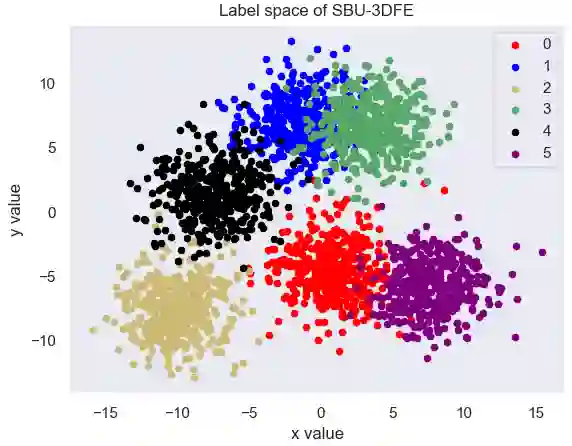
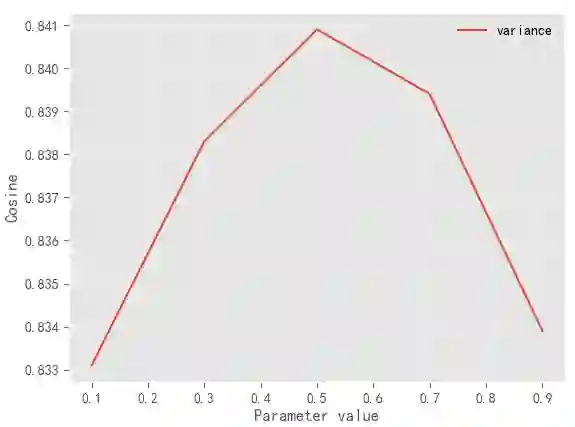
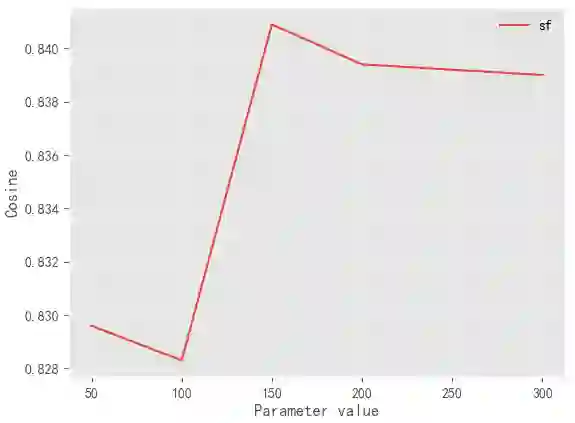
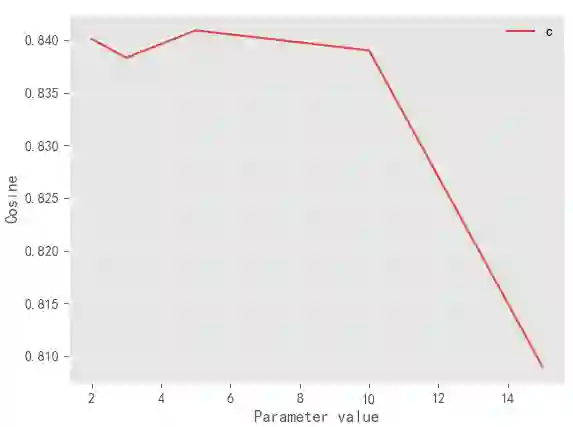
Label Distribution Learning (LDL) aims to characterize the polysemy of an instance by building a set of descriptive degrees corresponding to the instance. In recent years, researchers seek to model to obtain an accurate label distribution by using low-rank, label relations, expert experiences, and label uncertainty estimation. In general, these methods are based on algorithms with parameter learning in a linear (including kernel functions) or deep learning framework. However, these methods are difficult to deploy and update online due to high training costs, limited scalability, and outlier sensitivity. To address this problem, we design a novel LDL method called UAKNN, which has the advantages of the KNN algorithm with the benefits of uncertainty modeling. In addition, we provide solutions to the dilemma of existing work on extremely label distribution spaces. Extensive experiments demonstrate that our method is significantly competitive on 12 benchmarks and that the inference speed of the model is well-suited for industrial-level applications.
翻译:标签分布学习(LDL)旨在通过构建与实例对应的一组描述性程度来刻画实例的多义性。近年来,研究者尝试利用低秩、标签关系、专家经验和标签不确定性估计等方法来建模以获得准确的标签分布。一般而言,这些方法基于线性(包括核函数)或深度学习框架中具有参数学习的算法。然而,由于训练成本高、可扩展性有限以及对异常值敏感,这些方法难以在线部署和更新。为解决这一问题,我们设计了一种名为UAKNN的新型LDL方法,该方法结合了KNN算法的优势与不确定性建模的优点。此外,我们针对现有工作在极端标签分布空间中的困境提供了解决方案。大量实验表明,我们的方法在12个基准数据集上具有显著竞争力,且模型的推理速度非常适合工业级应用。