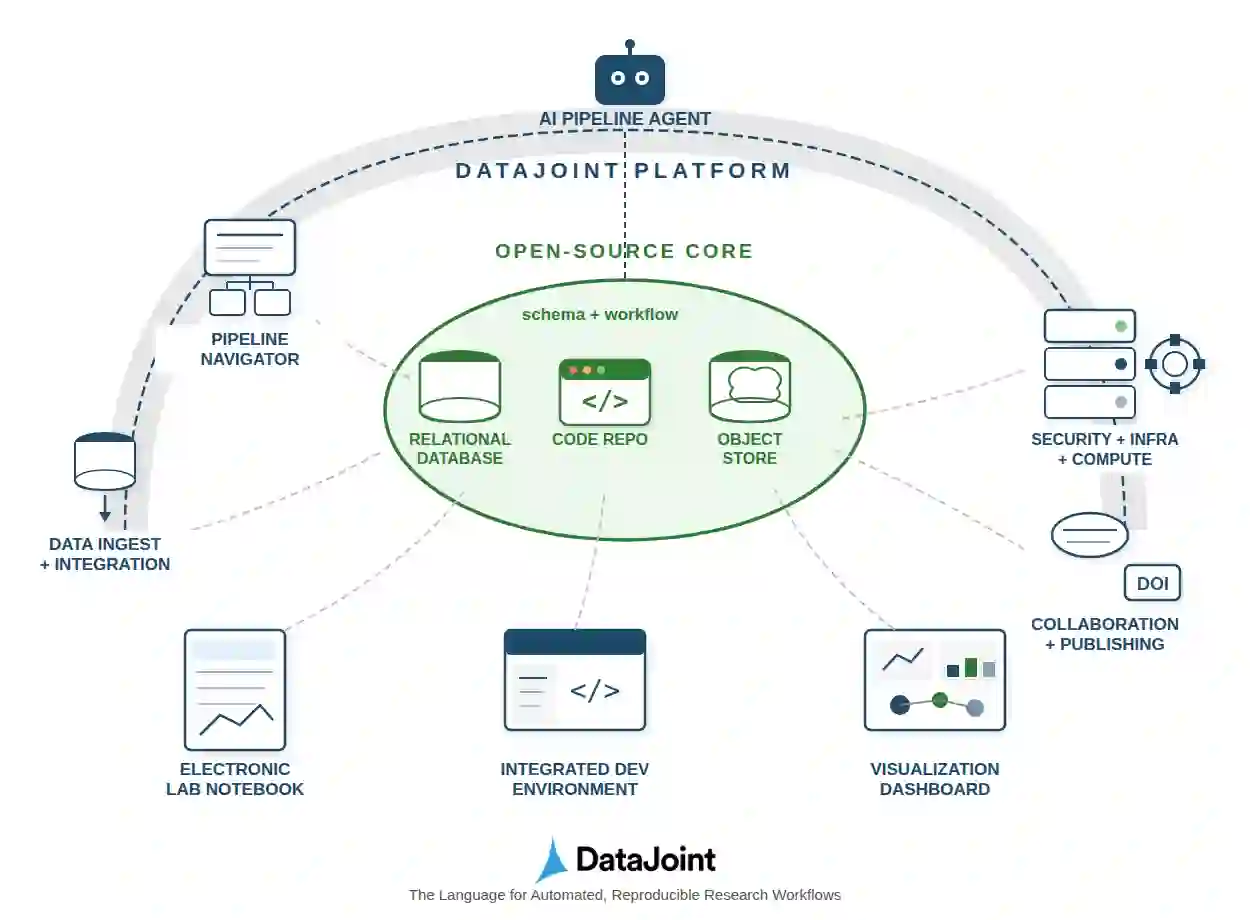
Operational rigor determines whether human-agent collaboration succeeds or fails. Scientific data pipelines need the equivalent of DevOps -- SciOps -- yet common approaches fragment provenance across disconnected systems without transactional guarantees. DataJoint 2.0 addresses this gap through the relational workflow model: tables represent workflow steps, rows represent artifacts, foreign keys prescribe execution order. The schema specifies not only what data exists but how it is derived -- a single formal system where data structure, computational dependencies, and integrity constraints are all queryable, enforceable, and machine-readable. Four technical innovations extend this foundation: object-augmented schemas integrating relational metadata with scalable object storage, semantic matching using attribute lineage to prevent erroneous joins, an extensible type system for domain-specific formats, and distributed job coordination designed for composability with external orchestration. By unifying data structure, data, and computational transformations, DataJoint creates a substrate for SciOps where agents can participate in scientific workflows without risking data corruption.
翻译:操作严谨性决定了人机协作的成败。科学数据流水线需要类似 DevOps 的体系——SciOps——然而常见方法将溯源信息分散在缺乏事务保证的孤立系统中。DataJoint 2.0 通过关系型工作流模型解决这一缺陷:数据表表示工作流步骤,数据行表示工作产物,外键规定执行顺序。其模式不仅定义数据内容,更规定数据衍生方式——形成统一的形式化系统,使数据结构、计算依赖与完整性约束皆可查询、可执行且机器可读。四项技术突破扩展了此基础:集成关系型元数据与可扩展对象存储的对象增强模式、利用属性溯源防止错误连接操作的语义匹配机制、支持领域特定格式的可扩展类型系统,以及为外部编排工具可组合性设计的分布式作业协调框架。通过统一数据结构、数据实体与计算转换过程,DataJoint 构建了 SciOps 的基座,使智能体能在确保数据完整性的前提下参与科学工作流。