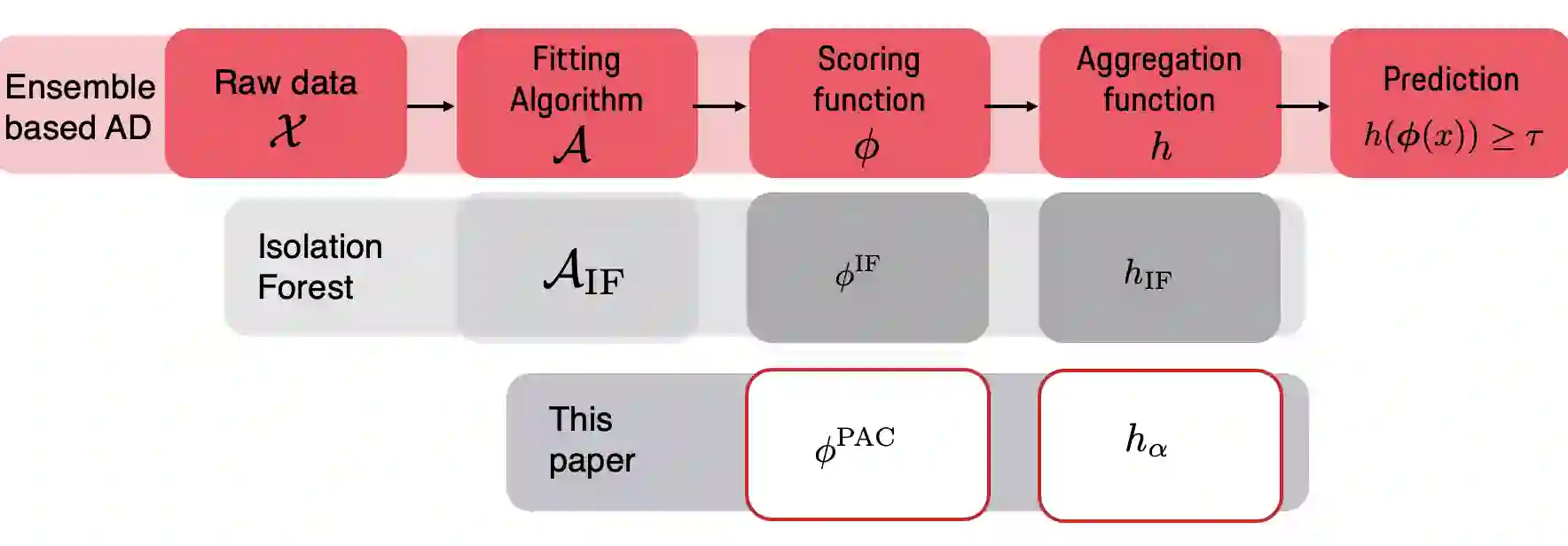
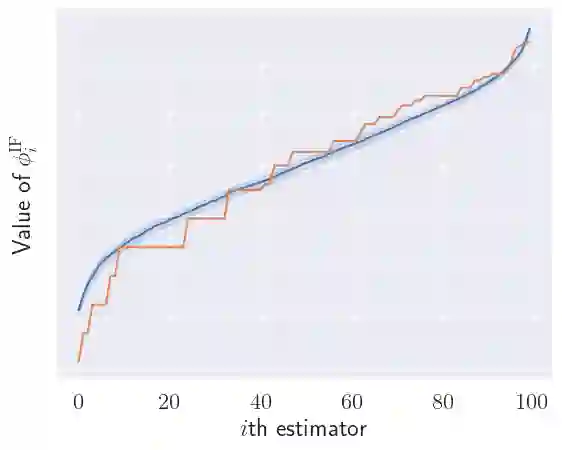
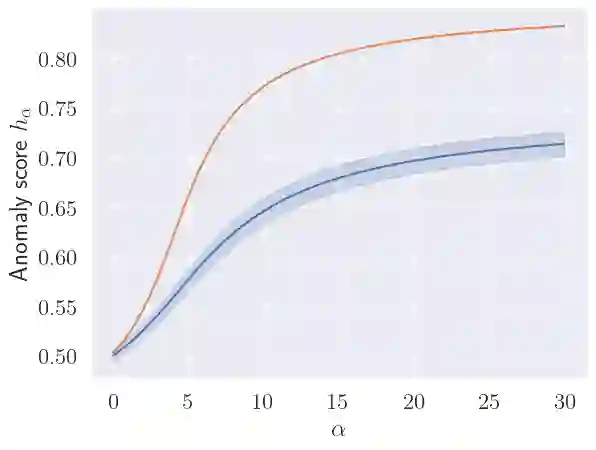
We make two contributions to the Isolation Forest method for anomaly and outlier detection. The first contribution is an information-theoretically motivated generalisation of the score function that is used to aggregate the scores across random tree estimators. This generalisation allows one to take into account not just the ensemble average across trees but instead the whole distribution. The second contribution is an alternative scoring function at the level of the individual tree estimator, in which we replace the depth-based scoring of the Isolation Forest with one based on hyper-volumes associated to an isolation tree's leaf nodes. We motivate the use of both of these methods on generated data and also evaluate them on 34 datasets from the recent and exhaustive ``ADBench'' benchmark, finding significant improvement over the standard isolation forest for both variants on some datasets and improvement on average across all datasets for one of the two variants. The code to reproduce our results is made available as part of the submission.
翻译:我们对用于异常值检测的孤立森林方法做出了两项贡献。第一项贡献是对评分函数提出信息论启发下的广义化处理,该函数用于聚合随机树估计器间的分数。这种广义化不仅考虑了树间的集成平均值,还涵盖了完整分布信息。第二项贡献是在单个树估计器层面提出替代性评分函数:以孤立树叶节点关联的超体积为基础,取代传统孤立森林的深度评分机制。我们在生成数据上验证了这两种方法的理论动机,并在近期全面的"ADBench"基准测试中的34个数据集上进行了评估。结果表明,两个变体在部分数据集上显著优于标准孤立森林,其中一个变体在所有数据集上的平均表现均有提升。论文附带了可复现结果的代码。