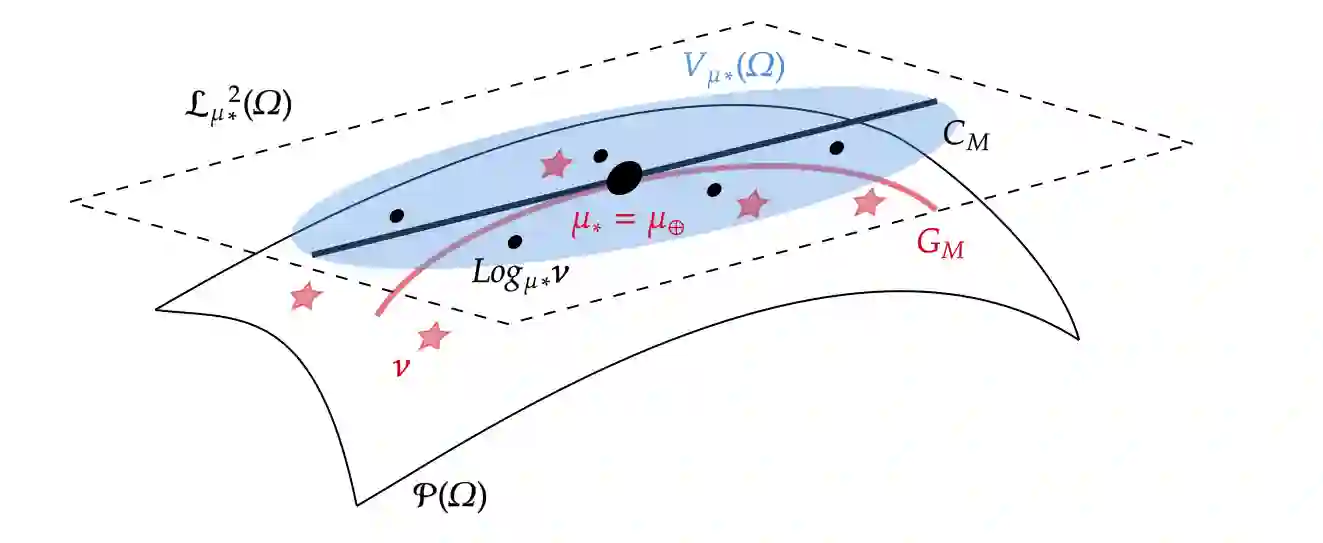
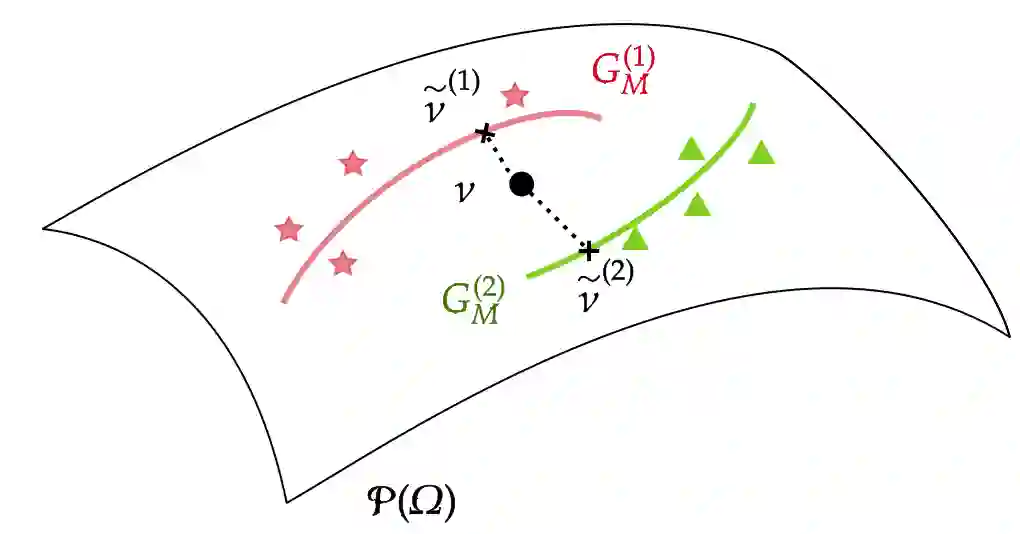
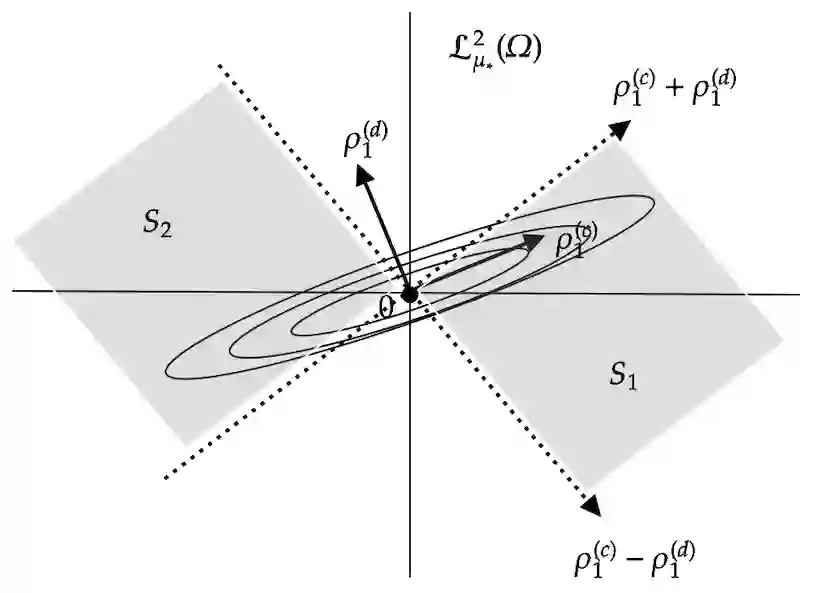
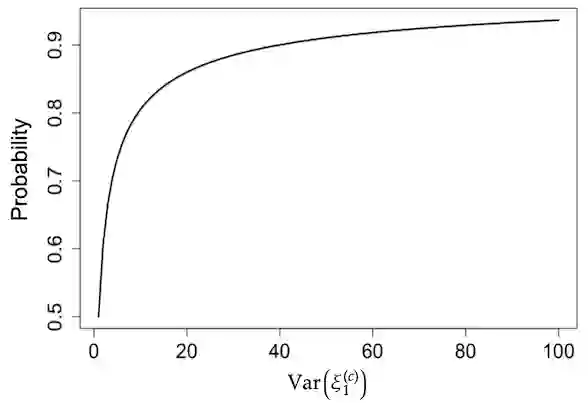
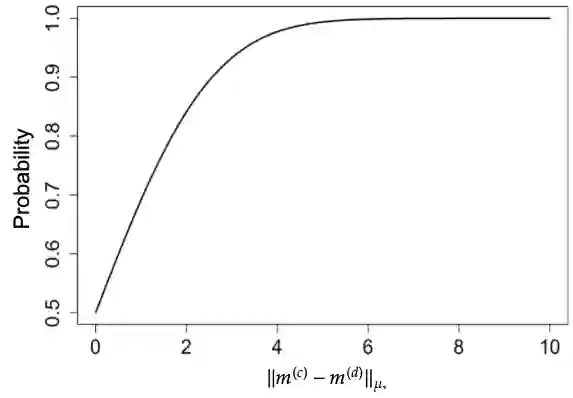
We develop a novel clustering method for distributional data, where each data point is regarded as a probability distribution on the real line. For distributional data, it has been challenging to develop a clustering method that utilizes the mode of variation of data because the space of probability distributions lacks a vector space structure, preventing the application of existing methods for functional data. In this study, we propose a novel clustering method for distributional data on the real line, which takes account of difference in both the mean and mode of variation structures of clusters, in the spirit of the $k$-centres clustering approach proposed for functional data. Specifically, we consider the space