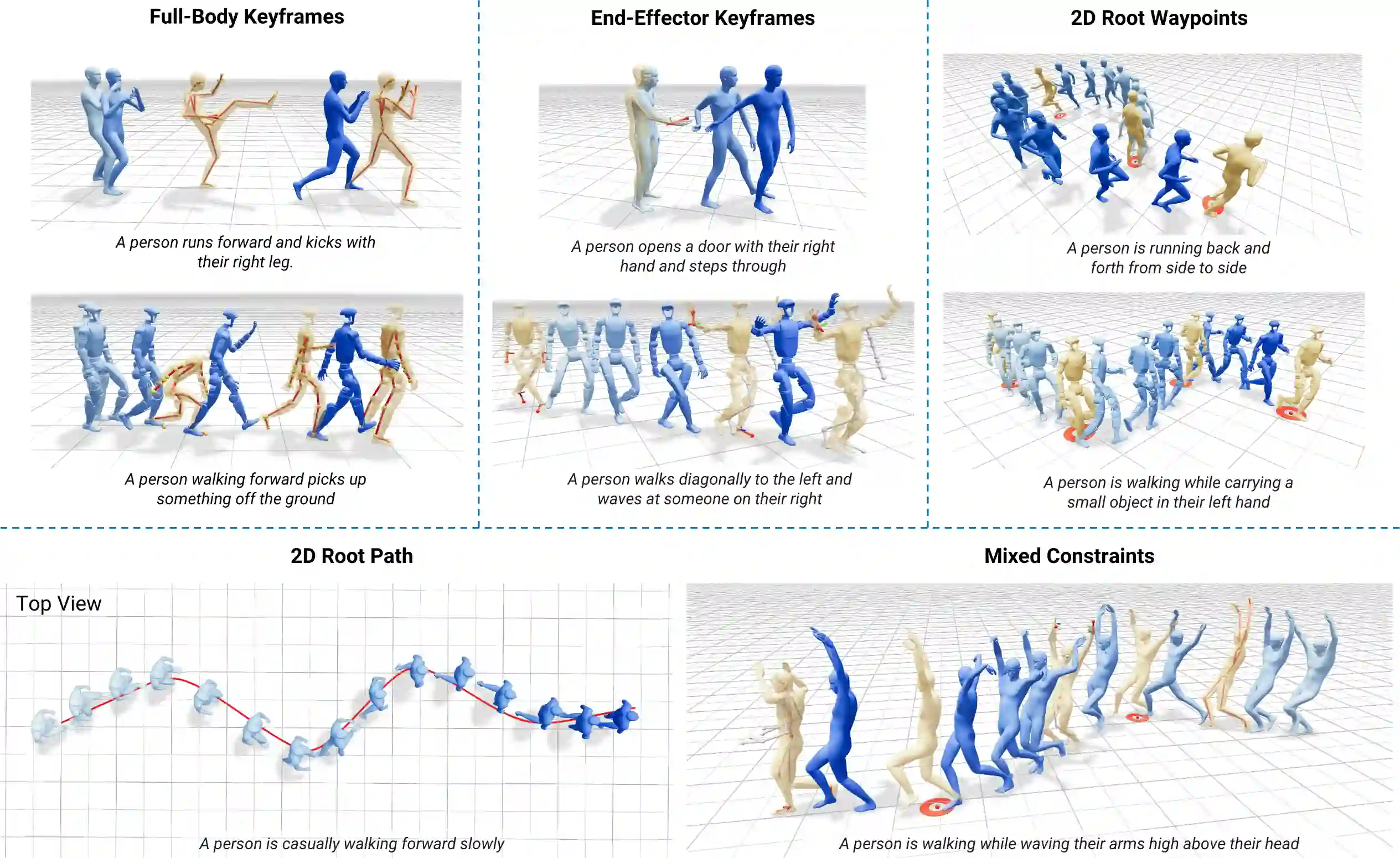
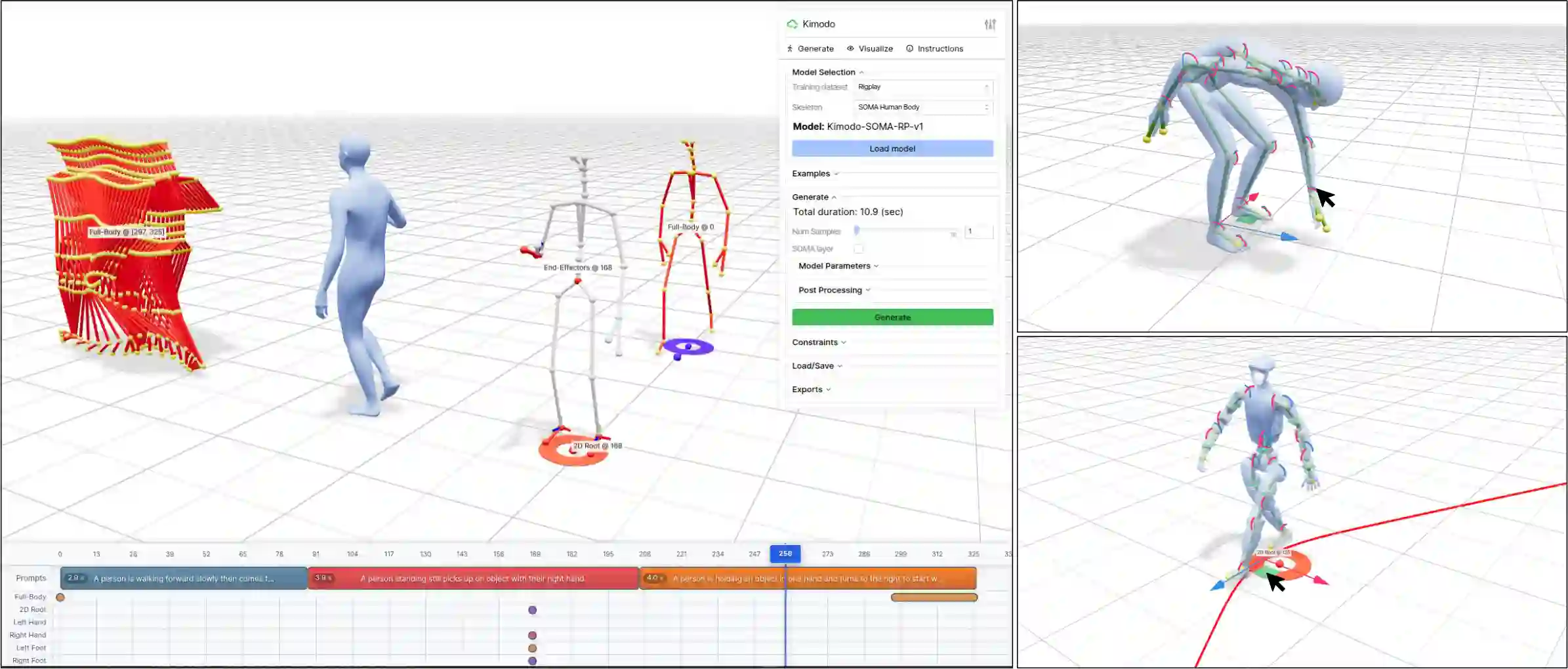
High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
翻译:高质量的人体运动数据对于机器人学、仿真和娱乐领域的应用正变得日益重要。近期的生成模型提供了一个潜在的数据源,能够通过文本提示或姿态上的运动学约束等直观输入来合成人体运动。然而,公共动作捕捉数据集规模较小,限制了这些模型的运动质量、控制精度和泛化能力。在本工作中,我们提出了Kimodo,这是一个基于700小时光学动作捕捉数据训练的表达能力强且可控的运动学运动扩散模型。我们的模型能够生成高质量的运动,同时易于通过文本以及一套全面的运动学约束进行控制,这些约束包括全身关键帧、稀疏关节位置/旋转、二维路径点以及密集二维路径。这得益于精心设计的运动表示和两阶段去噪器架构,该架构将根节点和身体预测分解,以最小化运动伪影,同时允许灵活的约束条件设置。在大规模动作捕捉数据集上的实验验证了关键设计决策,并分析了数据集规模和模型规模如何影响性能。