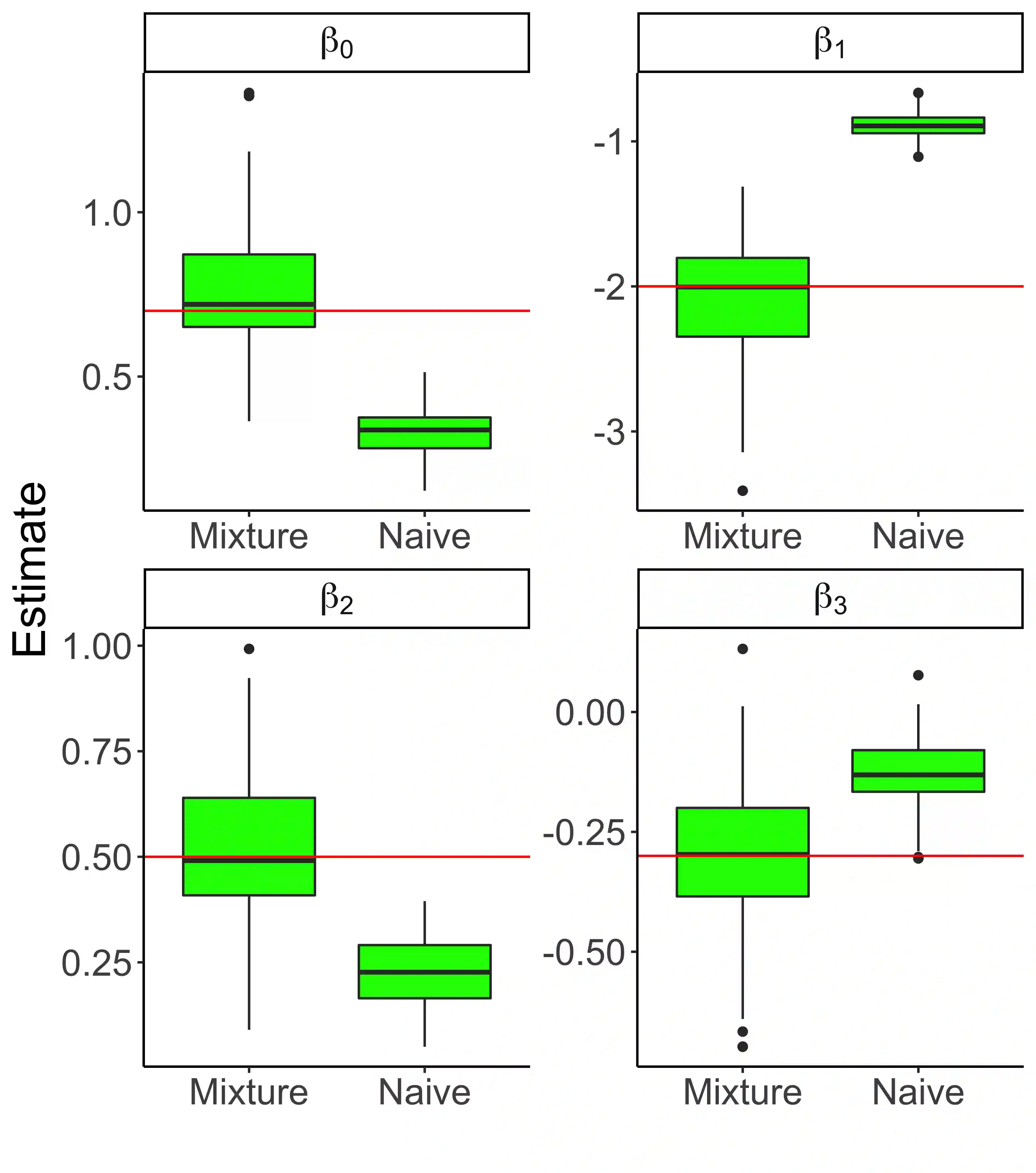
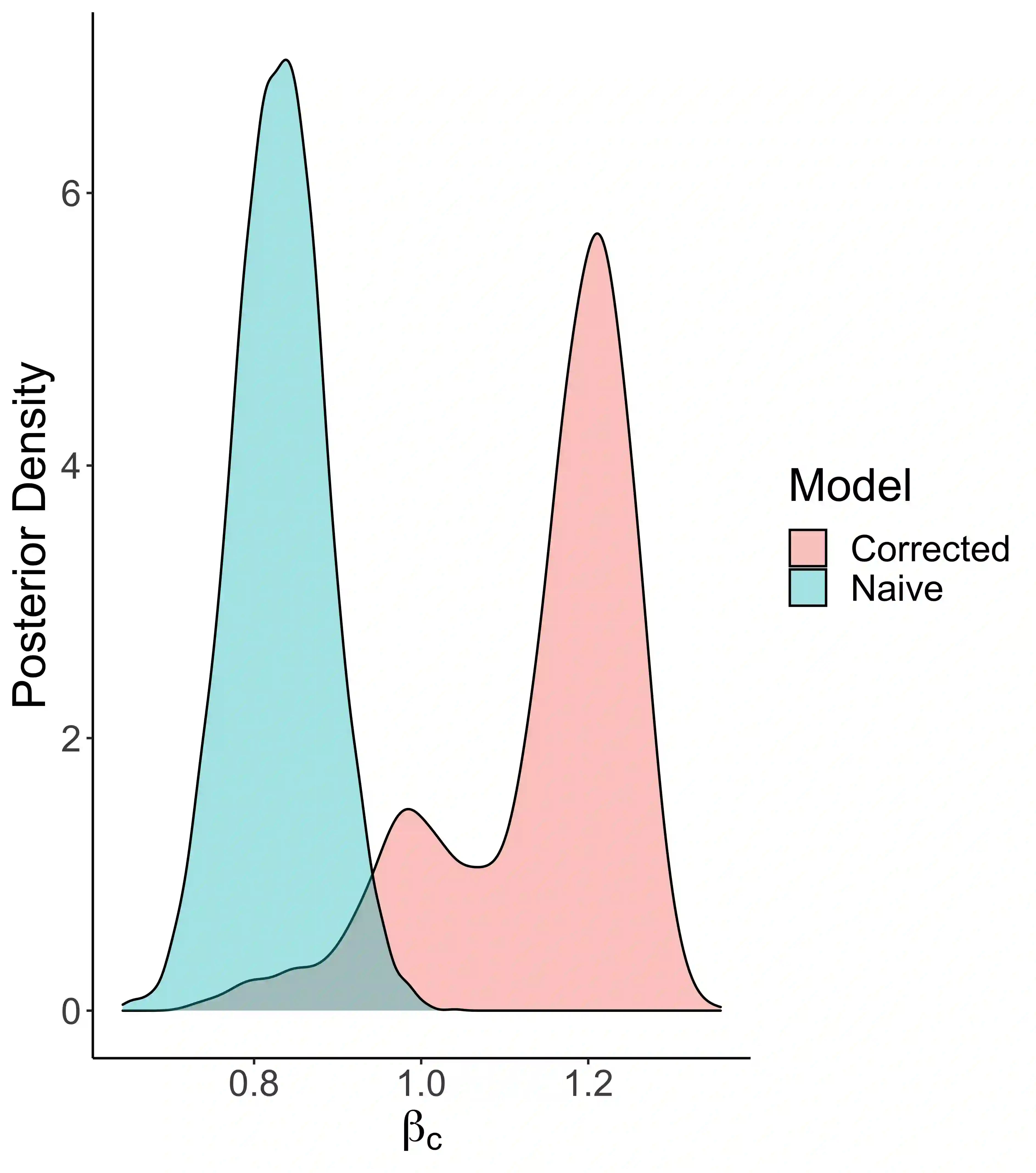
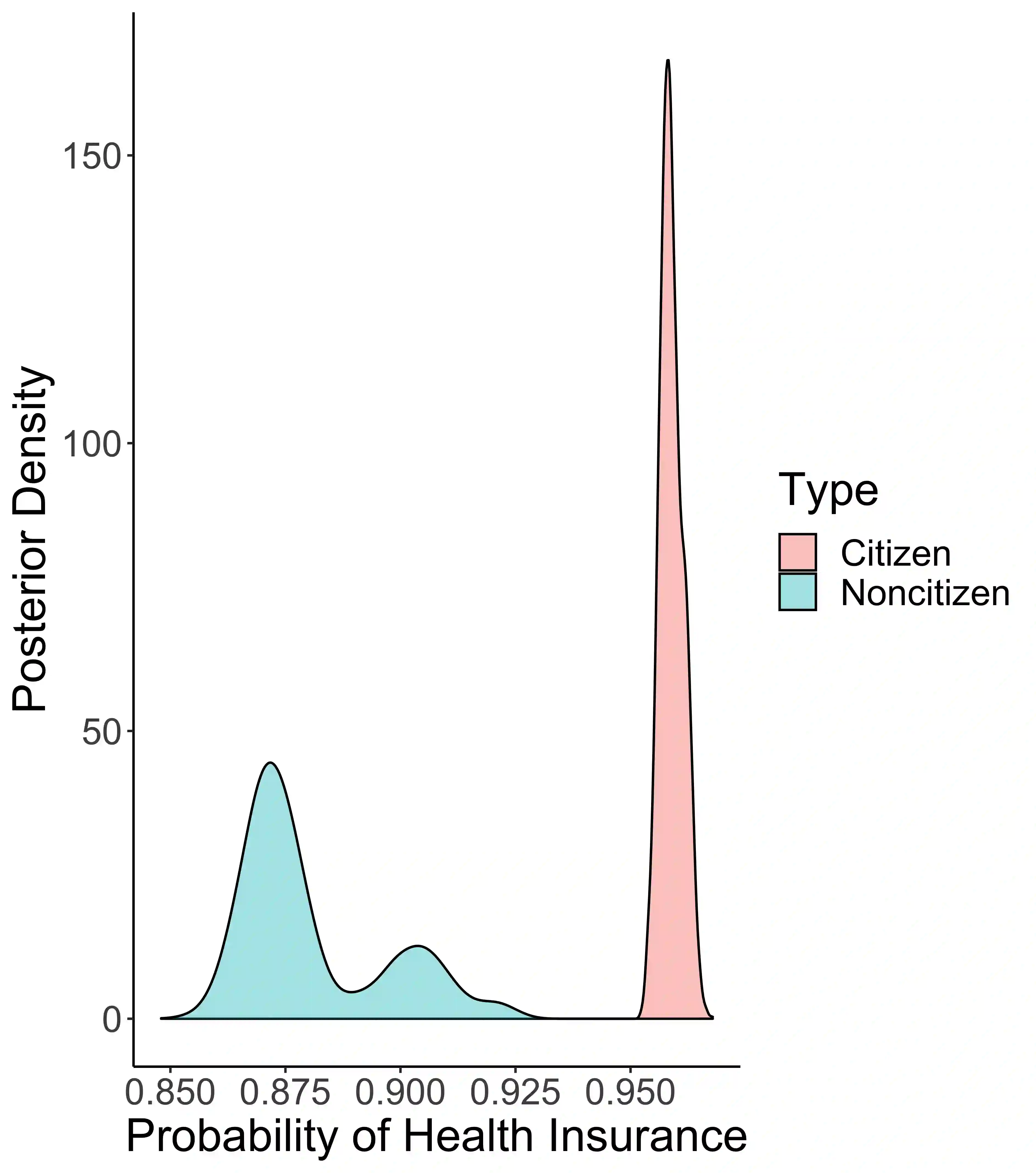
Social scientists are interested in studying the impact that citizenship status has on health insurance coverage among immigrants in the United States. This can be done using data from the Survey of Income and Program Participation (SIPP); however, two primary challenges emerge. First, statistical models must account for the survey design in some fashion to reduce the risk of bias due to informative sampling. Second, it