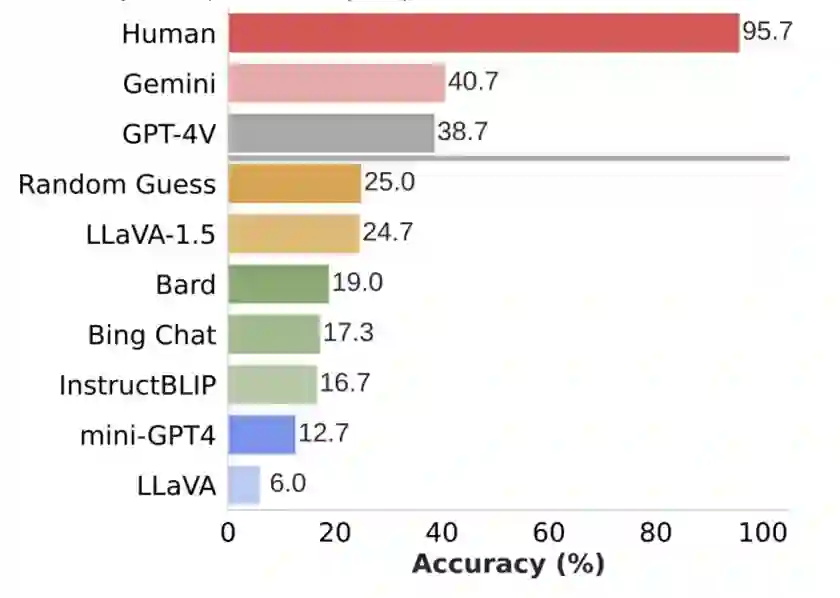
We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
翻译:我们提出SPHINX-X,这是一系列基于SPHINX构建的多模态大语言模型(MLLM)。为提升架构与训练效率,我们改进了SPHINX框架:去除冗余视觉编码器,通过跳跃令牌绕过全填充子图像,并将多阶段训练简化为一体化单阶段范式。为充分释放MLLM潜力,我们整合了涵盖语言、视觉及视觉-语言任务的公开资源,构建了全面的多领域多模态数据集。此外,通过我们精心标注的OCR密集型数据集和Set-of-Mark数据集进一步丰富了该集合,提升了数据多样性与通用性。通过在不同基础大语言模型(包括TinyLlama1.1B、InternLM2-7B、LLaMA2-13B和Mixtral8x7B)上进行训练,我们获得了一系列参数规模和多语言能力各异的MLLM。综合基准测试揭示了多模态性能与数据及参数规模之间的强相关性。代码与模型已发布至https://github.com/Alpha-VLLM/LLaMA2-Accessory。