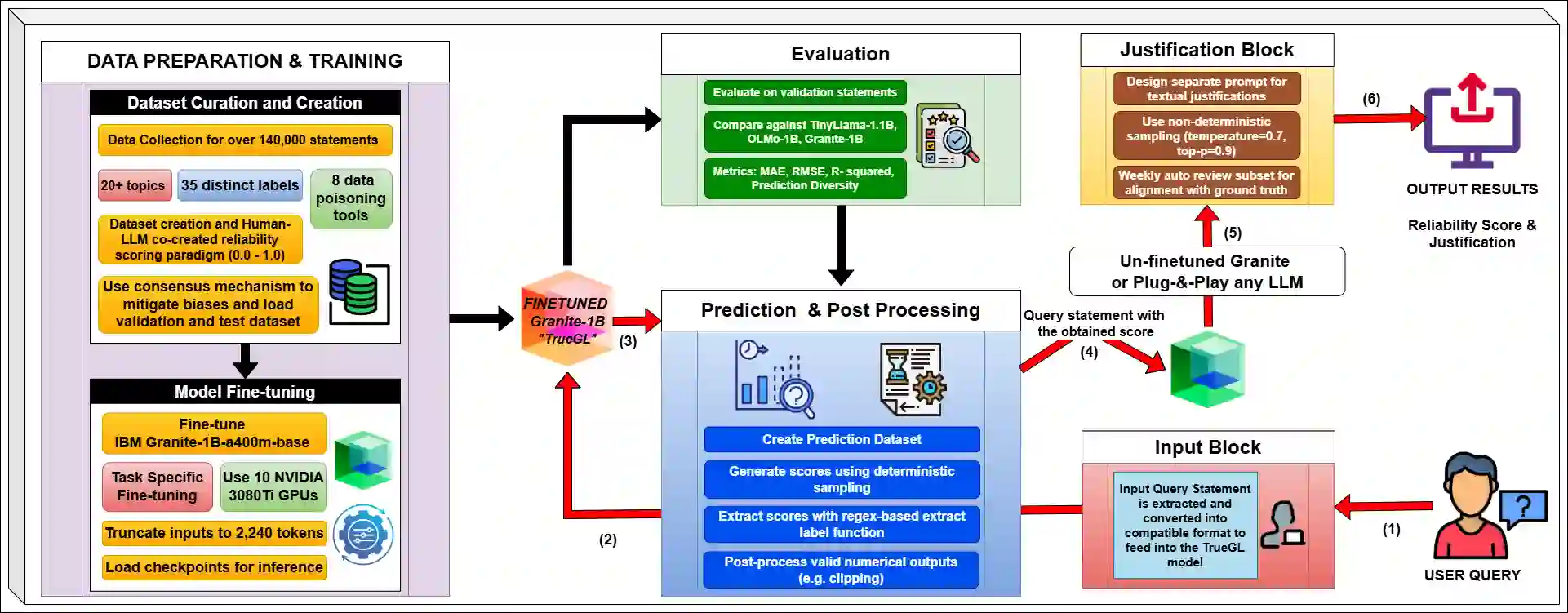
In an era of AI-generated misinformation flooding the web, existing tools struggle to empower users with nuanced, transparent assessments of content credibility. They often default to binary (true/false) classifications without contextual justifications, leaving users vulnerable to disinformation. We address this gap by introducing TRACE: Transparent Reliability Assessment with Contextual Explanations, a unified framework that performs two key tasks: (1) it assigns a fine-grained, continuous reliability score (from 0.1 to 1.0) to web content, and (2) it generates a contextual explanation for its assessment. The core of TRACE is the TrueGL-1B model, fine-tuned on a novel, large-scale dataset of over 140,000 articles. This dataset's primary contribution is its annotation with 35 distinct continuous reliability scores, created using a Human-LLM co-creation and data poisoning paradigm. This method overcomes the limitations of binary-labeled datasets by populating the mid-ranges of reliability. In our evaluation, TrueGL-1B consistently outperforms other small-scale LLM baselines and rule-based approaches on key regression metrics, including MAE, RMSE, and R2. The model's high accuracy and interpretable justifications make trustworthy information more accessible. To foster future research, our code and model are made publicly available here: github.com/zade90/TrueGL.
翻译:在人工智能生成错误信息充斥网络的时代,现有工具难以向用户提供细致、透明的网络内容可信度评估。这些工具通常仅提供二元(真/假)分类而缺乏上下文解释,使用户易受虚假信息影响。为弥补这一不足,我们提出了TRACE:基于上下文解释的透明可靠性评估框架。该统一框架执行两项核心任务:(1)为网络内容分配细粒度的连续可靠性评分(0.1至1.0);(2)生成评估结果的上下文解释。TRACE的核心是TrueGL-1B模型,该模型基于我们构建的新型大规模数据集(包含超过14万篇文章)进行微调。该数据集的主要贡献在于通过"人类-大语言模型协同创建与数据投毒"范式,为每篇文章标注了35种不同的连续可靠性分数,有效填补了传统二元标注数据集在中等可靠性区间的空白。评估结果表明,在关键回归指标(包括MAE、RMSE和R2)上,TrueGL-1B模型持续优于其他小规模LLM基线方法和基于规则的方法。该模型的高准确性与可解释性论证,使可信信息的获取变得更加便捷。为促进后续研究,我们的代码与模型已在以下地址开源:github.com/zade90/TrueGL。