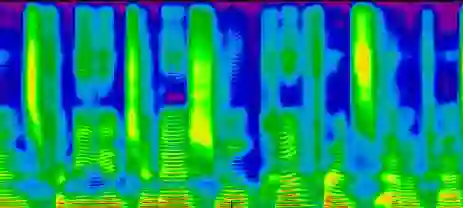
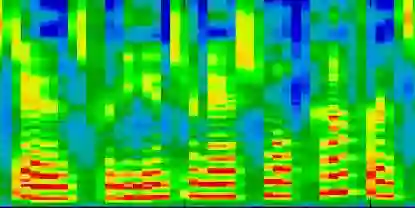
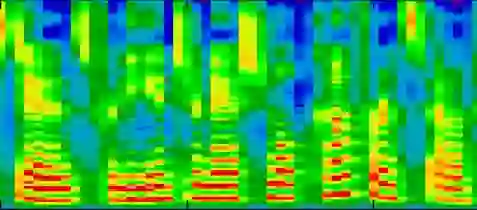
Recently, deep learning-based Text-to-Speech (TTS) systems have achieved high-quality speech synthesis results. Recurrent neural networks have become a standard modeling technique for sequential data in TTS systems and are widely used. However, training a TTS model which includes RNN components requires powerful GPU performance and takes a long time. In contrast, CNN-based sequence synthesis techniques can significantly reduce the parameters and training time of a TTS model while guaranteeing a certain performance due to their high parallelism, which alleviate these economic costs of training. In this paper, we propose a lightweight TTS system based on deep convolutional neural networks, which is a two-stage training end-to-end TTS model and does not employ any recurrent units. Our model consists of two stages: Text2Spectrum and SSRN. The former is used to encode phonemes into a coarse mel spectrogram and the latter is used to synthesize the complete spectrum from the coarse mel spectrogram. Meanwhile, we improve the robustness of our model by a series of data augmentations, such as noise suppression, time warping, frequency masking and time masking, for solving the low resource mongolian problem. Experiments show that our model can reduce the training time and parameters while ensuring the quality and naturalness of the synthesized speech compared to using mainstream TTS models. Our method uses NCMMSC2022-MTTSC Challenge dataset for validation, which significantly reduces training time while maintaining a certain accuracy.
翻译:近年来,基于深度学习的文本转语音(TTS)系统已实现高质量的语音合成结果。循环神经网络作为TTS系统中序列数据的标准建模技术被广泛应用。然而,包含RNN组件的TTS模型训练需要强大的GPU性能且耗时较长。相比之下,基于CNN的序列合成技术因其高并行性,在保证一定性能的同时能显著减少TTS模型的参数量和训练时间,从而降低训练的经济成本。本文提出一种基于深度卷积神经网络的轻量级TTS系统,该模型采用两阶段训练端到端架构,且未使用任何循环单元。模型包含两个阶段:Text2Spectrum和SSRN。前者用于将音素编码为粗略梅尔频谱图,后者则从粗略梅尔频谱图合成完整频谱。同时,我们通过一系列数据增强方法(如噪声抑制、时间扭曲、频率掩蔽和时间掩蔽)提升模型鲁棒性,以解决低资源蒙古语问题。实验表明,与主流TTS模型相比,本模型在保证合成语音质量与自然度的前提下,能够减少训练时间与参数量。本研究使用NCMMSC2022-MTTSC挑战赛数据集进行验证,在维持一定准确率的同时显著缩短了训练时间。