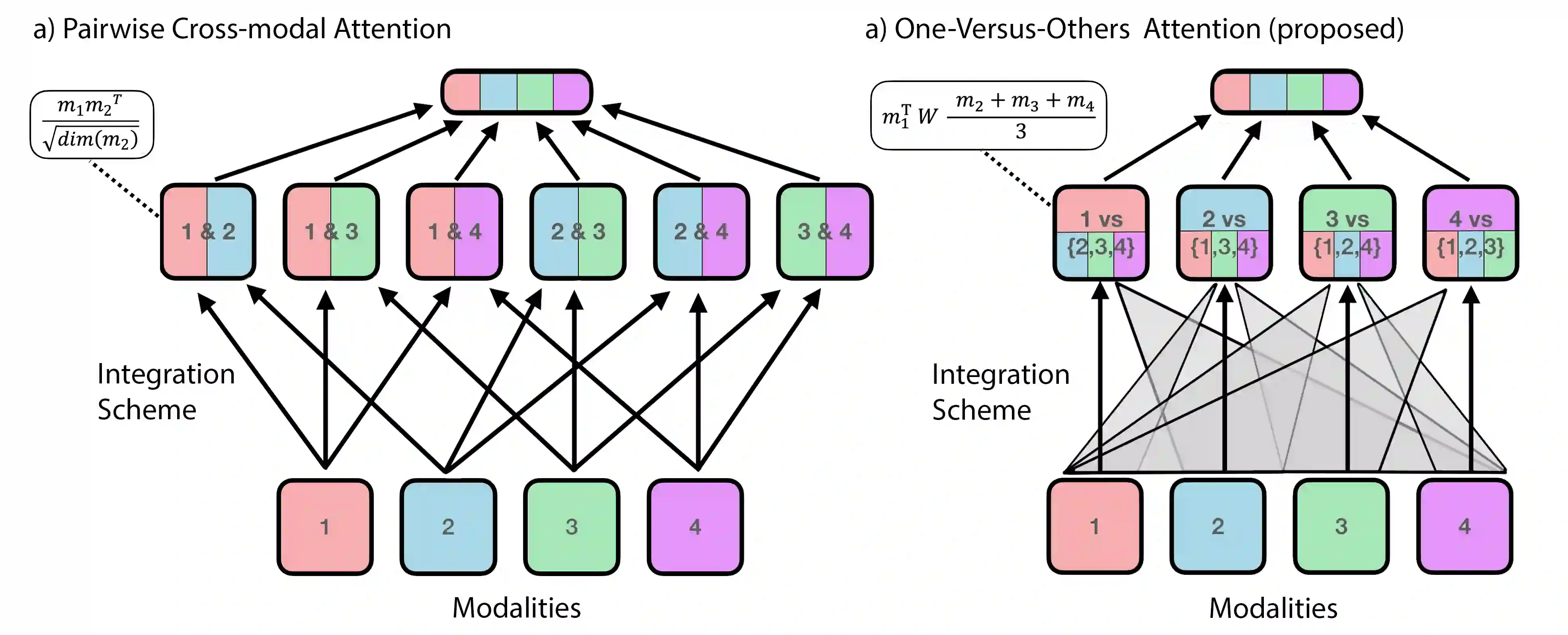
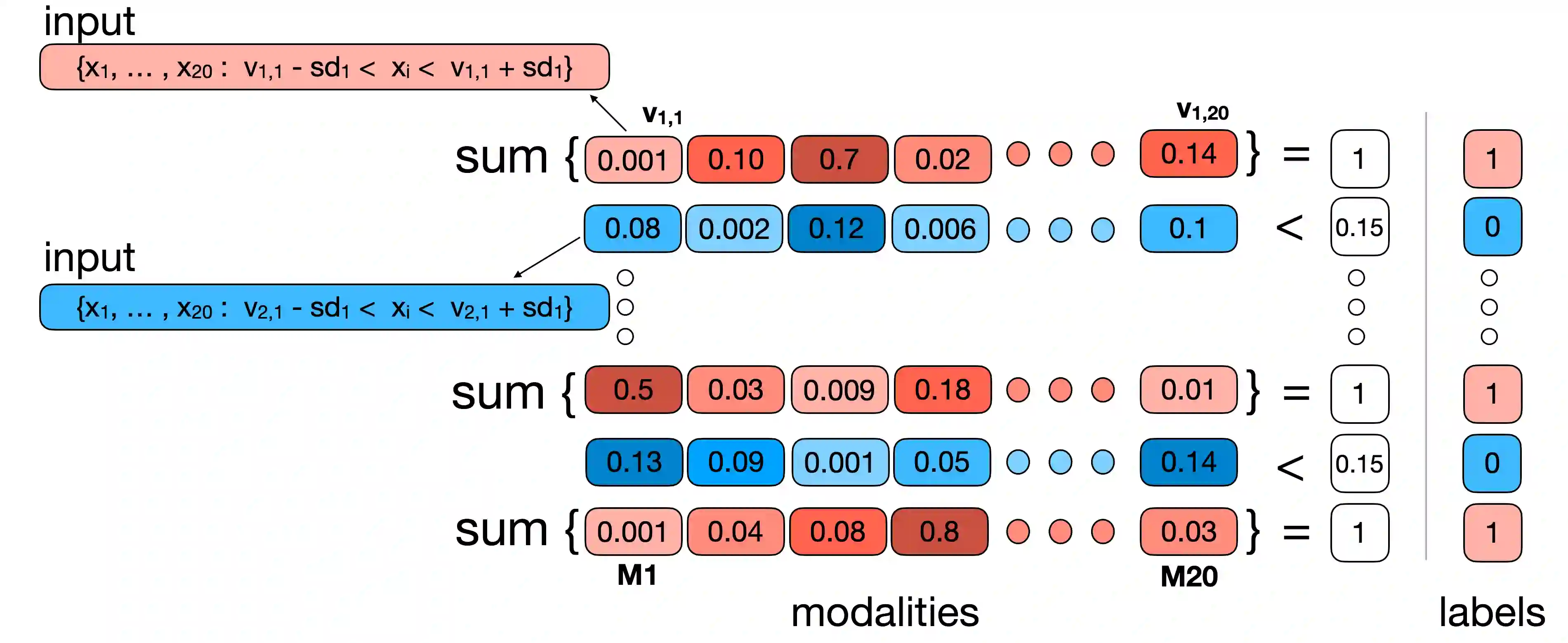
