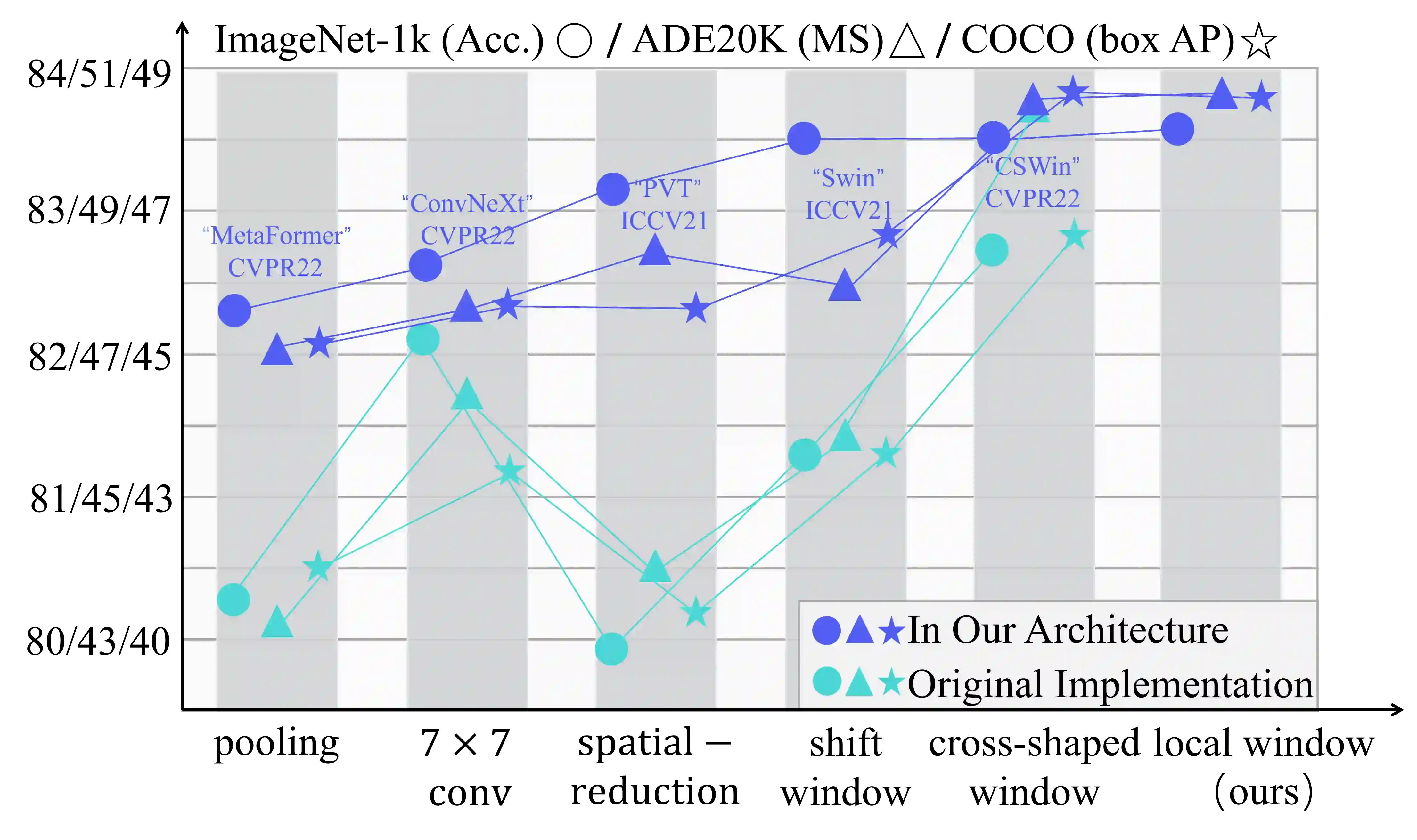
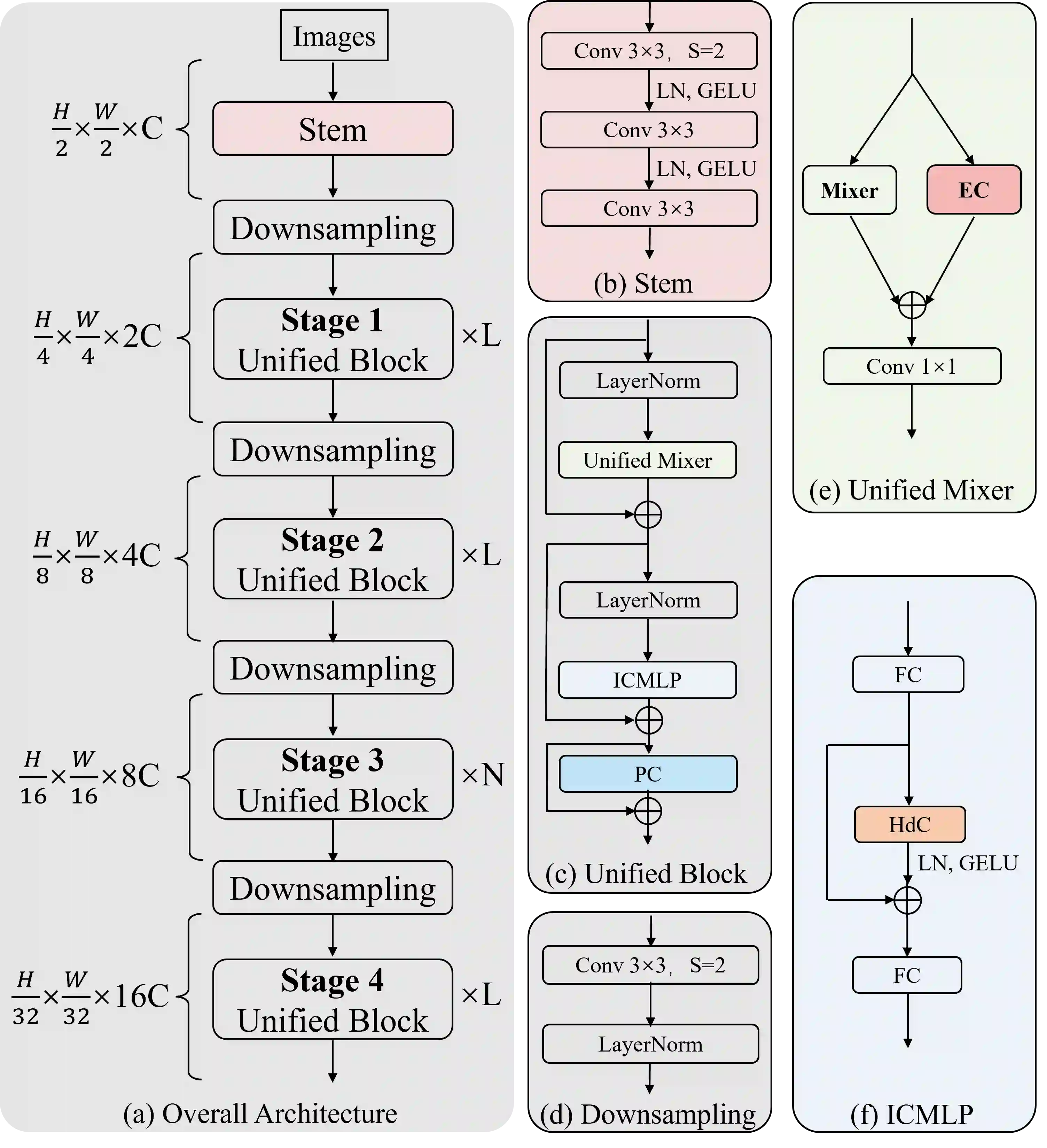
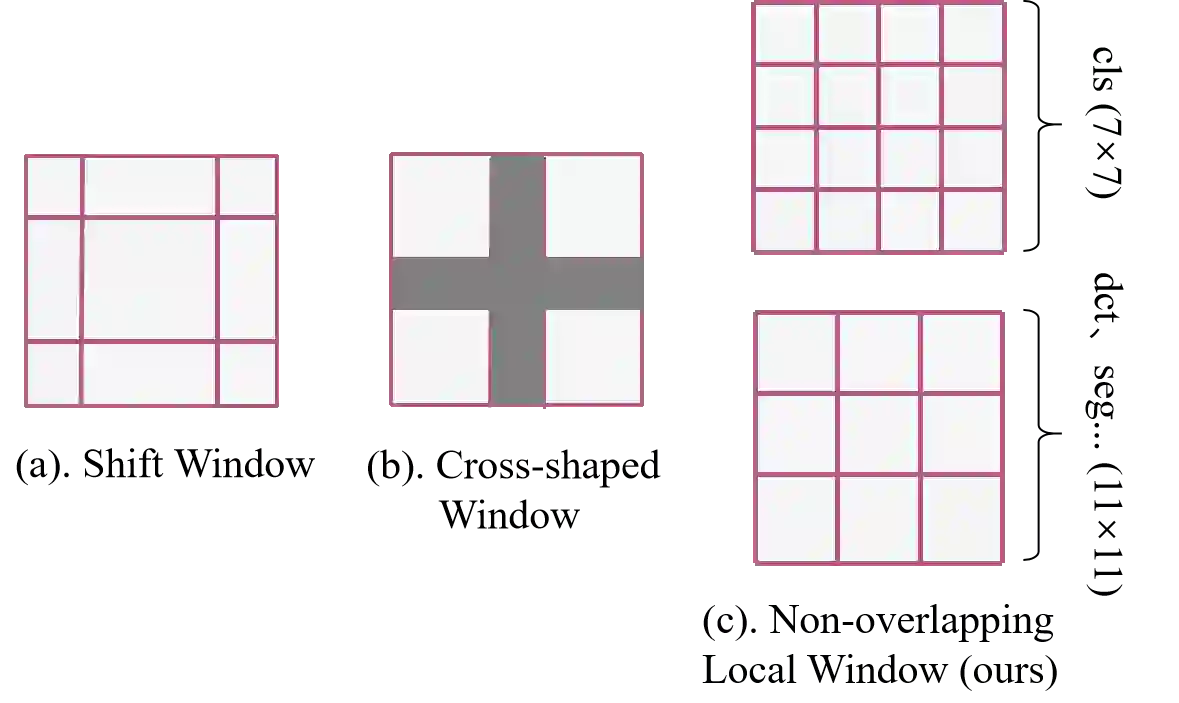
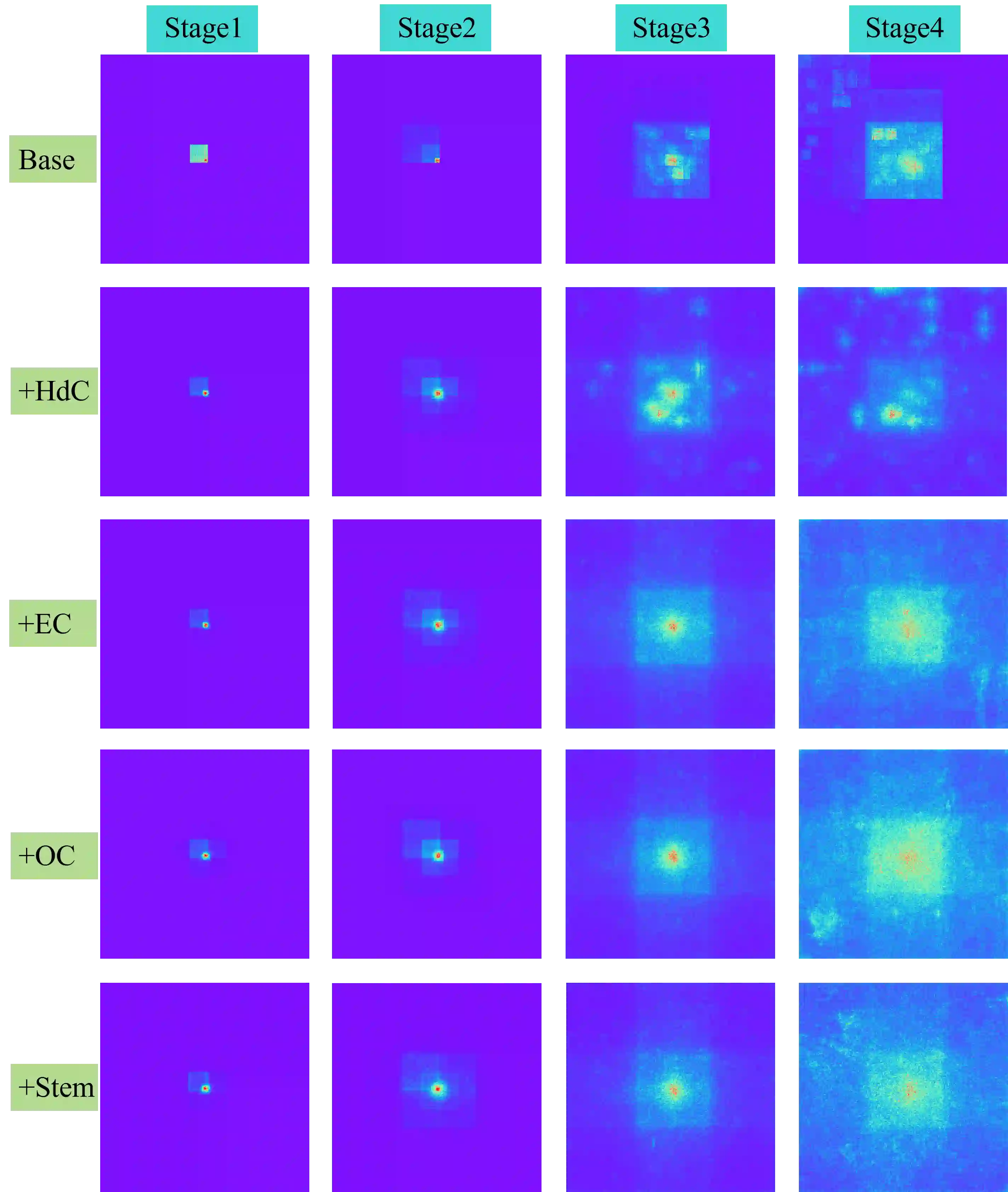
Vision Transformers have shown great potential in computer vision tasks. Most recent works have focused on elaborating the spatial token mixer for performance gains. However, we observe that a well-designed general architecture can significantly improve the performance of the entire