摘要: 稀疏混合专家模型 (MoE) 架构已演进为一种强大的方法,能够在保持计算成本基本不变的情况下,显著提升深度学习模型的参数规模。作为大语言模型 (LLM) 的一个重要分支,MoE 模型根据路由网络仅激活专家的子集。这种稀疏条件计算机制大幅提高了计算效率,为实现更高的可扩展性和成本效益铺平了道路。该技术不仅增强了自然语言处理、计算机视觉和多模态等多个水平领域的下游应用,还在医疗诊断、自动驾驶、金融分析和商业智能等垂直领域展现出广泛的适用性。尽管 MoE 模型在各领域的关注度和应用日益增加,但目前仍缺乏对其在诸多重要领域最新进展的系统性探究。现有的 MoE 综述存在覆盖范围不足或对关键领域探索不够深入等局限。 本综述旨在填补这些空白。首先,我们审视了 MoE 的基础原理,深入探讨了其核心组件——路由网络与专家网络。随后,我们将视野从中心化范式扩展至去中心化范式。去中心化范式释放了去中心化基础设施中巨大的未开发潜力,使 MoE 开发的“民主化”成为可能,从而惠及更广泛的社区,并提供更强的可扩展性与成本效益。此外,我们重点探讨了其在垂直领域的应用。最后,我们识别了当前面临的关键挑战及具有前景的未来研究方向。据我们所知,本综述是目前 MoE 领域内最详尽的综述。我们希望本文能为研究人员和从业者提供宝贵的资源,帮助其洞察并跟进该领域的最新进展。 关键词: 混合专家模型 (MoE)、去中心化学习、大语言模型 (LLM)、Transformer 架构 作为您的学术翻译专家,我将针对该引言部分进行深度翻译。这一部分确立了论文的研究背景、动机以及核心贡献,语言风格需兼具叙述的流畅性与理论的严谨性。
第一步:术语提取与逻辑分析
Scaling Law: 扩展定律(指模型性能随规模增加而提升的规律)。 * Foundation models: 基础模型 / 基座模型。 * Sparsely-gated MoE: 稀疏门控 MoE。 * Closed-source / Open-source alternatives: 闭源模型 / 开源替代方案。 * Centralized / Decentralized paradigm: 中心化 / 去中心化范式。 * Democratization: 民主化(降低技术准入门槛)。 * Vertical industries / domains: 垂直行业 / 领域。 * Resource-limited: 资源受限的。
逻辑梳理: 1. 背景:Scaling Law 驱动了 AI 进步,但带来了高昂的计算成本。 1. 机遇:MoE 架构通过稀疏激活平衡了规模与成本,并提升了可解释性。 1. 挑战:超大规模 MoE 对资源的要求导致了“准垄断”现象,制约了创新。 1. 对策:提出从中心化向去中心化范式转型,利用异构资源实现开发民主化。 1. 综述价值:填补现有研究在去中心化和垂直领域应用方面的空白。
第二步:润色翻译(终稿)
1 引言
人工智能 (AI) 近期的进展,尤其是大语言模型 (LLM) 的突破,主要源于扩展定律 (Scaling Law) [2,10,42]:即更大的模型规模能带来更高的模型质量。尽管这一基本原理被认为过于简化,但它持续引领着 AI 研究的演进。然而,极端规模的模型扩张也导致了极高的计算成本。 为此,基于稀疏混合专家模型 (MoE) [15,19,23,46,84,129] 的架构开辟了一条充满前景的路径,使得基础模型能够在保持相当计算成本的前提下,扩展至更大的规模。