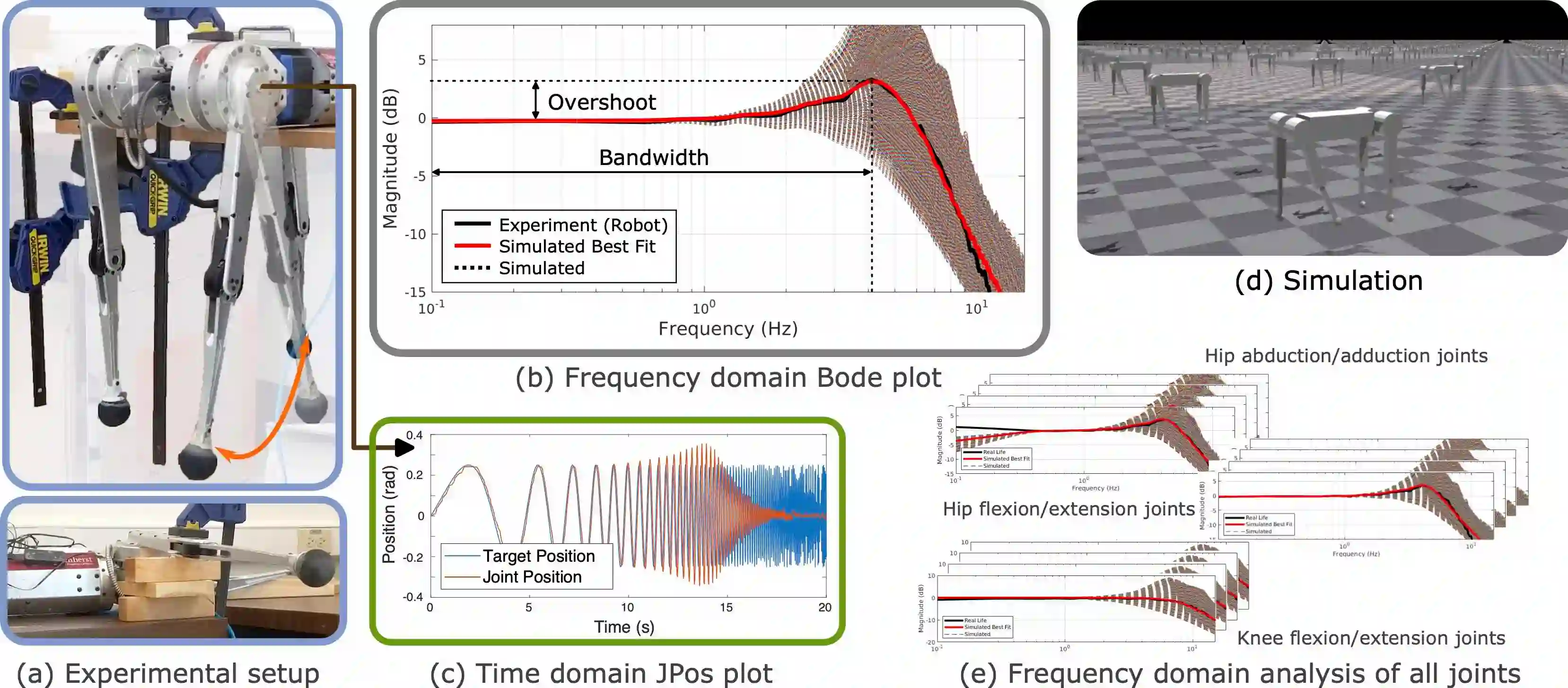
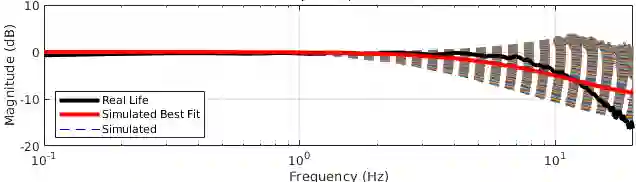
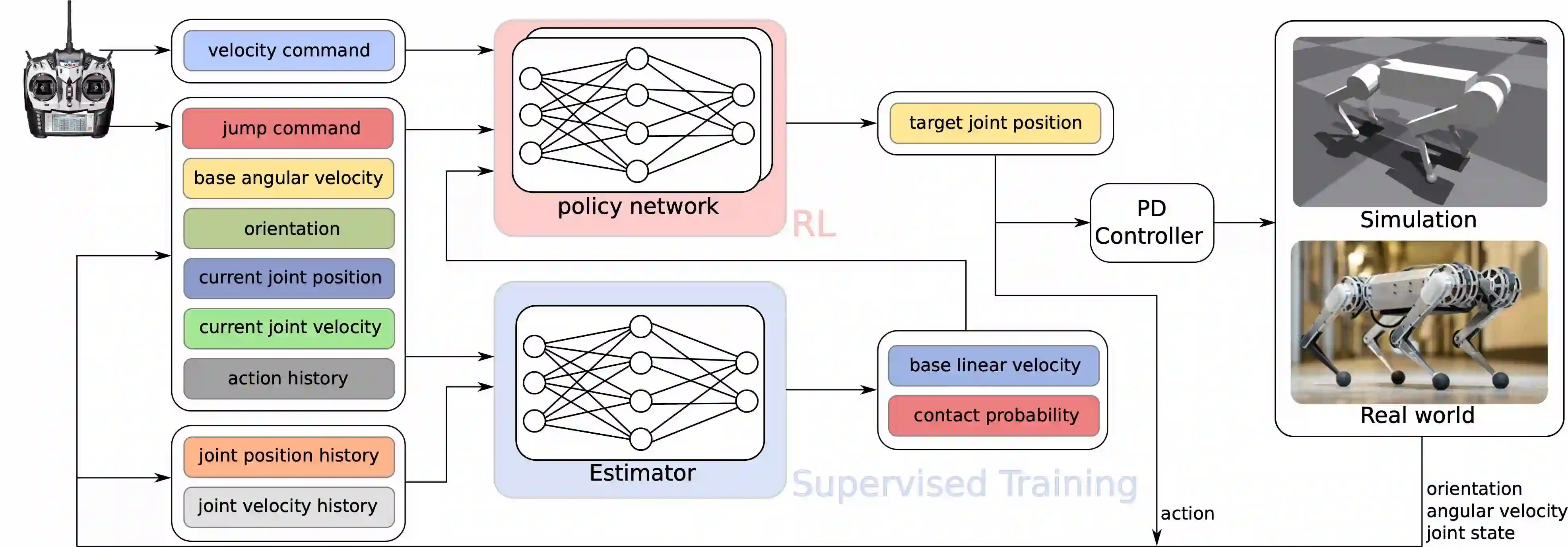
Replicating the remarkable athleticism seen in animals has long been a challenge in robotics control. Although Reinforcement Learning (RL) has demonstrated significant progress in dynamic legged locomotion control, the substantial sim-to-real gap often hinders the real-world demonstration of truly dynamic movements. We propose a new framework to mitigate this gap through frequency-domain analysis-based impedance matching between simulated and real robots. Our framework offers a structured guideline for parameter selection and the range for dynamics randomization in simulation, thus facilitating a safe sim-to-real transfer. The learned policy using our framework enabled jumps across distances of 55 cm and heights of 38 cm. The results are, to