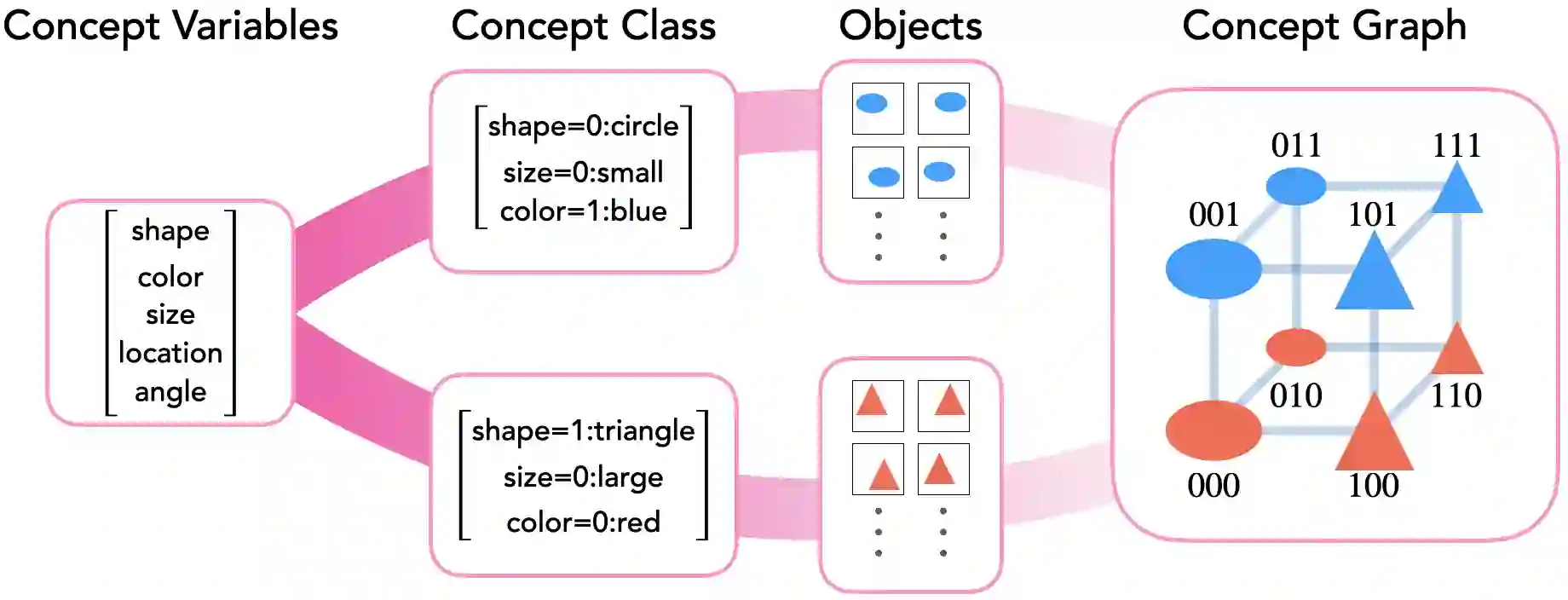
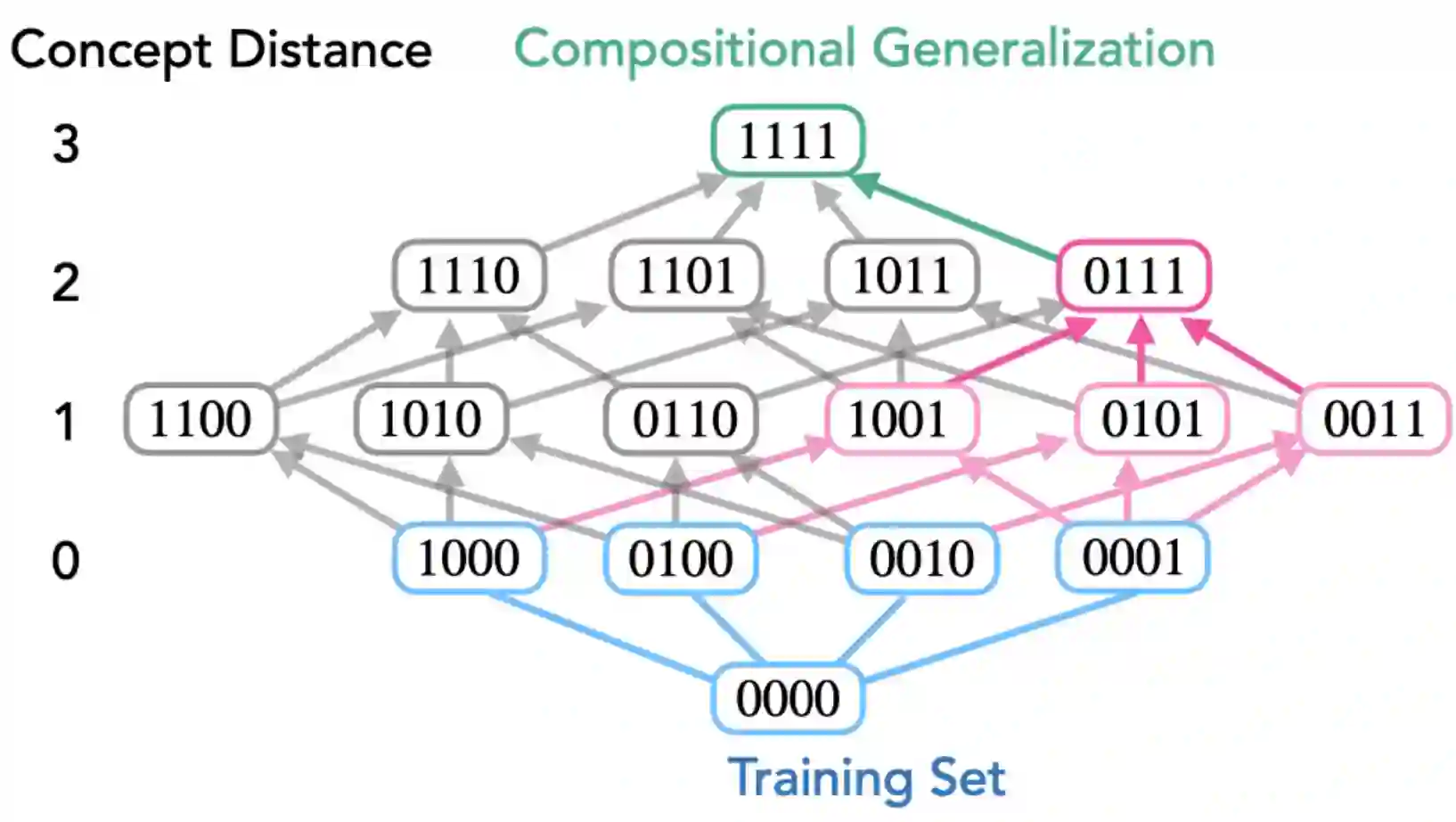
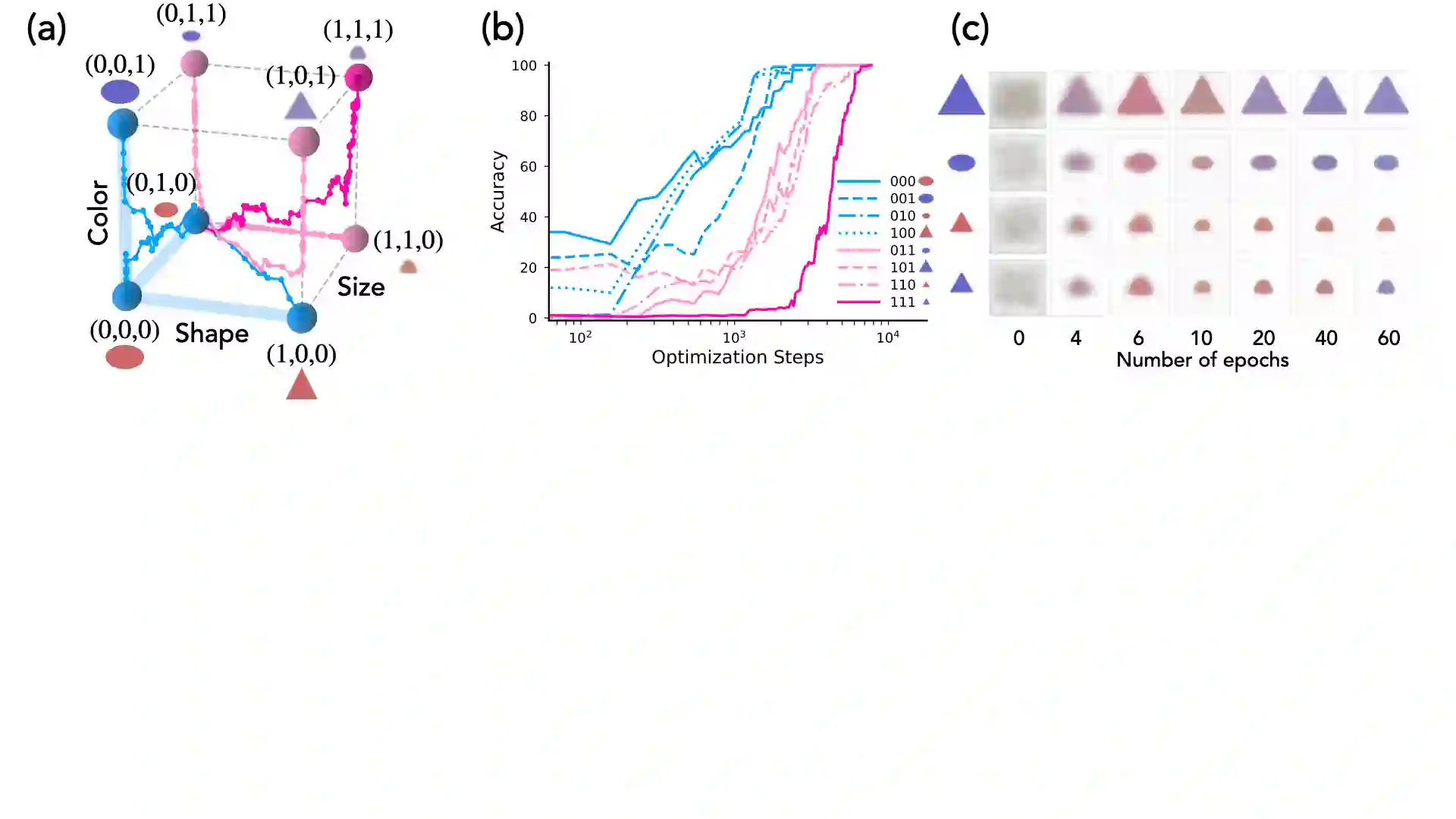
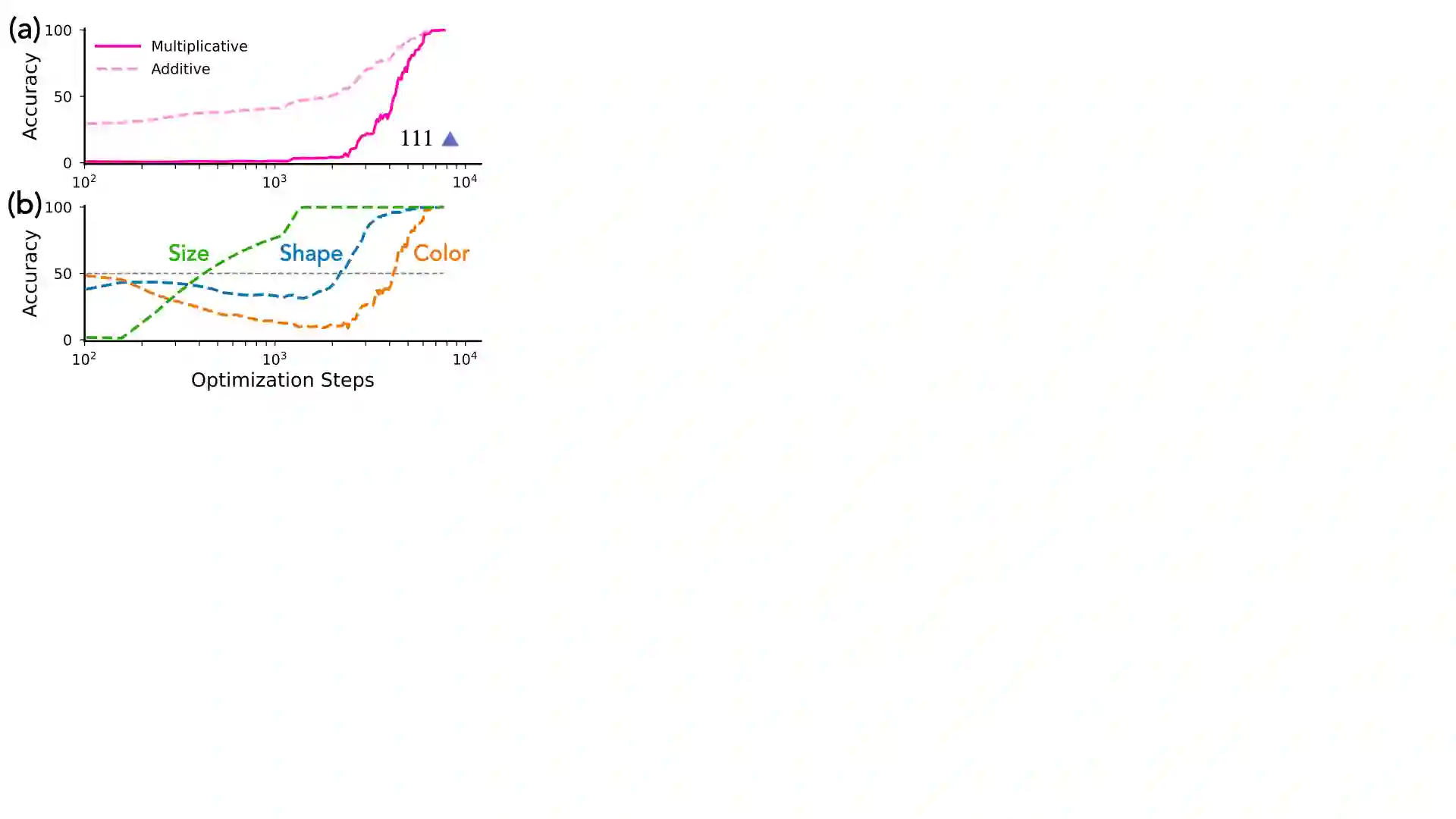
Modern generative models exhibit unprecedented capabilities to generate extremely realistic data. However, given the inherent compositionality of the real world, reliable use of these models in practical applications requires that they exhibit the capability to compose a novel set of concepts to generate outputs not seen in the training data set. Prior