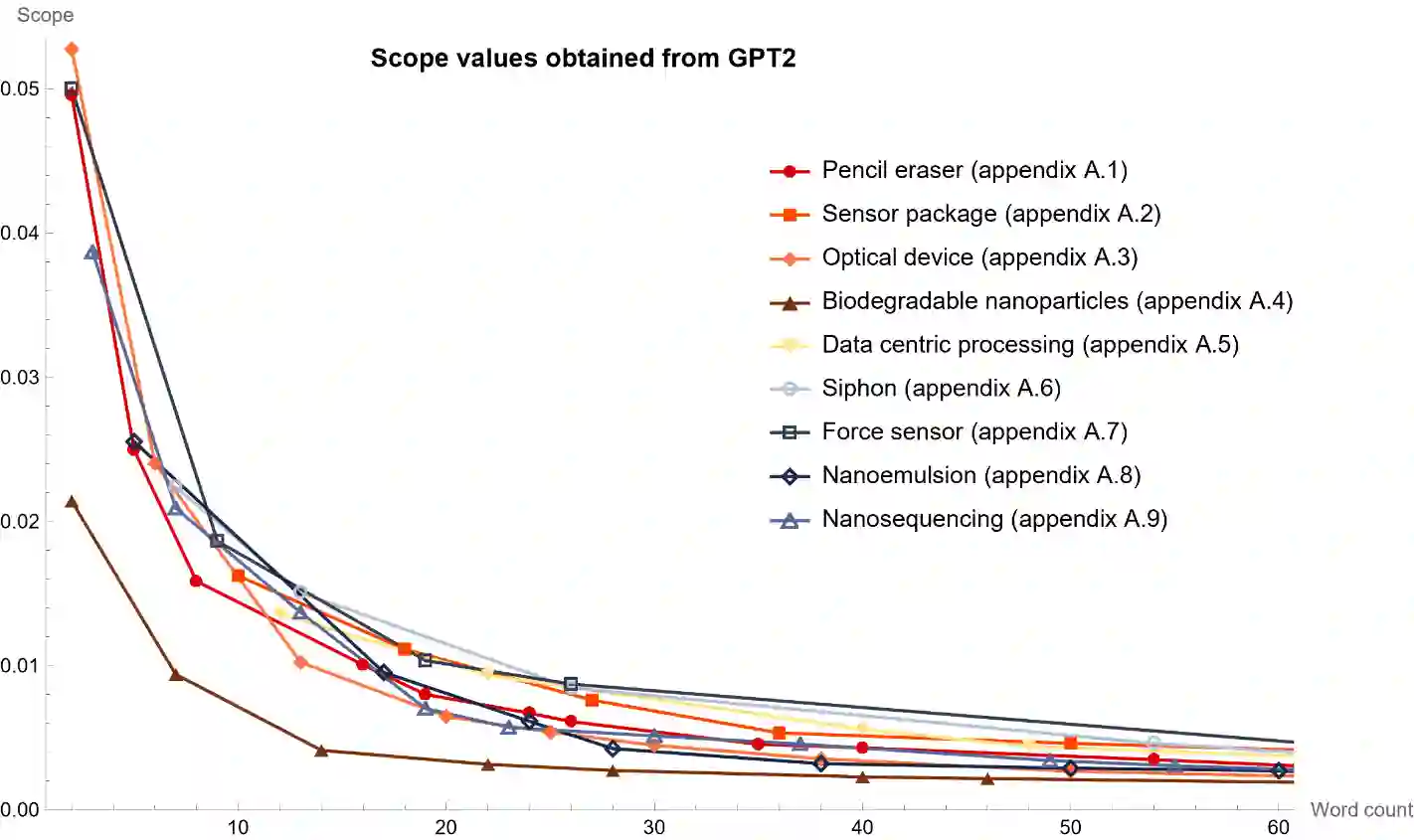
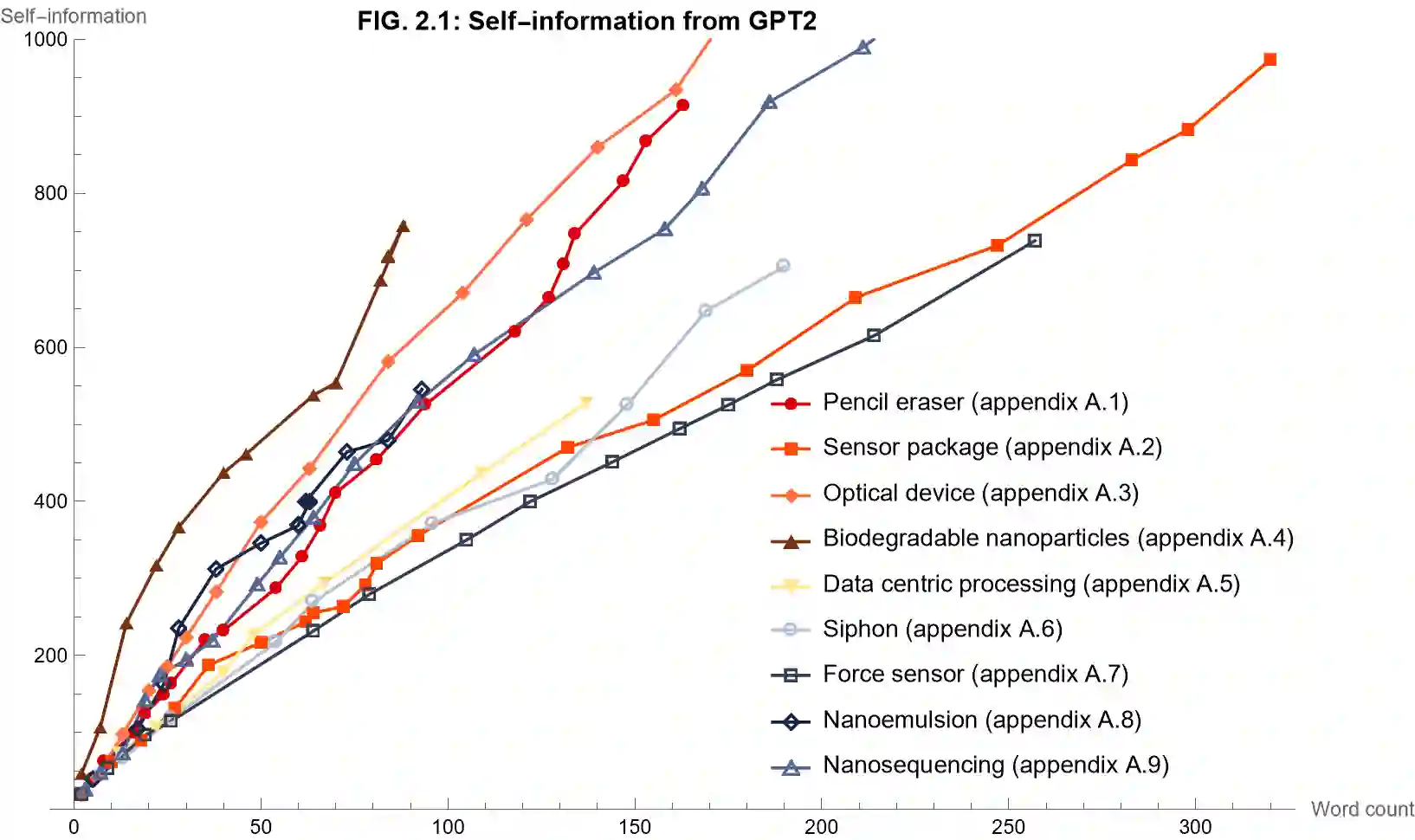
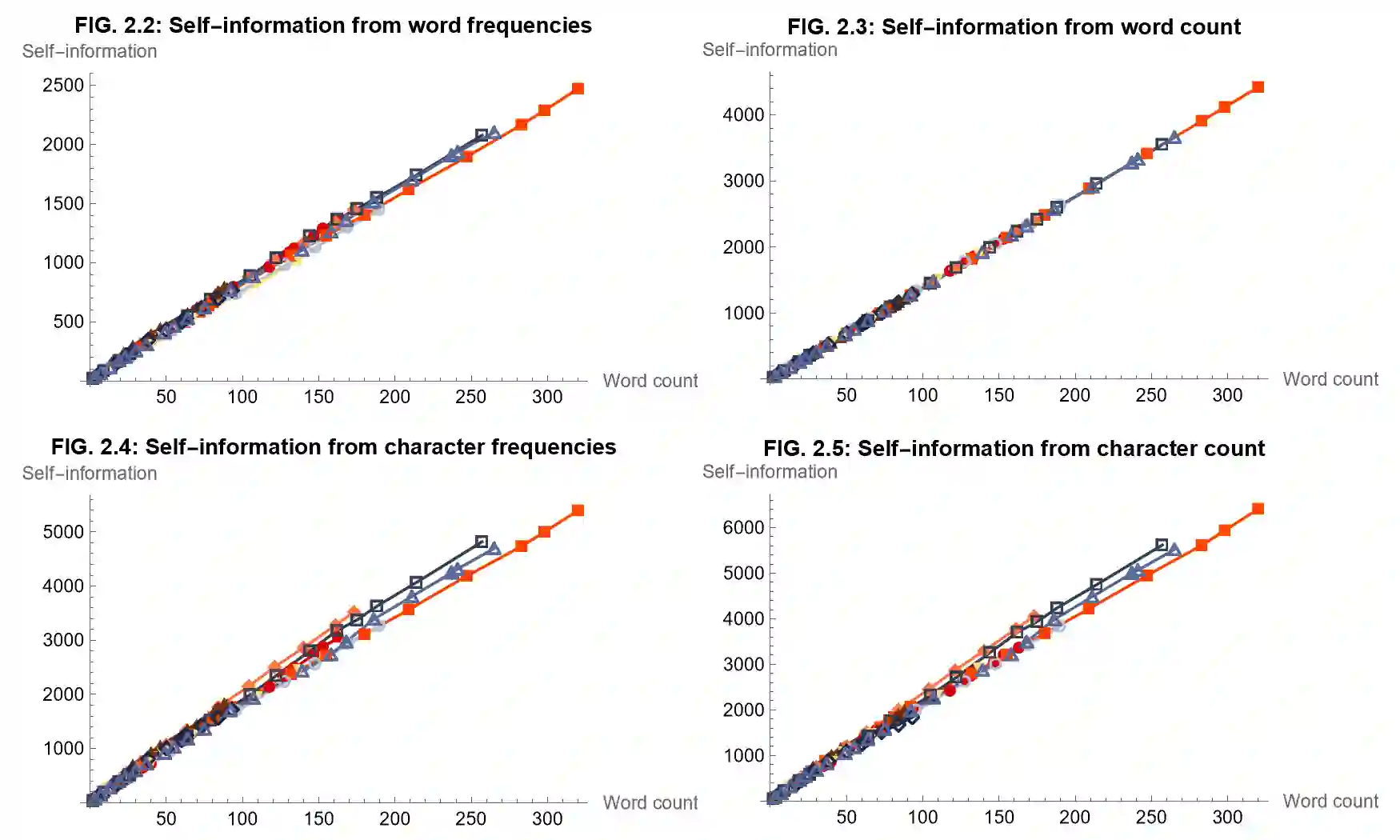
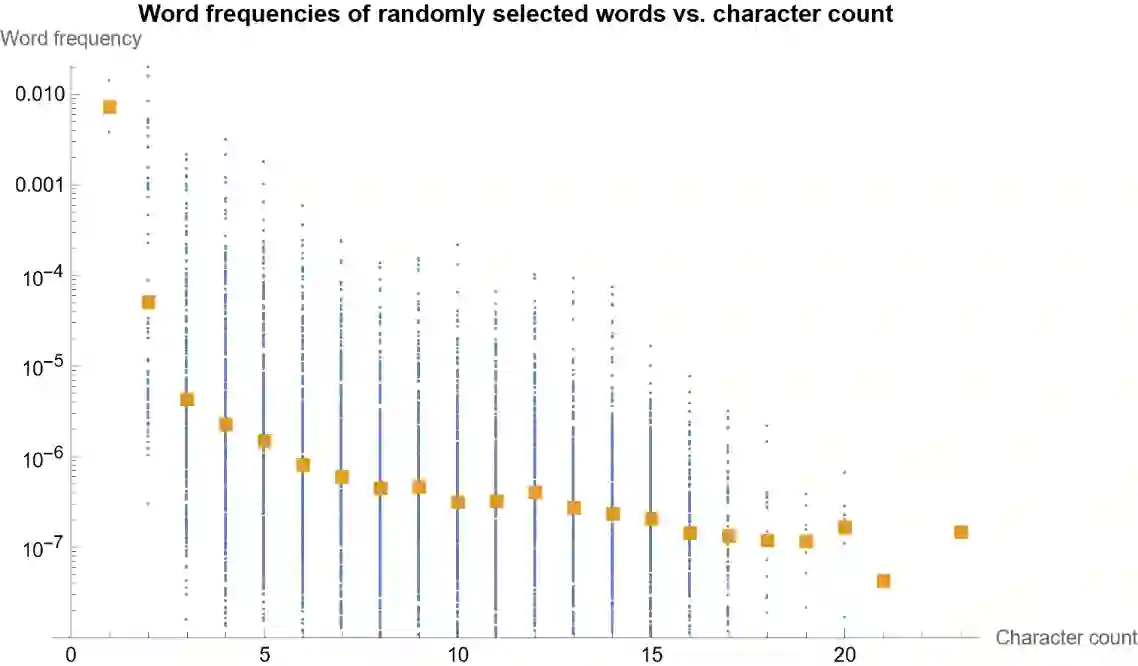
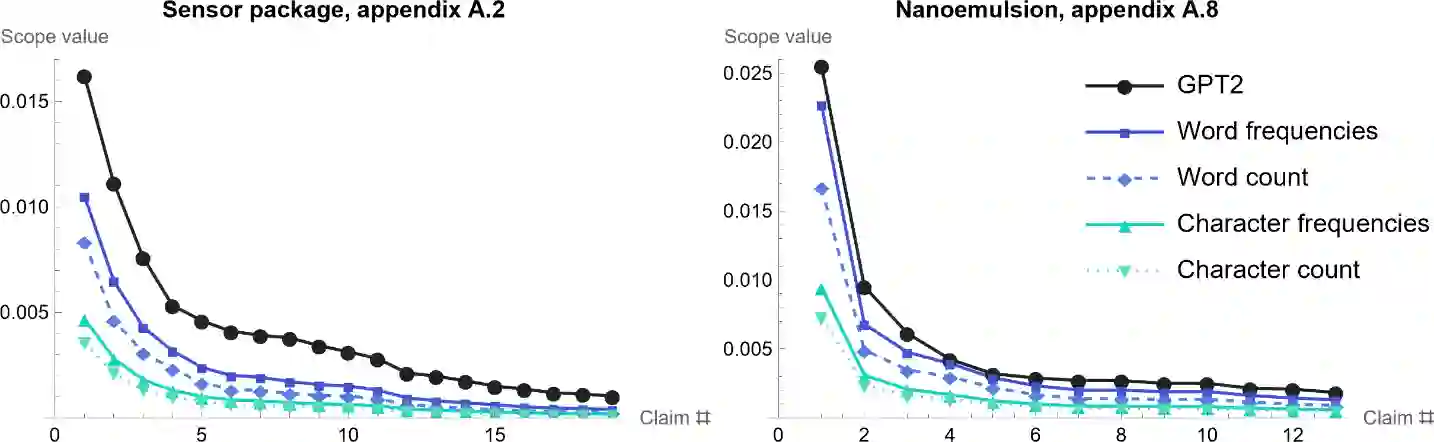
This work proposes to measure the scope of a patent claim as the reciprocal of the self-information contained in this claim. A probability of occurrence of the claim is obtained from a language model and this probability is used to compute the self-information. Grounded in information theory, this approach is based on the assumption