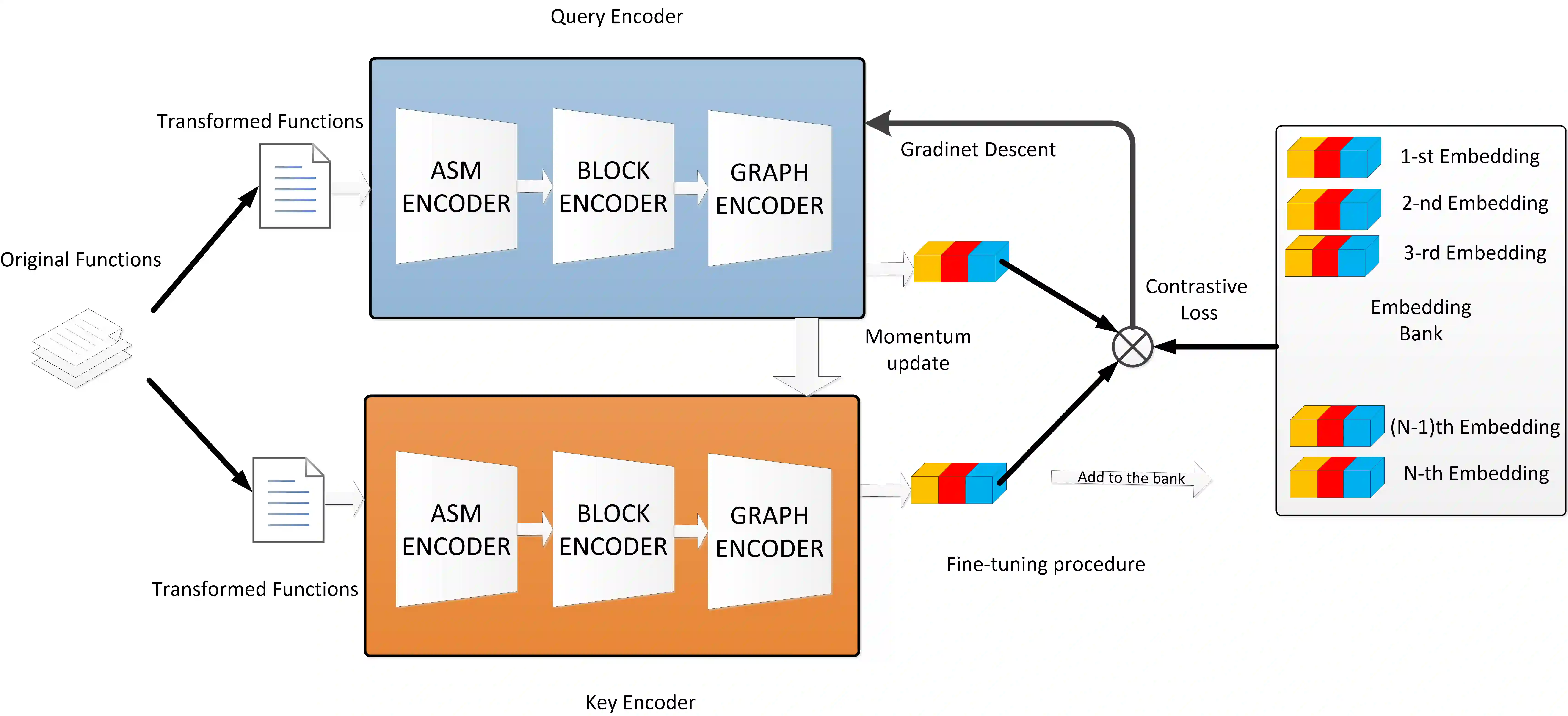
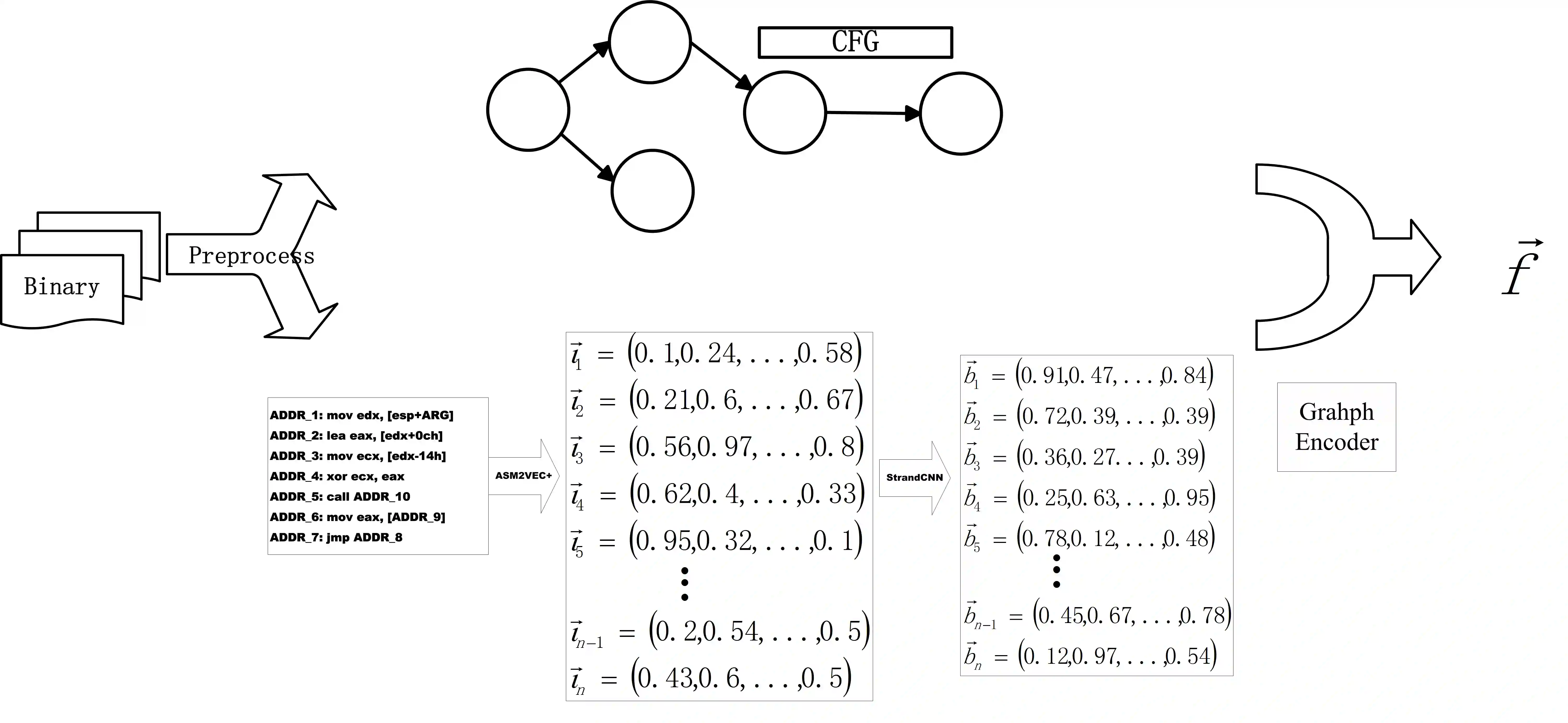
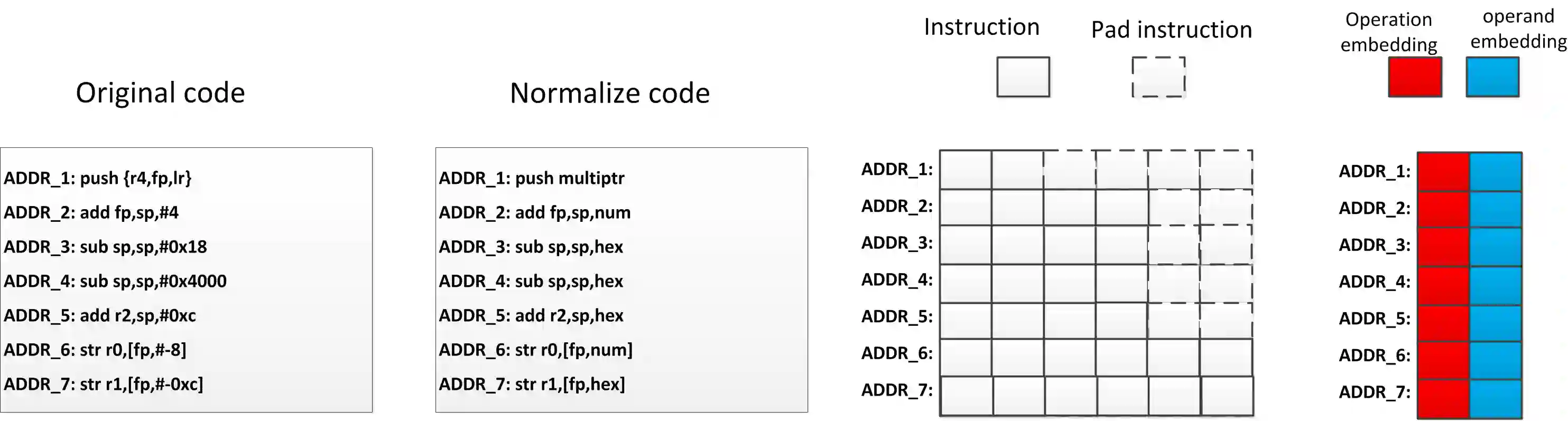
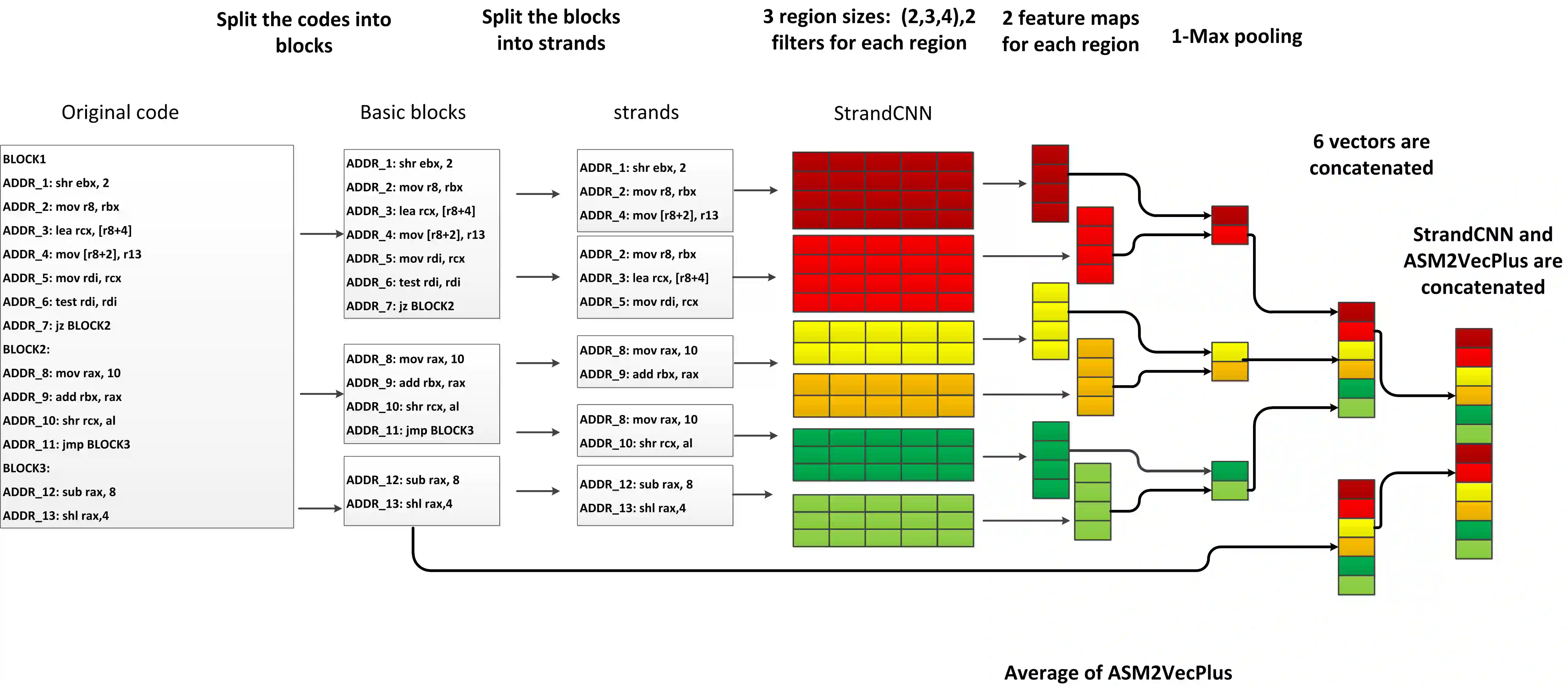
In the field of cybersecurity, the ability to compute similarity scores at the function level is import. Considering that a single binary file may contain an extensive amount of functions, an effective learning framework must exhibit both high accuracy and efficiency when handling substantial volumes of data. Nonetheless, conventional methods encounter several limitations. Firstly, accurately annotating different pairs of functions with appropriate labels