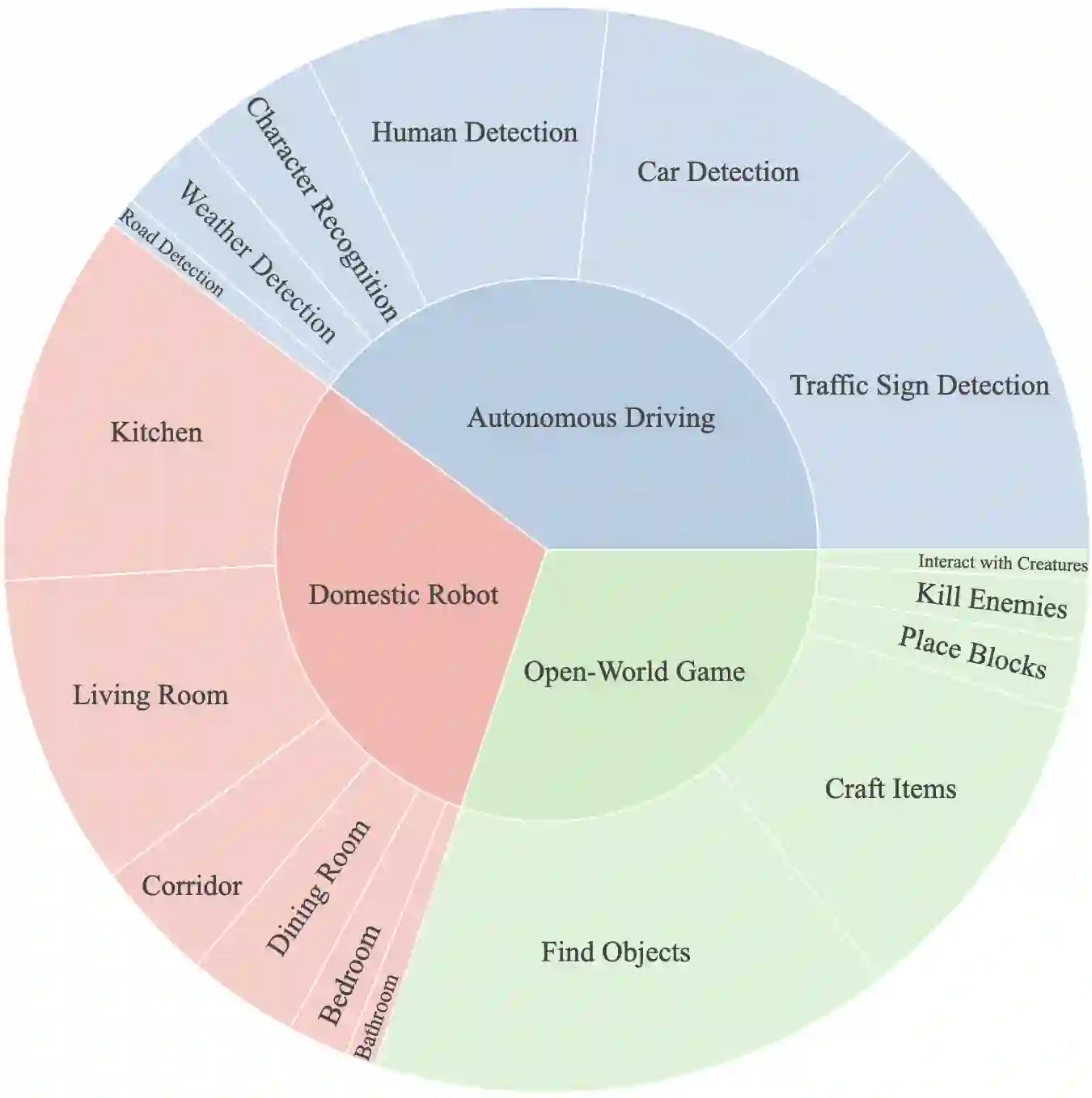
In this study, we explore the potential of Multimodal Large Language Models (MLLMs) in improving embodied decision-making processes for agents. While Large Language Models (LLMs) have been widely used due to their advanced reasoning skills and vast world knowledge, MLLMs like GPT4-Vision offer enhanced visual understanding and reasoning capabilities. We investigate whether state-of-the-art MLLMs can handle embodied decision-making in an end-to-end manner and whether collaborations between LLMs and MLLMs can enhance decision-making. To address these questions, we introduce a new benchmark called PCA-EVAL, which evaluates embodied decision-making from the perspectives of Perception, Cognition, and Action. Additionally, we propose HOLMES, a multi-agent cooperation framework that allows LLMs to leverage MLLMs and APIs to gather multimodal information for informed decision-making. We compare end-to-end embodied decision-making and HOLMES on our benchmark and find that the GPT4-Vision model demonstrates strong end-to-end embodied decision-making abilities, outperforming GPT4-HOLMES in terms of average decision accuracy (+3%). However, this performance is exclusive to the latest GPT4-Vision model, surpassing the open-source state-of-the-art MLLM by 26%. Our results indicate that powerful MLLMs like GPT4-Vision hold promise for decision-making in embodied agents, offering new avenues for MLLM research. Code and data are open at https://github.com/pkunlp-icler/PCA-EVAL/.
翻译:在本研究中,我们探索了多模态大语言模型(MLLMs)在提升智能体具身决策过程中的潜力。虽然大语言模型(LLMs)因其先进的推理能力和广泛的世界知识而被广泛应用,但GPT4-Vision等MLLMs提供了更强的视觉理解和推理能力。我们研究了最先进的MLLMs能否以端到端方式处理具身决策,以及LLMs与MLLMs之间的协作能否增强决策能力。为解决这些问题,我们引入了一个名为PCA-EVAL的新基准,该基准从感知、认知和行动三个角度评估具身决策。此外,我们提出了HOLMES,一个多智能体协作框架,允许LLMs利用MLLMs和API收集多模态信息以做出明智的决策。我们在基准上比较了端到端具身决策与HOLMES,发现GPT4-Vision模型展现出强大的端到端具身决策能力,在平均决策准确率上优于GPT4-HOLMES(+3%)。然而,这一性能仅限于最新的GPT4-Vision模型,其比开源最先进的MLLM高出26%。我们的结果表明,像GPT4-Vision这样强大的MLLMs在具身智能体的决策中具有前景,为MLLM研究提供了新方向。代码和数据已开源至https://github.com/pkunlp-icler/PCA-EVAL/。