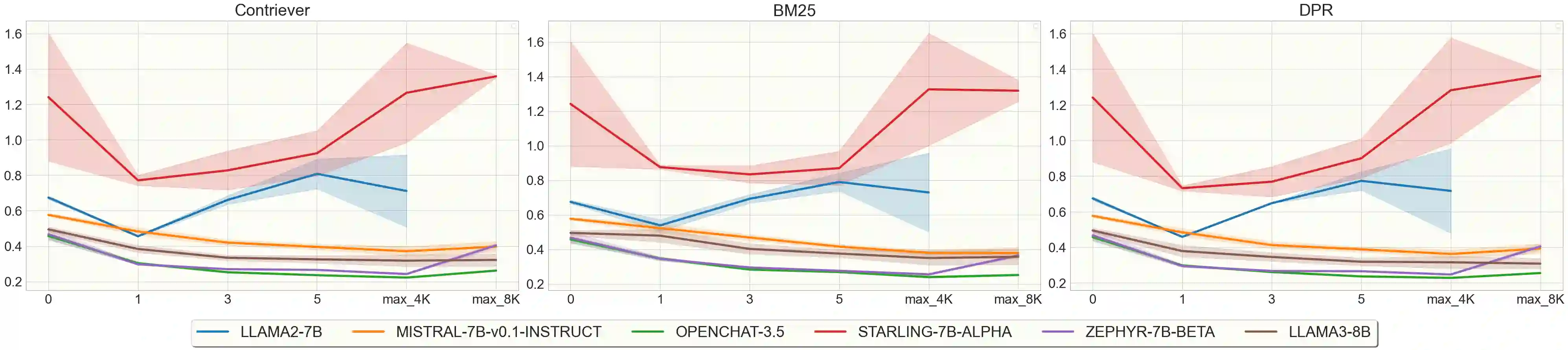
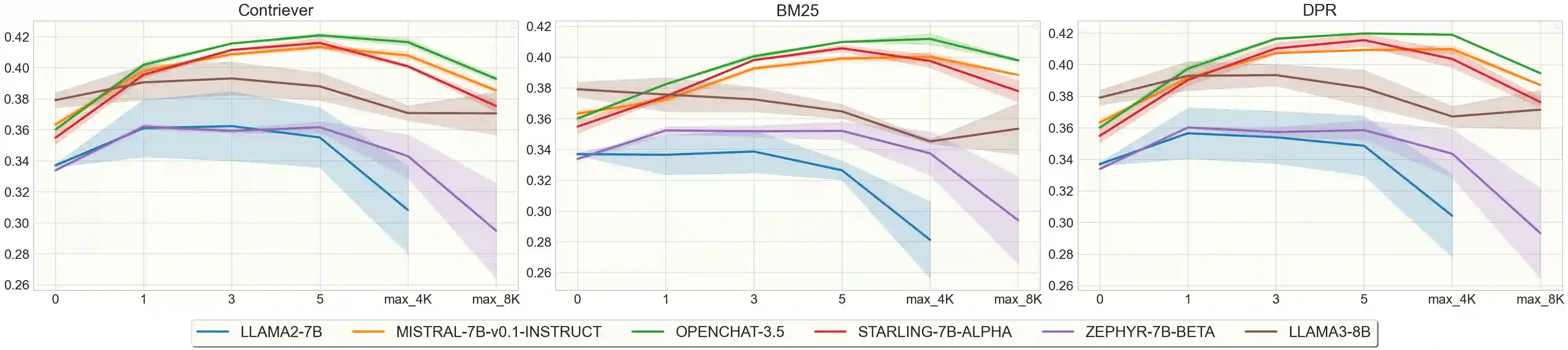
Post-training quantization reduces the computational demand of Large Language Models (LLMs) but can weaken some of their capabilities. Since LLM abilities emerge with scale, smaller LLMs are more sensitive to quantization. In this paper, we explore how quantization affects smaller LLMs' ability to perform retrieval-augmented generation (RAG), specifically in longer contexts. We chose personalization for evaluation because it is a challenging domain to perform using RAG as it requires long-context reasoning over multiple documents. We compare the original FP16 and the quantized INT4 performance of multiple 7B and 8B LLMs on two tasks while progressively increasing the number of retrieved documents to test how quantized models fare against longer contexts. To better understand the effect of retrieval, we evaluate three retrieval models in our experiments. Our findings reveal that if a 7B LLM performs the task well, quantization does not impair its performance and long-context reasoning capabilities. We conclude that it is possible to utilize RAG with quantized smaller LLMs.
翻译:后训练量化降低了大型语言模型(LLMs)的计算需求,但可能削弱其部分能力。由于LLM的能力随规模涌现,小型LLMs对量化更为敏感。本文探讨量化如何影响小型LLMs执行检索增强生成(RAG)的能力,特别是在长上下文场景中。我们选择个性化任务进行评估,因为这是使用RAG执行具有挑战性的领域,需要对多篇文档进行长上下文推理。我们比较了多个7B和8B LLMs在原始FP16和量化INT4下的性能,通过逐步增加检索文档数量来测试量化模型在更长上下文中的表现。为了更好地理解检索的影响,我们在实验中评估了三种检索模型。研究结果表明,若一个7B LLM能良好执行任务,量化不会损害其性能和长上下文推理能力。我们得出结论:量化的小型LLMs能够有效利用RAG。