work demonstrates that recent diffusion models do exhibit intriguing compositional generalization abilities, but also fail unpredictably. Motivated by this, we perform a controlled study for understanding compositional generalization in conditional diffusion models in a synthetic setting, varying different attributes of the training data and measuring the model's ability to generate samples out-of-distribution. Our results show: (i) the order in which the ability to generate samples from a concept and compose them emerges is governed by the structure of the underlying data-generating process; (ii) performance on compositional tasks exhibits a sudden "emergence" due to multiplicative reliance on the performance of constituent tasks, partially explaining emergent phenomena seen in generative models; and (iii) composing concepts with lower frequency in the training data to generate out-of-distribution samples requires considerably more optimization steps compared to generating in-distribution samples. Overall, our study lays a foundation for understanding capabilities and compositionality in generative models from a data-centric perspective.
翻译:现代生成模型展现出前所未有的能力,能够生成极其逼真的数据。然而,鉴于现实世界固有的组合性,这些模型在实践应用中的可靠使用要求其具备组合新颖概念集、生成训练数据集中未见输出的能力。先前研究表明,近期扩散模型确实展现出有趣的组合泛化能力,但也会意外失效。受此启发,我们通过控制实验在合成场景中研究条件扩散模型的组合泛化能力,系统变化训练数据的多种属性,并测量模型生成分布外样本的能力。我们的结果显示:(i)从单一概念生成样本及组合这些概念的能力涌现顺序,取决于底层数据生成过程的结构;(ii)组合任务的性能因对构成任务性能的乘数依赖而呈现突发性"涌现",部分解释了生成模型中观察到的涌现现象;(iii)组合训练数据中出现频率较低的概念以生成分布外样本,相比生成分布内样本需要显著更多的优化步骤。总体而言,我们的研究从数据中心的视角为理解生成模型的能力与组合性奠定了基础。