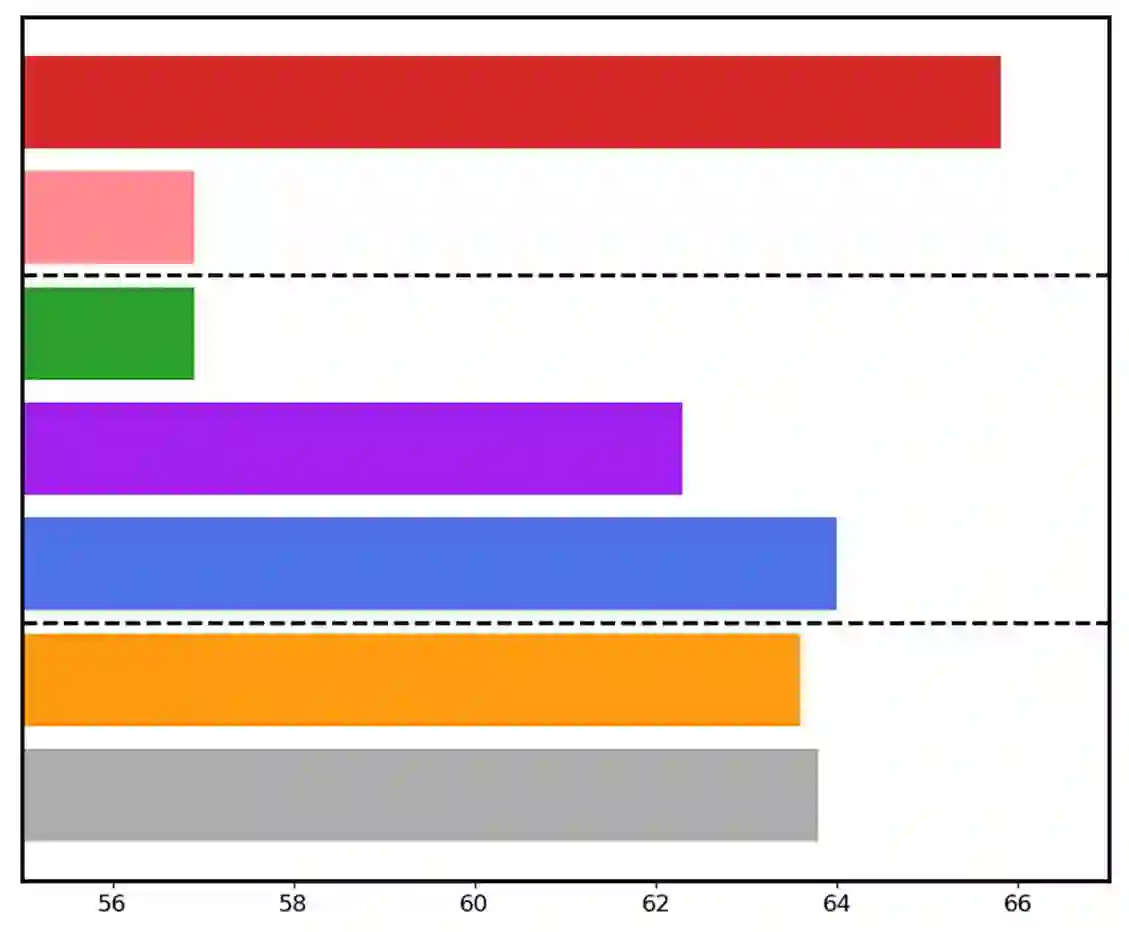
Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-o1, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-o1 independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-o1 to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-o1-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-o1 not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
翻译:大型语言模型在推理能力方面已展现出显著进步,尤其是通过推理时扩展技术,如OpenAI的o1模型所示。然而,当前的视觉语言模型在处理复杂视觉问答任务时,往往难以进行系统化和结构化的推理。本文中,我们提出了LLaVA-o1,一种新颖的视觉语言模型,旨在执行自主多阶段推理。与思维链提示不同,LLaVA-o1能够独立进行摘要、视觉解释、逻辑推理和结论生成的顺序阶段。这种结构化方法使LLaVA-o1在推理密集型任务上的准确性取得了显著提升。为实现这一目标,我们构建了LLaVA-o1-100k数据集,整合了多种视觉问答来源的样本,并提供了结构化推理标注。此外,我们提出了一种推理时阶段级束搜索方法,实现了有效的推理时扩展。值得注意的是,仅使用10万个训练样本和一种简单而有效的推理时扩展方法,LLaVA-o1不仅在广泛的多模态推理基准上超越了其基础模型8.9%,而且性能超过了更大规模甚至闭源模型,如Gemini-1.5-pro、GPT-4o-mini和Llama-3.2-90B-Vision-Instruct。