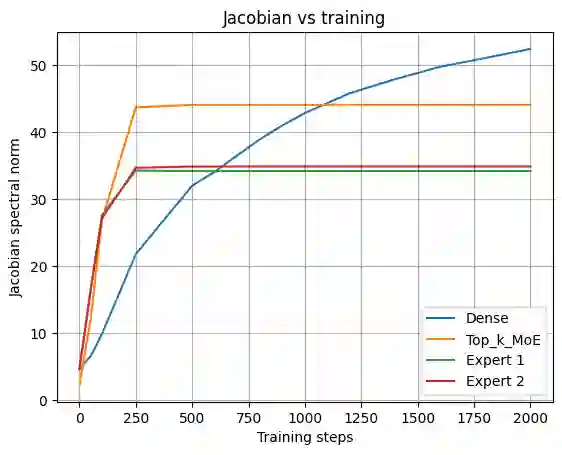
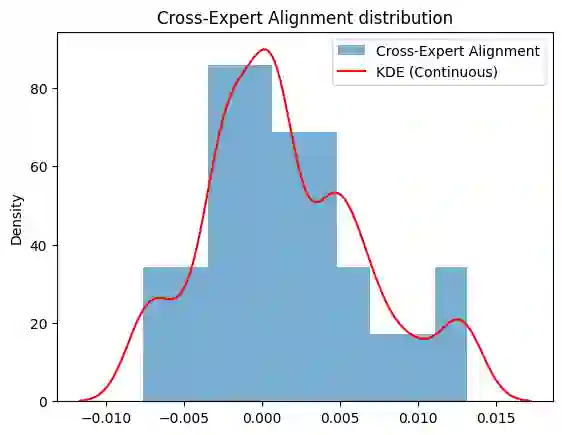
Mixture-of-Experts (MoE) architectures are widely used for efficiency and conditional computation, but their effect on the geometry of learned functions and representations remains poorly understood. We study MoEs through a geometric lens, interpreting routing as soft partitioning into overlapping expert-local charts. We introduce a Dual Jacobian-PCA spectral probe that analyzes local function geometry via Jacobian singular value spectra and representation geometry via weighted PCA of routed hidden states. Using a controlled MLP-MoE setting with exact Jacobian computation, we compare dense, Top-k, and fully soft routing under matched capacity. Across random seeds, MoE routing consistently reduces local sensitivity: expert-local Jacobians show smaller leading singular values and faster spectral decay than dense baselines. Weighted PCA reveals that expert-local representations distribute variance across more principal directions, indicating higher effective rank. We further observe low alignment among expert Jacobians, suggesting decomposition into low-overlap expert-specific transformations. Routing sharpness modulates these effects: Top-k routing yields more concentrated, lower-rank expert structure, while fully soft routing produces broader, higher-rank representations. Experiments on a 3-layer transformer with WikiText confirm curvature reduction on natural language and show lower cross-expert alignment for Top-k routing. These findings support interpreting MoEs as soft partitionings of function space that flatten local curvature while redistributing representation variance, yielding testable predictions for expert scaling, hallucination reduction, and ensemble diversity.
翻译:混合专家(MoE)架构因其高效性和条件计算能力而被广泛采用,但其对学习到的函数与表示几何结构的影响仍不甚明晰。本文从几何视角研究MoE模型,将路由机制解释为向重叠的专家局部坐标图的软划分。我们提出一种双雅可比-PCA谱探测方法:通过雅可比矩阵奇异值谱分析局部函数几何,同时通过对路由隐藏状态的加权PCA分析表示几何。在具备精确雅可比计算能力的可控MLP-MoE实验环境中,我们在等效容量下比较稠密路由、Top-k路由与完全软路由。跨随机种子的实验表明,MoE路由持续降低局部敏感性:相较于稠密基线,专家局部雅可比矩阵呈现更小的主导奇异值与更快的谱衰减。加权PCA显示专家局部表示将方差分布至更多主方向,表明其具有更高的有效秩。我们进一步观察到专家雅可比矩阵间对齐度较低,暗示其分解为重叠度低的专家特定变换。路由锐度调节这些效应:Top-k路由产生更集中、更低秩的专家结构,而完全软路由则生成更宽泛、更高秩的表示。在WikiText数据上对三层Transformer的实验证实了自然语言处理中曲率的降低,并显示Top-k路由具有更低的跨专家对齐度。这些发现支持将MoE解释为函数空间的软划分机制,其在平坦化局部曲率的同时重新分配表示方差,从而为专家扩展、幻觉抑制与集成多样性提供了可验证的预测。