近期,一种将稀疏门控 MoE 与 Transformer 基座模型 [76,97] 相结合的开源 MoE 模型 [54] 已超越了其他开源替代方案,并展现出与 GPT-4o [34] 等主流闭源模型相当的性能。这标志着这项拥有三十年历史的技术 [36] 释放出了更广泛的应用潜力。 除了效率优势外,MoE 架构还为增强模型的可解释性提供了契机 [5,45,66,70,129]。通过学习其内在的分配机制,研究人员可以深入了解不同“专家”如何专门处理特定类型的数据或任务。这种可解释性不仅加深了我们对模型行为的理解,也为设计更稳健、更透明的 AI 系统铺平了道路。 然而,近期一些 MoE 模型 [92,116] 的参数量已扩展至 1 万亿 (1T),上下文窗口超过 12.8 万个标记 (128K tokens),这急剧增加了对计算资源的需求。这种指数级增长带来了严峻挑战:昂贵的高性能计算集群使资源受限的个人研究者和小型实验室对前沿 MoE 研发望而却步。仅有少数大型企业和机构拥有开发此类模型的充足资源,形成了抑制 AI 创新的“准垄断”局面。为了实现可持续的规模扩展,迫切需要采用高效的训练和推理范式。目前的先进框架 [25,35,69,77,115,127] 主要利用有限的同构资源,并在中心化范式下运行。至关重要的是,去中心化集群和消费级设备通常拥有远超中心化集群的计算资源总量。尽管蕴含着巨大的未开发潜力,但这些资源由于带宽较低且单体算力较弱,通常被忽视。去中心化范式 [60,82] 作为一个极具前景的解决方案应运而生。这种分布式范式整合了个人消费级 GPU 及集群中的异构资源,充分利用计算能力,实现了 MoE 开发面向更广泛社区的“民主化”,并提供了更高的可扩展性和成本效益。
**1.1 相关工作
虽然此前已有几篇相关的综述,但仍存在显著空白。例如,在综合性研究中,[122] 仅涵盖了深度学习之前的进展,[22] 忽略了该领域的最新突破,[11,65] 缺乏对去中心化 MoE 范式的覆盖,且目前尚无研究深入探讨 MoE 在垂直行业的应用。此外,一些针对性研究如 [26] 侧重于大数据应用,[55] 侧重于推理加速,[114] 则侧重于无线通信场景的应用。本综述通过深入探讨中心化与去中心化基础设施下的 MoE 架构,以及关键垂直领域中的特定场景应用,填补了上述空白。表 1 总结了这些差异。
**1.2 核心贡献
全面且及时的综述:我们对 MoE 领域进行了最详尽的回顾,系统性地梳理了从算法基础到去中心化架构及垂直领域应用的相关研究。本综述细致地分析了相关研究的动机、技术原理及关键因素,为研究人员和从业者提供了追踪最新进展并激发新思路的宝贵参考。 * 深度探索去中心化架构范式:我们深入探讨了去中心化范式,揭示了去中心化基础设施中未开发的巨大潜力。本综述勾勒了该范式面临的关键挑战,并回顾了应对这些问题的现有研究。这标志着模型开发从传统的中心化范式向“民主化”转型,推动 MoE 的发展从“资源竞争”演进为“按需扩展”。 * 多样化的垂直领域应用:我们广泛探索了 MoE 在典型垂直领域中的应用,提供了关于 MoE 如何应用于特定任务的整体视角。
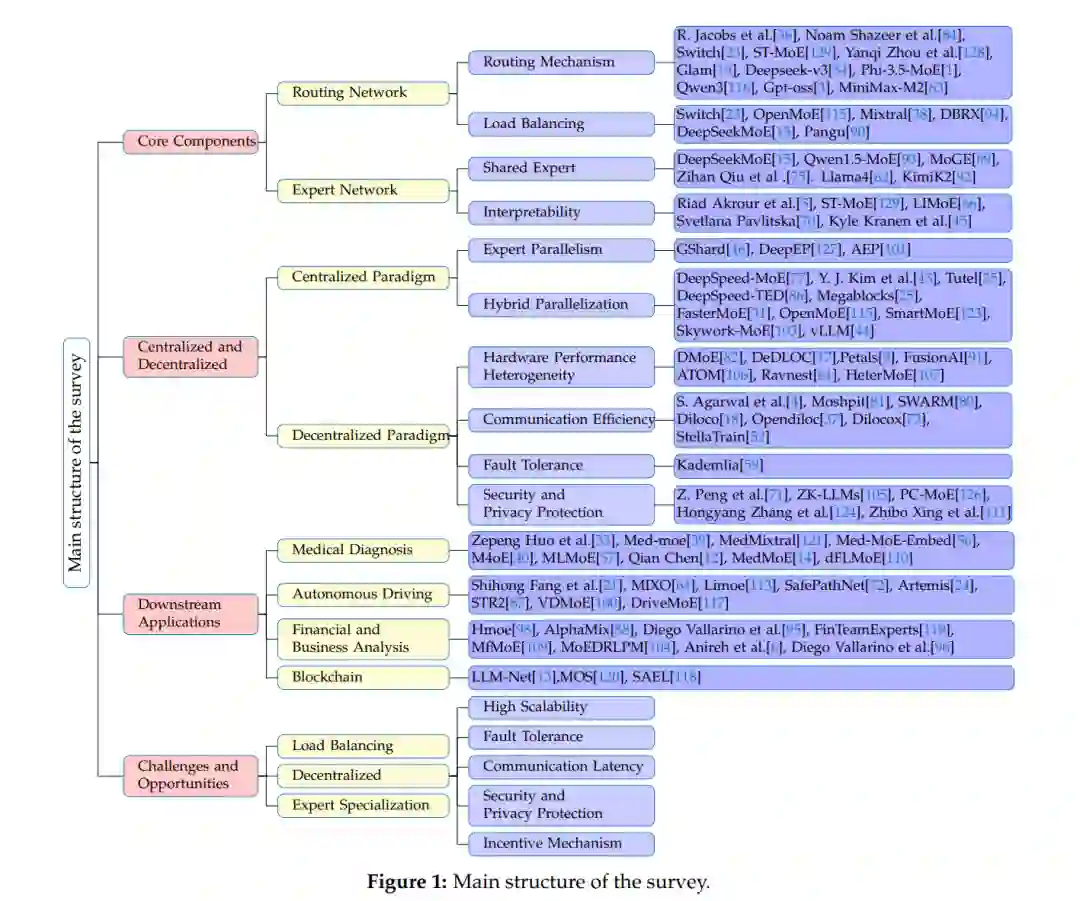
本文后续组织结构如下:第 2 节全面介绍稀疏 MoE 模型的核心组件设计;第 3 节超越中心化范式,探讨异构环境下的去中心化范式;第 4 节将焦点从广泛研究的水平应用(如 NLP、CV、多模态)转向垂直行业应用(如医疗、自动驾驶、金融等);第 5 节分析关键挑战与新兴机遇;第 6 节对全文进行总结。