
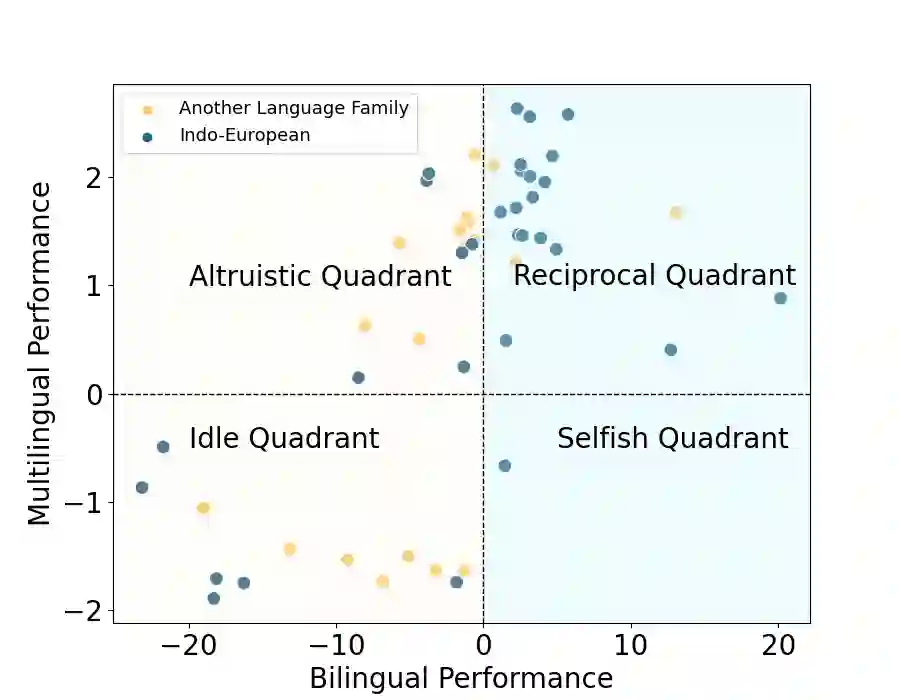
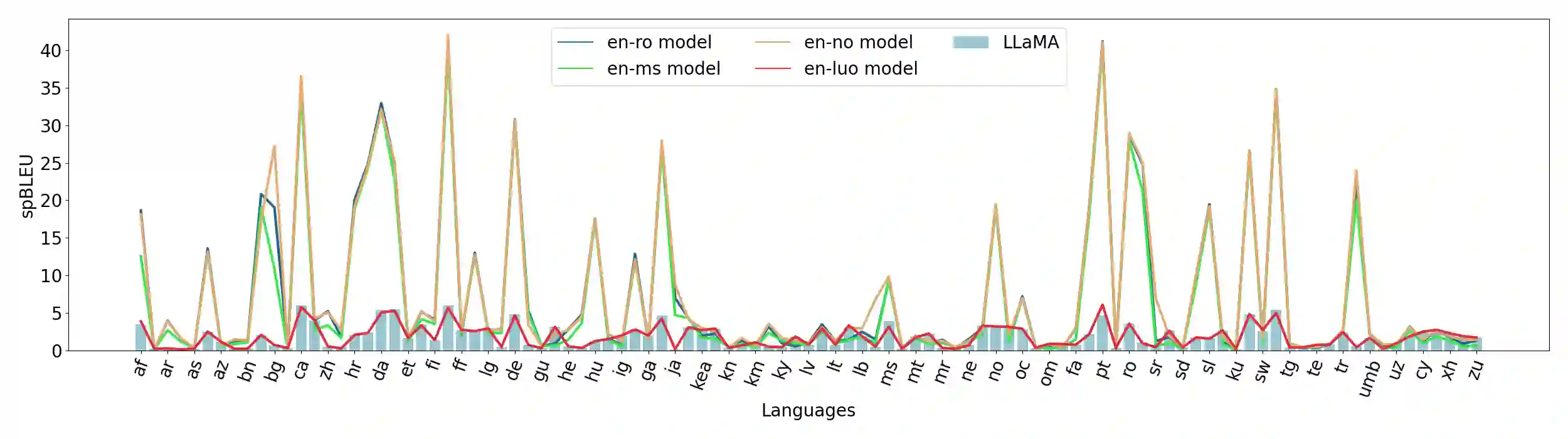
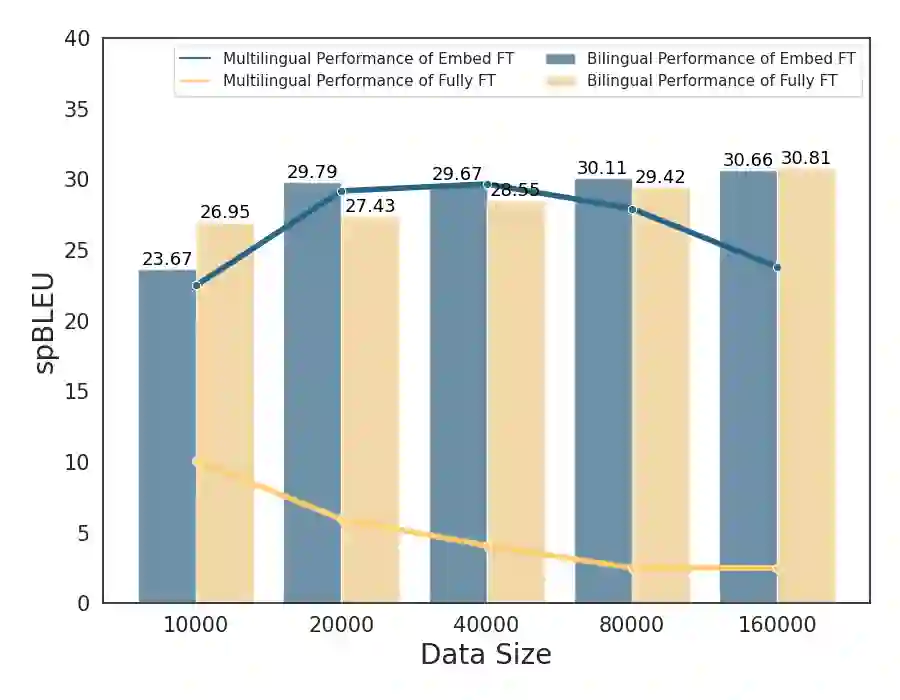
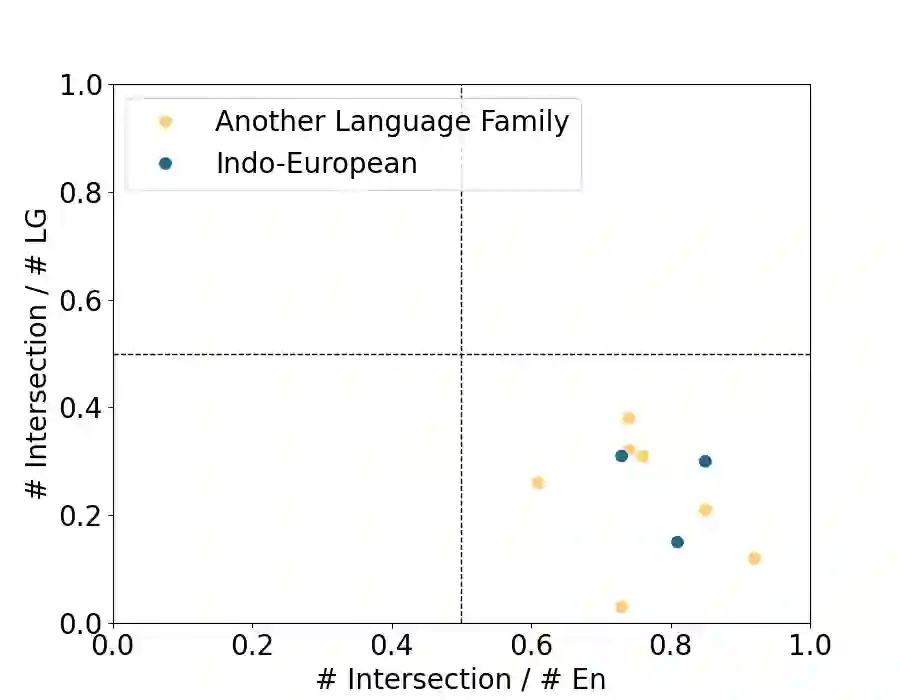
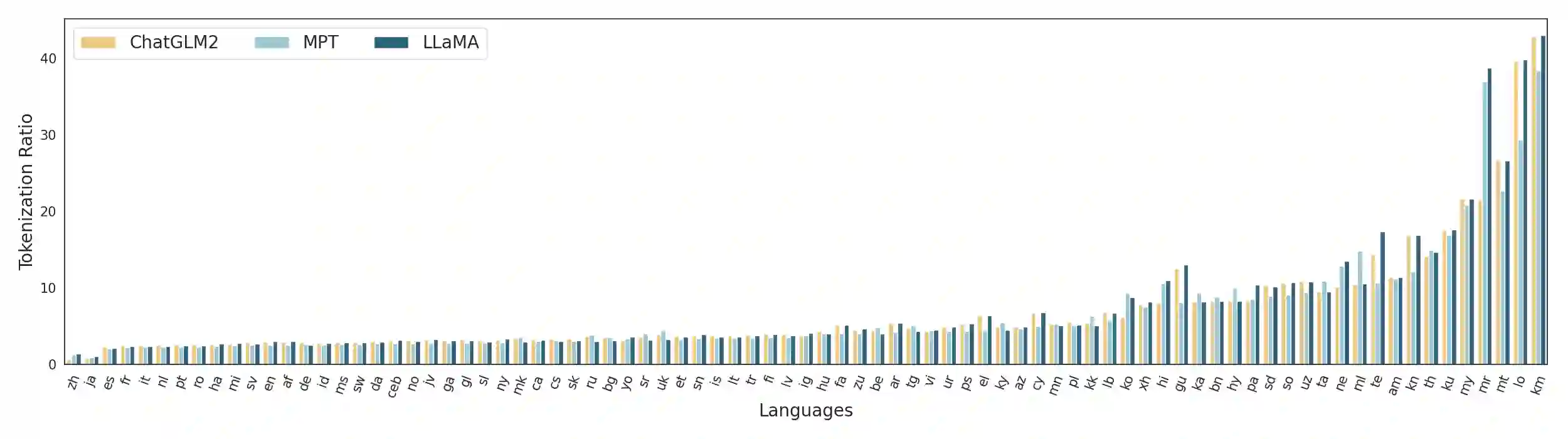
Large Language Models (LLMs), trained predominantly on extensive English data, often exhibit limitations when applied to other languages. Current research is primarily focused on enhancing the multilingual capabilities of these models by employing various tuning strategies. Despite their effectiveness in certain languages, the understanding of the multilingual abilities of LLMs remains incomplete. This study endeavors to evaluate the multilingual capacity of LLMs by conducting an exhaustive analysis across 101 languages, and classifies languages with similar characteristics into four distinct quadrants. By delving into each quadrant, we shed light on the rationale behind their categorization and offer actionable guidelines for tuning these languages. Extensive experiments reveal that existing LLMs possess multilingual capabilities that surpass our expectations, and we can significantly improve the multilingual performance of LLMs by focusing on these distinct attributes present in each quadrant.
翻译:大型语言模型(LLMs)主要基于大量英语数据进行训练,在应用于其他语言时往往表现出局限性。当前研究主要通过采用各种调优策略来增强这些模型的多语言能力。尽管这些方法在某些语言上效果显著,但对LLMs多语言能力的理解仍不完整。本研究旨在通过对101种语言的全面分析来评估LLMs的多语言能力,并将具有相似特征的语言划分为四个不同的象限。通过深入探究每个象限,我们阐明了分类背后的逻辑,并为这些语言的调优提供了可操作指南。大量实验表明,现有LLMs具备超出预期的多语言能力,通过关注每个象限中存在的独特属性,我们可以显著提升LLMs的多语言表现。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