has been observed that survey respondents misreport citizenship status at nontrivial rates. This too can induce bias within a statistical model. Thus, we propose the use of a weighted pseudo-likelihood mixture of categorical distributions, where the mixture component is determined by the latent true response variable, in order to model the misreported data. We illustrate through an empirical simulation study that this approach can mitigate the two sources of bias attributable to the sample design and misreporting. Importantly, our misreporting model can be further used as a component in a deeper hierarchical model. With this in mind, we conduct an analysis of the relationship between health insurance coverage and citizenship status using data from the SIPP.
翻译:社会科学家关注美国移民的公民身份状态对其健康保险覆盖的影响。这一问题可通过《收入与项目参与调查》(SIPP)数据进行研究,但存在两大挑战:首先,统计模型需适当考虑调查设计,以降低信息性抽样带来的偏倚风险;其次,调查对象以显著比例误报公民身份的现象已被证实,这同样会导致统计模型产生偏倚。为此,我们提出采用分类分布的加权伪似然混合模型(其中混合成分由潜在真实响应变量决定)对误报数据进行建模。通过实证模拟研究证明,该方法可有效缓解由样本设计和误报产生的两类偏倚。重要的是,该误报模型可进一步作为深层分层模型的组成部分。基于此,我们利用SIPP数据对健康保险覆盖与公民身份的关系进行了实证分析。