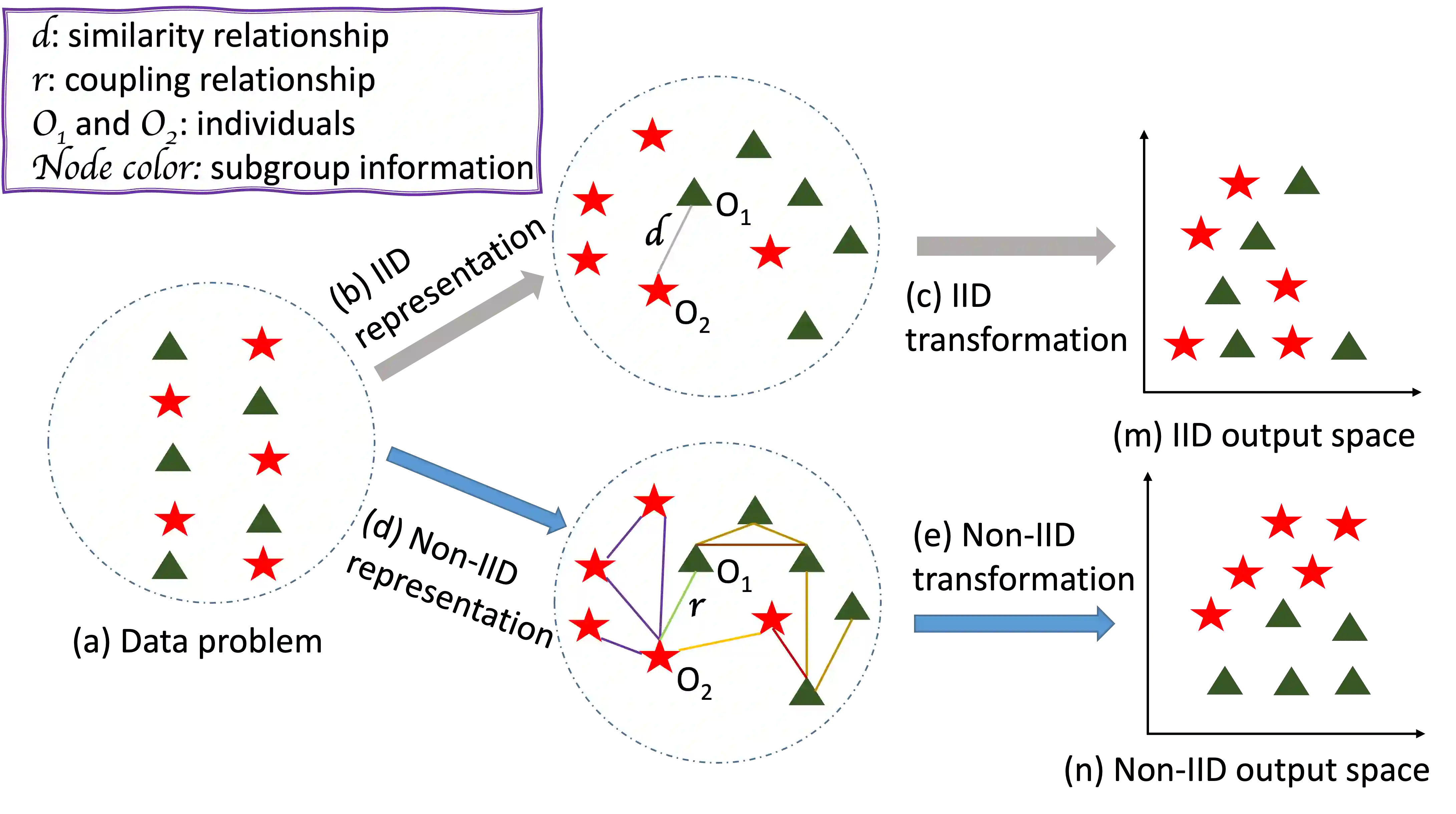
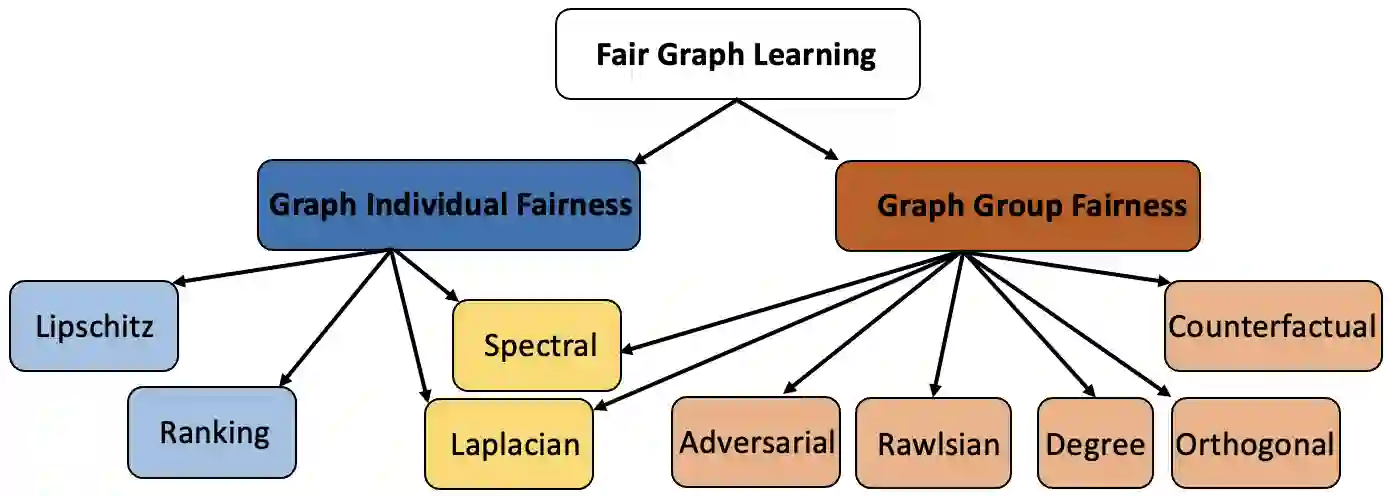
The importance of understanding and correcting algorithmic bias in machine learning (ML) has led to an increase in research on fairness in ML, which typically assumes that the underlying data is independent and identically distributed (IID). However, in reality, data is often represented using non-IID graph structures that capture connections among individual units. To address bias in ML systems, it is crucial to bridge the gap between the traditional fairness literature designed for IID data and the ubiquity of non-IID graph data. In this survey, we review such recent advance in fairness amidst non-IID graph data and identify datasets and evaluation metrics available for future research. We also point out the limitations of existing work as well as promising future directions.
翻译:理解和纠正机器学习中算法偏差的重要性,促使机器学习公平性研究日益增加。此类研究通常假设基础数据是独立同分布的。然而,现实中的数据往往通过捕捉个体间关联的非独立同分布图结构来表示。为解决机器学习系统中的偏差问题,关键是要弥合传统针对独立同分布数据设计的公平性文献与非独立同分布图数据普遍存在之间的鸿沟。本综述梳理了近期在非独立同分布图数据中实现公平性的相关进展,并指出了可供未来研究使用的数据集和评估指标。同时,我们亦指出现有工作的局限性以及具有前景的未来研究方向。