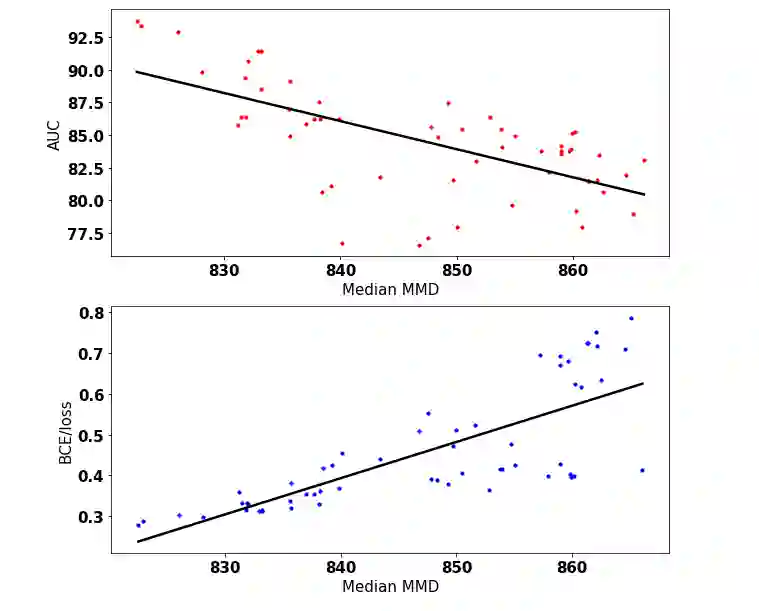
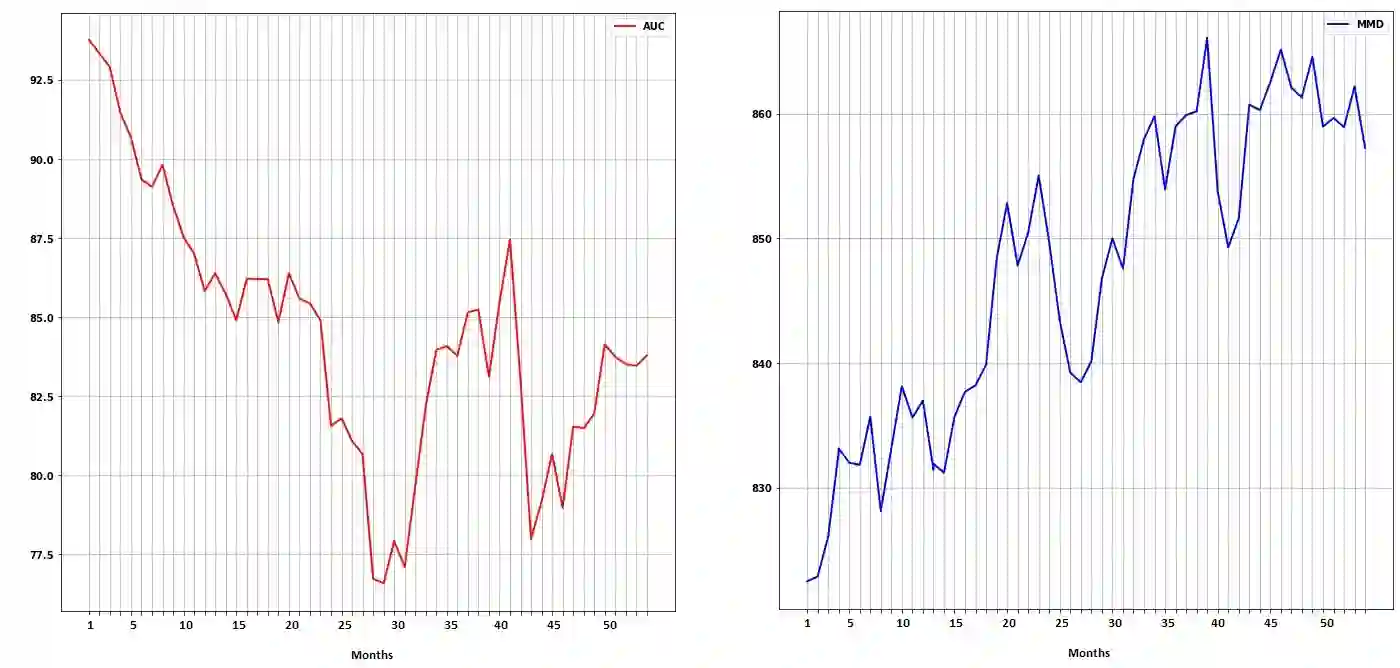
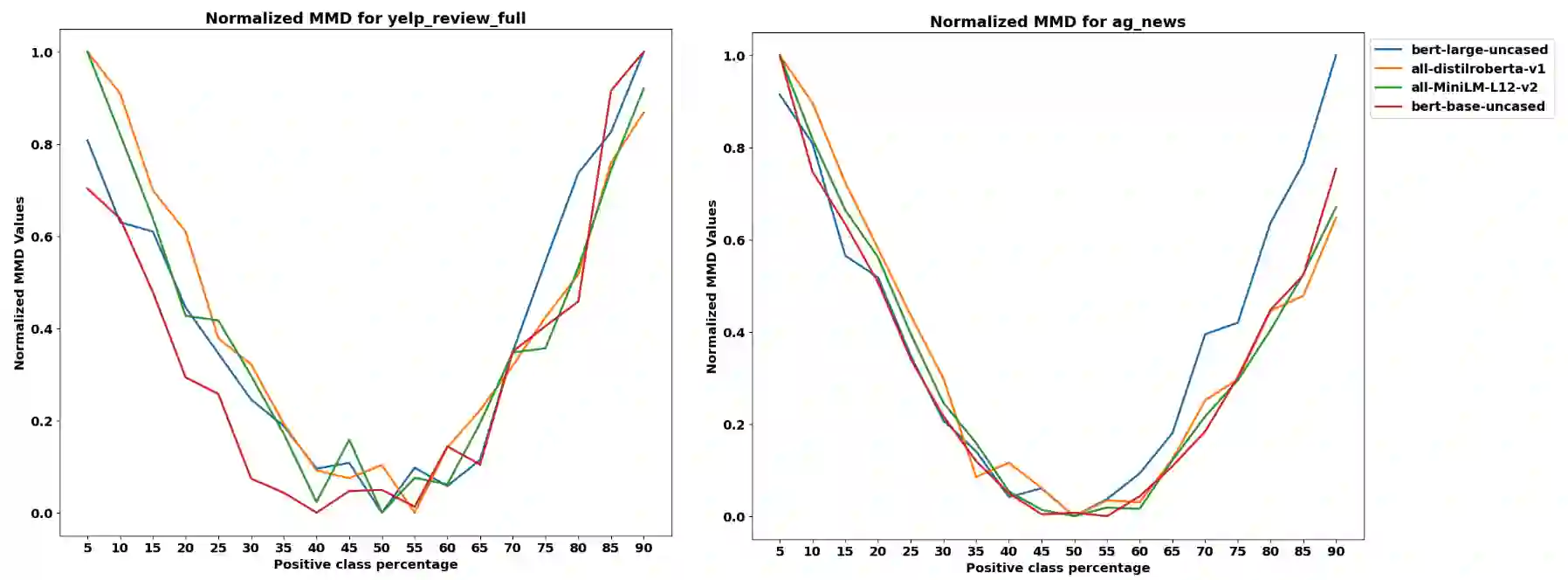
Drift in machine learning refers to the phenomenon where the statistical properties of data or context, in which the model operates, change over time leading to a decrease in its performance. Therefore, maintaining a constant monitoring process for machine learning model performance is crucial in order to proactively prevent any potential performance regression. However, supervised drift detection methods require human annotation and consequently lead to a longer time to detect and mitigate the drift. In our proposed unsupervised drift detection method, we follow a two step process. Our first step involves encoding a sample of production data as the target distribution, and the model training data as the reference distribution. In the second step, we employ a kernel-based statistical test that utilizes the maximum mean discrepancy (MMD) distance metric to compare the reference and target distributions and estimate any potential drift. Our method also identifies the subset of production data that is the root cause of the drift. The models retrained using these identified high drift samples show improved performance on online customer experience quality metrics.
翻译:机器学习中的漂移是指模型运行所依赖的数据或上下文的统计属性随时间变化,导致模型性能下降的现象。因此,持续监控机器学习模型性能对于主动预防潜在的性能退化至关重要。然而,有监督的漂移检测方法需要人工标注,从而导致检测和缓解漂移的时间较长。在我们提出的无监督漂移检测方法中,我们遵循两步流程。第一步涉及将生产数据的样本编码为目标分布,将模型训练数据编码为参考分布。第二步中,我们采用基于核的统计检验,利用最大均值差异(MMD)距离度量来比较参考分布和目标分布,并估计任何潜在的漂移。我们的方法还能识别导致漂移的生产数据子集。使用这些识别出的高漂移样本重新训练的模型,在在线客户体验质量指标上表现出性能提升。