of distributions equipped with the Wasserstein metric and define a geodesic mode of variation of distributional data using geodesic principal component analysis. Then, we utilize the geodesic mode of each cluster to predict the cluster membership of each distribution. We theoretically show the validity of the proposed clustering criterion by studying the probability of correct membership. Through a simulation study and real data application, we demonstrate that the proposed distributional clustering method can improve cluster quality compared to conventional clustering algorithms.
翻译:本文提出了一种针对分布数据的新型聚类方法,其中每个数据点被视为实数轴上的概率分布。对于分布数据,开发一种能够利用数据变异模式的聚类方法一直具有挑战性,因为概率分布空间缺乏向量空间结构,阻碍了现有函数型数据方法的直接应用。本研究受函数型数据$k$中心聚类方法的启发,提出一种针对实数轴上分布数据的新型聚类方法,该方法同时考虑聚类均值结构与变异模式结构的差异。具体而言,我们考虑配备Wasserstein度量的分布空间,并利用测地主成分分析定义分布数据的测地变异模式。随后,利用各聚类的测地模式预测每个分布的聚类归属。通过研究正确归属概率,我们从理论上证明了所提聚类准则的有效性。通过模拟研究和实际数据应用,我们证明与传统的聚类算法相比,所提出的分布聚类方法能够提升聚类质量。