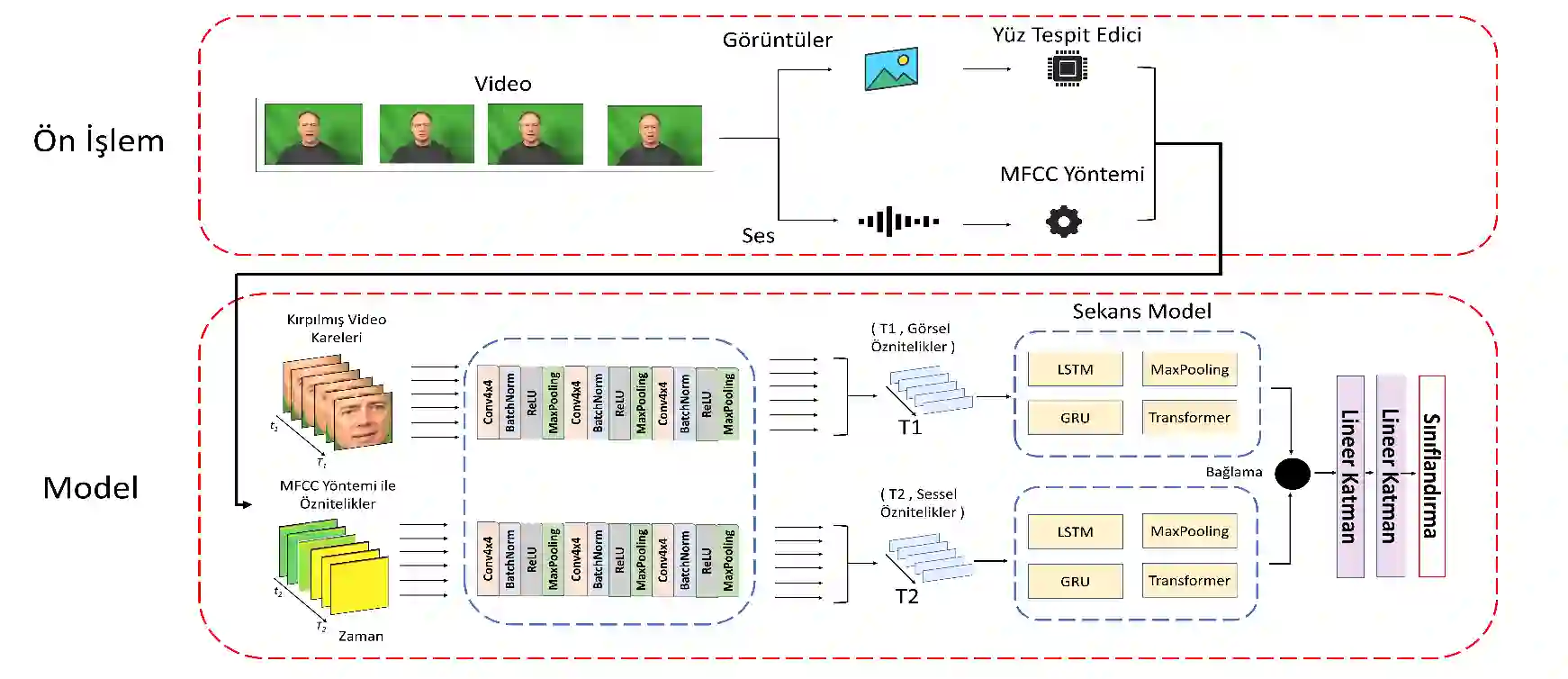
Emotion recognition has become an important research topic in the field of human-computer interaction. Studies on sound and videos to understand emotions focused mainly on analyzing facial expressions and classified 6 basic emotions. In this study, the performance of different sequence models in multi-modal emotion recognition was compared. The sound and images were first processed by multi-layered CNN models, and the outputs of these models were fed into various sequence models. The sequence model is GRU, Transformer, LSTM and Max Pooling. Accuracy, precision, and F1 Score values of all models were calculated. The multi-modal CREMA-D dataset was used in the experiments. As a result of the comparison of the CREMA-D dataset, GRU-based architecture with 0.640 showed the best result in F1 score, LSTM-based architecture with 0.699 in precision metric, while sensitivity showed the best results over time with Max Pooling-based architecture with 0.620. As a result, it has been observed that the sequence models compare performances close to each other.
翻译:情感识别已成为人机交互领域的重要研究方向。现有基于音频与视频的情感理解研究主要聚焦于面部表情分析,并对六种基本情绪进行分类。本研究比较了不同时序模型在多模态情感识别中的性能表现。首先采用多层CNN模型分别处理音频与图像数据,然后将这些模型的输出结果输入至各类时序模型中。所采用的时序模型包括GRU、Transformer、LSTM与最大池化(Max Pooling)。计算了所有模型的准确率、精确率及F1分数值。实验采用多模态CREMA-D数据集。基于CREMA-D数据集的比较结果显示:基于GRU的架构在F1分数指标上取得0.640的最佳结果,基于LSTM的架构在精确率指标上达到0.699,而基于最大池化的架构在敏感度指标上以0.620的数值展现出最优的时序性能。结果表明,各时序模型的表现较为接近。