backbone, regardless of which spatial token mixer is equipped. In this paper, we propose UniNeXt, an improved general architecture for the vision backbone. To verify its effectiveness, we instantiate the spatial token mixer with various typical and modern designs, including both convolution and attention modules. Compared with the architecture in which they are first proposed, our UniNeXt architecture can steadily boost the performance of all the spatial token mixers, and narrows the performance gap among them. Surprisingly, our UniNeXt equipped with naive local window attention even outperforms the previous state-of-the-art. Interestingly, the ranking of these spatial token mixers also changes under our UniNeXt, suggesting that an excellent spatial token mixer may be stifled due to a suboptimal general architecture, which further shows the importance of the study on the general architecture of vision backbone. All models and codes will be publicly available.
翻译:视觉Transformer在计算机视觉任务中展现出巨大潜力。近期多数研究聚焦于精心设计空间令牌混合器以提升性能。然而,我们观察到无论配备何种空间令牌混合器,精心设计的通用架构均可显著提升整个骨干网络的性能。本文提出UniNeXt——一种改进的视觉骨干通用架构。为验证其有效性,我们采用多种典型与现代设计(包括卷积与注意力模块)实例化空间令牌混合器。相较于这些混合器首次提出时的架构,我们的UniNeXt架构能稳定提升所有空间令牌混合器的性能,并缩小它们之间的性能差距。令人惊讶的是,配备朴素局部窗口注意力的UniNeXt甚至超越了此前最先进方法。有趣的是,在UniNeXt架构下,这些空间令牌混合器的性能排序也发生变化,这表明由于次优的通用架构,优秀空间令牌混合器的潜力可能被抑制,进一步凸显了视觉骨干通用架构研究的重要性。所有模型与代码将开源发布。