

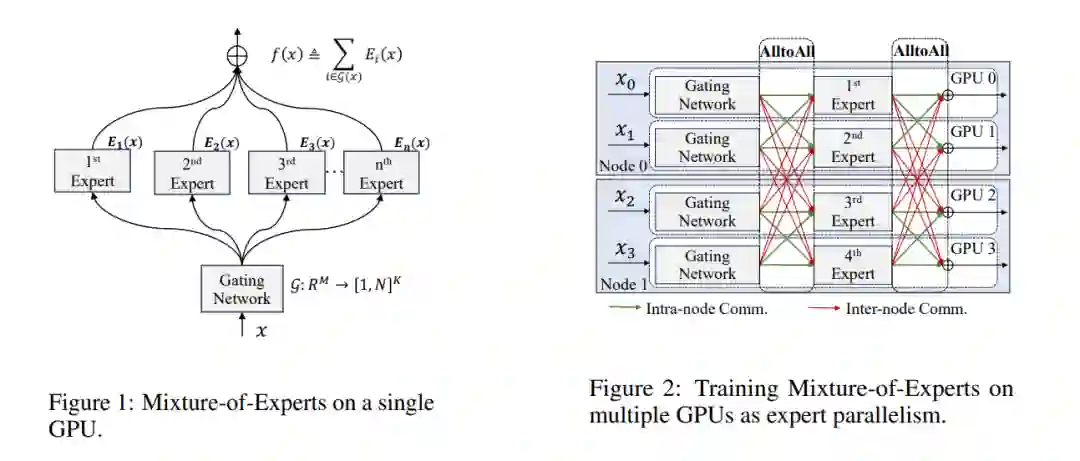
更大的 Transformer 模型在各种任务上总是表现更好,但扩展模型规模需要更高的成本。为了高效地扩展模型,广泛采用了专家混合(MoE)架构,该架构由一个门控网络和一系列专家组成,通过将输入数据路由到固定数量的专家而非全部专家,从而保持训练成本不变。在现有的大规模 MoE 训练系统中,专家会分布在不同的 GPU 上进行并行化,因此输入数据需要额外的全对全(all-to-all)通信来访问目标专家并执行相应的计算。然而,通过对常用 GPU 集群上三种主流 MoE 模型的训练过程进行评估,我们发现全对全通信的比例平均约为 45%,这显著阻碍了 MoE 模型训练的效率和可扩展性。在本文中,我们提出了一种使用局部敏感哈希(LSH)的通信高效的 MoE 训练框架——LSH-MoE。我们首先介绍了现有系统中扩展 MoE 训练所面临的问题,并强调利用令牌相似性来实现数据压缩的潜力。随后,我们引入了一种基于 LSH 的高效压缩技术,该技术使用交叉多面体哈希(cross-polytope hashing)进行快速聚类,并实施了基于残差的误差补偿方案,以减轻压缩的负面影响。为了验证我们方法的有效性,我们在语言模型(如 RoBERTa、GPT 和 T5)以及视觉模型(如 Swin)上进行了预训练和微调任务的实验。结果表明,我们的方法在不同任务上的速度提升达到了 1.28× - 2.2×,显著优于其他方法。
成为VIP会员查看完整内容
相关内容
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日
Arxiv
156+阅读 · 2023年3月29日


最新内容
相关VIP内容
相关资讯
相关论文
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日
Arxiv
156+阅读 · 2023年3月29日