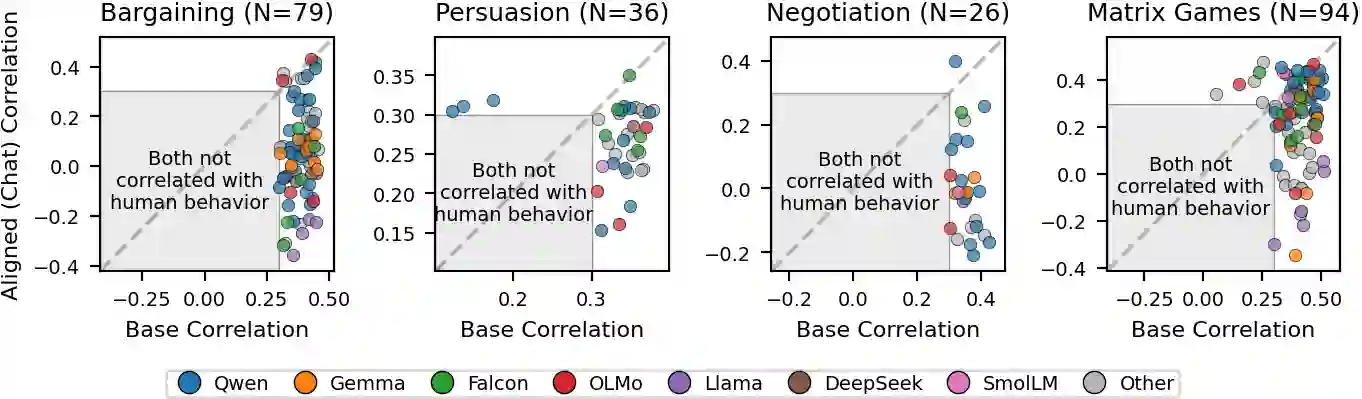
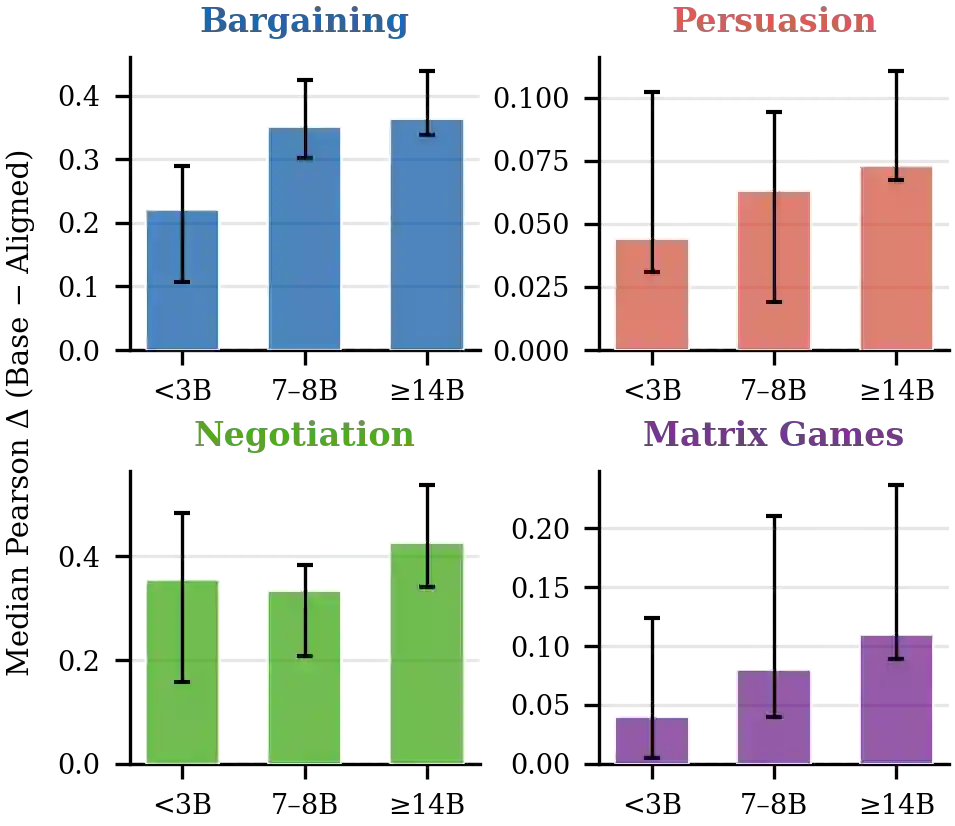
Post-training alignment optimizes language models to match human preference signals, but this objective is not equivalent to modeling observed human behavior. We compare 120 base-aligned model pairs on more than 10,000 real human decisions in multi-round strategic games - bargaining, persuasion, negotiation, and repeated matrix games. In these settings, base models outperform their aligned counterparts in predicting human choices by nearly 10:1, robustly across model families, prompt formulations, and game configurations. This pattern reverses, however, in settings where human behavior is more likely to follow normative predictions: aligned models dominate on one-shot textbook games across all 12 types tested and on non-strategic lottery choices - and even within the multi-round games themselves, at round one, before interaction history develops. This boundary-condition pattern suggests that alignment induces a normative bias: it improves prediction when human behavior is relatively well captured by normative solutions, but hurts prediction in multi-round strategic settings, where behavior is shaped by descriptive dynamics such as reciprocity, retaliation, and history-dependent adaptation. These results reveal a fundamental trade-off between optimizing models for human use and using them as proxies for human behavior.
翻译:后训练对齐优化语言模型以匹配人类偏好信号,但该目标并不等同于对人类实际行为的建模。我们在多轮策略博弈(议价、说服、谈判及重复矩阵博弈)中,基于超过10,000条真实人类决策数据,比较了120组基础模型与对齐模型对。在这些场景中,基础模型在预测人类选择方面以近10:1的优势持续优于其对应对齐模型,该结果在不同模型族、提示词构建方式和博弈配置中均保持稳健。然而,在人类行为更可能遵循规范性预测的场景中,这种模式发生逆转:对齐模型在所有12种测试的单次教科书博弈及非策略性彩票选择任务中均占主导地位——甚至在多轮博弈内部的第一轮(交互历史尚未形成时)亦如此。这种边界条件模式表明,对齐会引发规范性偏差:当人类行为相对符合规范性解决方案时,对齐能提升预测性能;但在多轮策略场景中,当行为受互惠、报复及历史依赖适应等描述性动态机制影响时,对齐反而会损害预测准确性。这些结果揭示了优化模型以供人类使用与将其作为人类行为代理之间的根本性权衡。