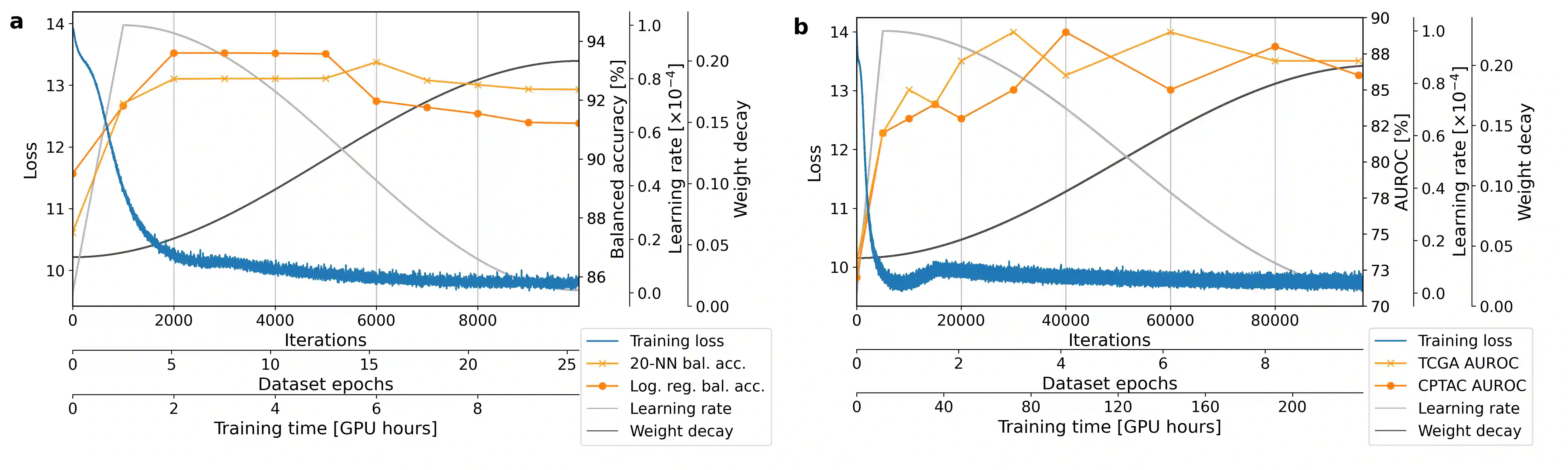
To handle the large scale of whole slide images in computational pathology, most approaches first tessellate the images into smaller patches, extract features from these patches, and finally aggregate the feature vectors with weakly-supervised learning. The performance of this workflow strongly depends on the quality of the extracted features. Recently, foundation models in computer vision showed that leveraging huge amounts of data through supervised or self-supervised learning improves feature quality and generalizability for a variety of tasks. In this study, we benchmark the most popular vision foundation models as feature extractors for histopathology data. We evaluate the models in two settings: slide-level classification and patch-level classification. We show that foundation models are a strong baseline. Our experiments demonstrate that by finetuning a foundation model on a single GPU for only two hours or three days depending on the dataset, we can match or outperform state-of-the-art feature extractors for computational pathology. These findings imply that even with little resources one can finetune a feature extractor tailored towards a specific downstream task and dataset. This is a considerable shift from the current state, where only few institutions with large amounts of resources and datasets are able to train a feature extractor. We publish all code used for training and evaluation as well as the finetuned models.
翻译:为应对计算病理学中全切片图像的大规模处理需求,多数方法首先将图像分割为更小的补丁,从这些补丁中提取特征,最后通过弱监督学习对特征向量进行聚合。该流程的性能高度依赖于所提取特征的质量。近年来,计算机视觉领域的基础模型表明,通过监督或自监督学习利用海量数据可提升特征质量及对多种任务的泛化能力。本研究以最流行的视觉基础模型作为组织病理学数据的特征提取器进行基准测试,在切片级分类与补丁级分类两种设置下评估模型性能。研究表明基础模型是强有力的基线。实验证明,根据数据集不同,在单个GPU上对基础模型进行仅两小时或三天的微调,即可匹配或超越计算病理学领域现有最优特征提取器的性能。这些发现意味着即使资源有限,也可针对特定下游任务与数据集微调特征提取器。这与当前仅有少数拥有大量资源和数据集的机构才能训练特征提取器的现状形成显著转变。我们公开发布了所有用于训练与评估的代码及微调后的模型。