that an unlikely concept is more informative than a usual concept, insofar as it is more surprising. In turn, the more surprising the information required to defined the claim, the narrower its scope. Five language models are considered, ranging from simplest models (each word or character is assigned an identical probability) to intermediate models (using average word or character frequencies), to a large language model (GPT2). Interestingly, the scope resulting from the simplest language models is proportional to the reciprocal of the number of words or characters involved in the claim, a metric already used in previous works. Application is made to multiple series of patent claims directed to distinct inventions, where each series consists of claims devised to have a gradually decreasing scope. The performance of the language models is assessed with respect to several ad hoc tests. The more sophisticated the model, the better the results. I.e., the GPT2 probability model outperforms models based on word and character frequencies, which themselves outdo the simplest models based on word or character counts. Still, the character count appears to be a more reliable indicator than the word count.
翻译:本文提出以专利权利要求中包含的自信息量的倒数作为其范围的度量标准。通过语言模型获取权利要求的出现概率,并据此计算自信息量。该研究方法基于信息论,其核心假设是:非常见概念比常规概念包含更多信息,因其呈现更高的意外性。相应地,定义权利要求所需信息的意外程度越高,其保护范围就越窄。研究比较了五种语言模型:从最简单模型(赋予每个单词或字符相同概率)、中间模型(采用平均词频或字符频率)到大型语言模型(GPT2)。值得注意的是,最简单语言模型所得范围与权利要求包含的单词或字符数量成反比——这一度量指标此前已有应用。通过对多组针对不同发明的专利权利要求系列(每组均包含范围逐渐缩减的权利要求)进行实证分析,并采用多项特定测试评估各模型表现,结果表明:模型越复杂,效果越优。即GPT2概率模型优于基于词频和字符频率的模型,而后者又优于基于单词或字符计数的最简单模型。尽管如此,字符计数仍是比单词计数更可靠的指标。