poses a significant challenge, thereby making it difficult to employ supervised learning methods without risk of overtraining on erroneous labels. Secondly, while SOTA models often rely on pre-trained encoders or fine-grained graph comparison techniques, these approaches suffer from drawbacks related to time and memory consumption. Thirdly, the momentum update algorithm utilized in graph-based contrastive learning models can result in information leakage. Surprisingly, none of the existing articles address this issue. This research focuses on addressing the challenges associated with large-scale BCSD. To overcome the aforementioned problems, we propose GraphMoco: a graph momentum contrast model that leverages multimodal structural information for efficient binary function representation learning on a large scale. Our approach employs a CNN-based model and departs from the usage of memory-intensive pre-trained models. We adopt an unsupervised learning strategy that effectively use the intrinsic structural information present in the binary code. Our approach eliminates the need for manual labeling of similar or dissimilar information.Importantly, GraphMoco demonstrates exceptional performance in terms of both efficiency and accuracy when operating on extensive datasets. Our experimental results indicate that our method surpasses the current SOTA approaches in terms of accuracy.
翻译:在网络安全领域,在函数级别计算相似度得分的能力至关重要。考虑到单个二进制文件可能包含大量函数,有效的学习框架在处理海量数据时必须兼具高准确率和高效率。然而,传统方法存在若干局限。首先,为不同的函数对精准标注合适标签是一项严峻挑战,这使得有监督学习方法难以应用,因为存在在错误标签上过度训练的风险。其次,尽管SOTA模型通常依赖预训练编码器或细粒度图比较技术,但这些方法存在时间和内存消耗方面的缺陷。第三,基于图的对比学习模型中采用的动量更新算法可能导致信息泄露。令人惊讶的是,现有文献均未解决此问题。本研究聚焦于应对大规模BCSD相关的挑战。为克服上述问题,我们提出GraphMoco:一种利用多模态结构信息进行大规模高效二进制函数表示学习的图动量对比模型。我们的方法采用基于CNN的模型,摒弃了内存密集型的预训练模型。我们采用无监督学习策略,有效利用二进制代码中固有的结构信息,无需人工标注相似或相异信息。重要的是,GraphMoco在处理大规模数据集时在效率和准确率方面均表现出色。我们的实验结果表明,该方法在准确率上超越了当前的SOTA方法。