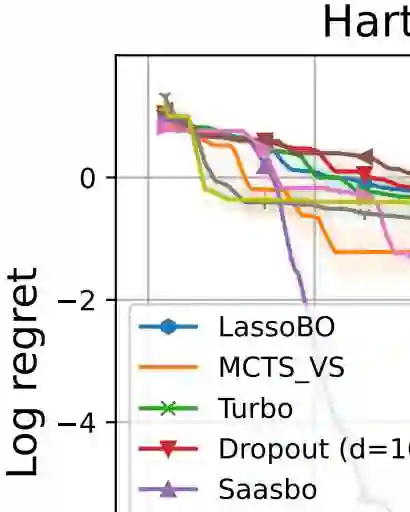
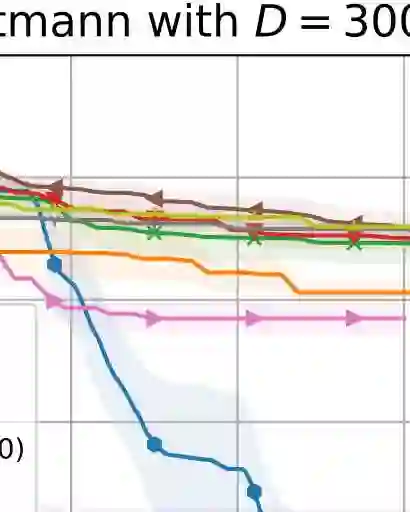
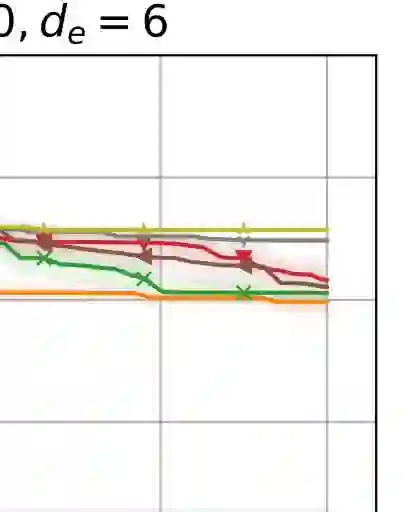
Bayesian optimization (BO) is a leading method for optimizing expensive black-box optimization and has been successfully applied across various scenarios. However, BO suffers from the curse of dimensionality, making it challenging to scale to high-dimensional problems. Existing work has adopted a variable selection strategy to select and optimize only a subset of variables iteratively. Although this approach can mitigate the high-dimensional challenge in BO, it still leads to sample inefficiency. To address this issue, we introduce a novel method that identifies important variables by estimating the length scales of Gaussian process kernels. Next, we construct an effective search region consisting of multiple subspaces and optimize the acquisition function within this region, focusing on only the important variables. We demonstrate that our proposed method achieves cumulative regret with a sublinear growth rate in the worst case while maintaining computational efficiency. Experiments on high-dimensional synthetic functions and real-world problems show that our method achieves state-of-the-art performance.
翻译:贝叶斯优化(BO)是一种用于优化昂贵黑盒函数的主流方法,已在多种场景中成功应用。然而,BO受到维度灾难的影响,难以扩展至高维问题。现有研究采用变量选择策略,仅迭代地选择并优化部分变量。尽管这种方法能够缓解BO中的高维挑战,但仍会导致样本效率低下。为解决这一问题,我们提出了一种新方法,通过估计高斯过程核函数的长度尺度来识别重要变量。接着,我们构建一个由多个子空间组成的有效搜索区域,并在此区域内优化采集函数,仅聚焦于重要变量。我们证明,所提出的方法在最坏情况下能以次线性增长速率实现累积遗憾,同时保持计算效率。在高维合成函数和实际问题上进行的实验表明,我们的方法达到了最先进的性能水平。