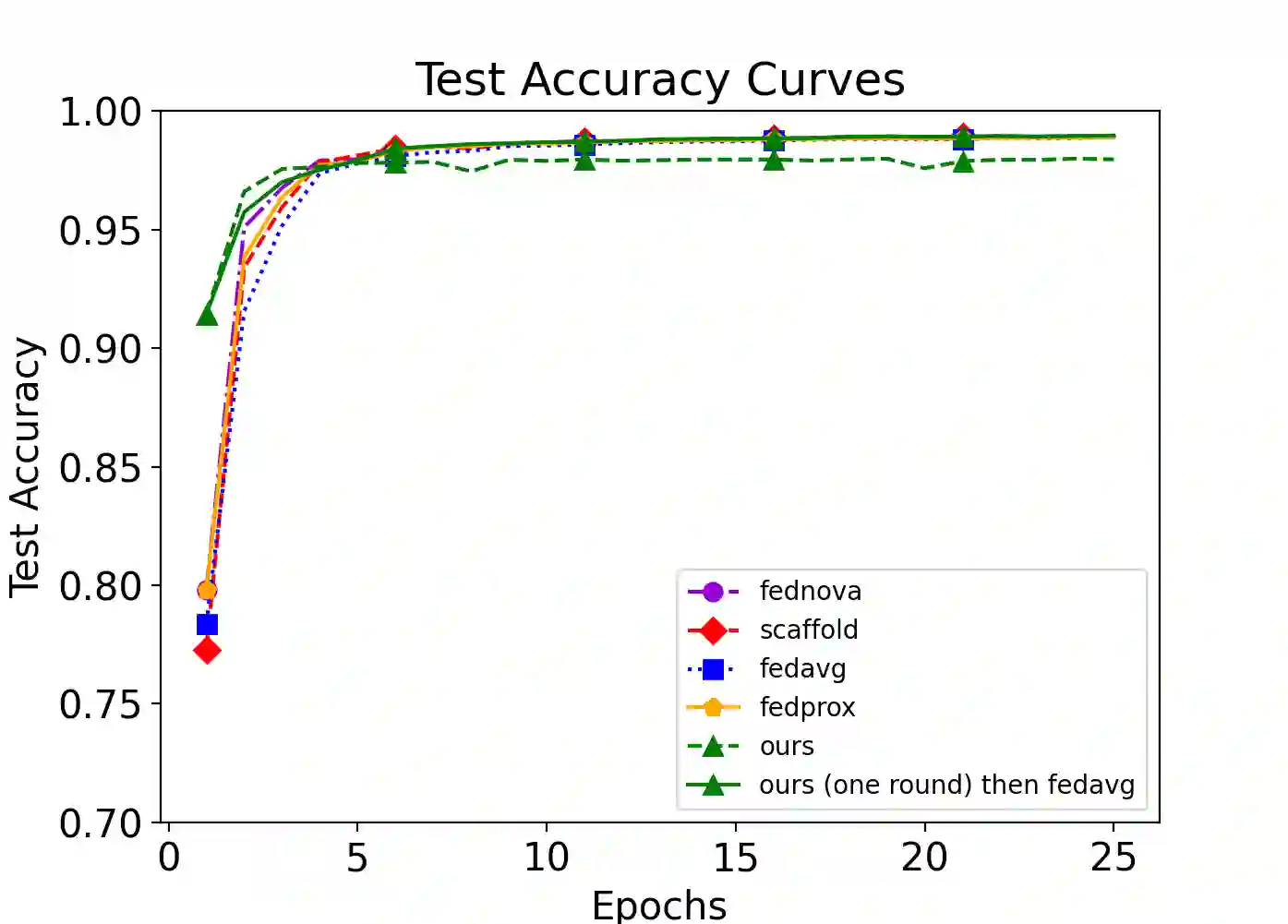
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing communication overhead, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with layer-wise posterior aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any private label information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
翻译:在联邦学习中,如何高效地将客户端本地训练好的神经网络聚合为服务器端的全局模型是广泛研究的重要课题。近年来,受隐私顾虑减少、潜在攻击缓解以及通信开销降低等动因驱动,单次联邦学习(即限制客户端与服务器之间仅进行一轮通信)逐渐受到研究者的青睐。然而,单次聚合性能极易受非相同训练数据分布的影响,而在实际场景中这种分布常表现出高度统计异质性。为解决该问题,我们提出了一种新颖的单次聚合方法——基于层级后验聚合的FedLPA。该方法无需额外辅助数据集或暴露任何私有标签信息(如标签分布),即可通过聚合局部模型获得更准确的全局模型。为了有效捕捉实际非独立同分布场景中有偏局部数据集所蕴含的统计特征,我们利用层级拉普拉斯近似高效推断每个局部模型中各层参数的后验分布,并通过聚合这些后验分布来训练全局参数。大量实验结果表明,FedLPA在多类评估指标上均显著超越了现有最优方法的学习性能。