the best of our knowledge, one of the highest and longest running jumps demonstrated by an RL-based control policy in a real quadruped robot. Note that the achieved jumping height is approximately 85% of that obtained from a state-of-the-art trajectory optimization method, which can be seen as the physical limit for the given robot hardware. In addition, our control policy accomplished stable walking at speeds up to 2 m/s in the forward and backward directions, and 1 m/s in the sideway direction.
翻译:模仿动物卓越的运动能力一直是机器人控制领域的挑战。尽管强化学习(RL)在动态腿部运动控制方面取得了显著进展,但模拟与现实之间的巨大差距常常阻碍真正动态运动在真实世界的实现。我们提出一种新框架,通过基于频域分析的模拟机器人与真实机器人之间的阻抗匹配来缩小这一差距。该框架为参数选择及仿真中动力学随机化的范围提供了结构化指导,从而促进安全的仿真到现实迁移。采用该框架学习的策略使机器人实现了55厘米的跳跃距离和38厘米的跳跃高度。据我们所知,这是基于强化学习控制策略在真实四足机器人上展示的最高且最远的奔跑跳跃之一。值得注意的是,所达到的跳跃高度约为通过最先进轨迹优化方法(可视为给定机器人硬件物理极限)所得结果的85%。此外,我们的控制策略在前进和后退方向实现了高达2米/秒的稳定行走速度,在侧向方向实现了1米/秒的稳定行走速度。