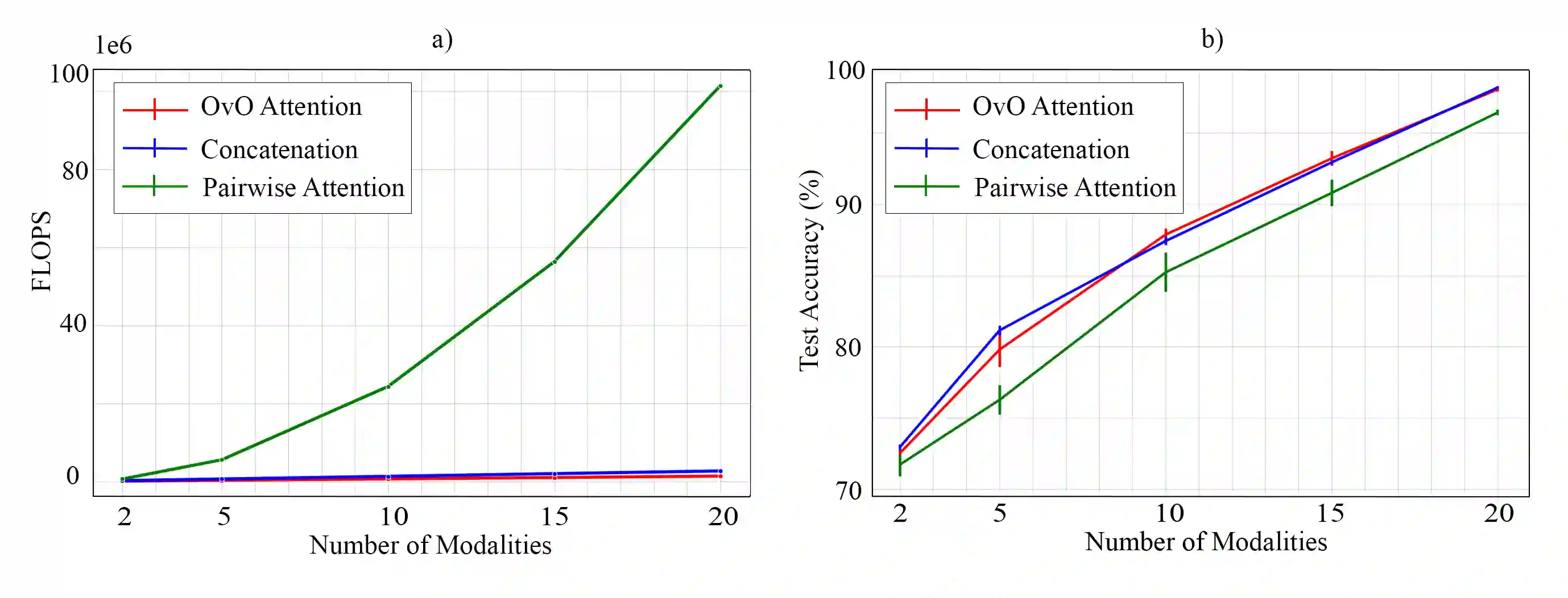
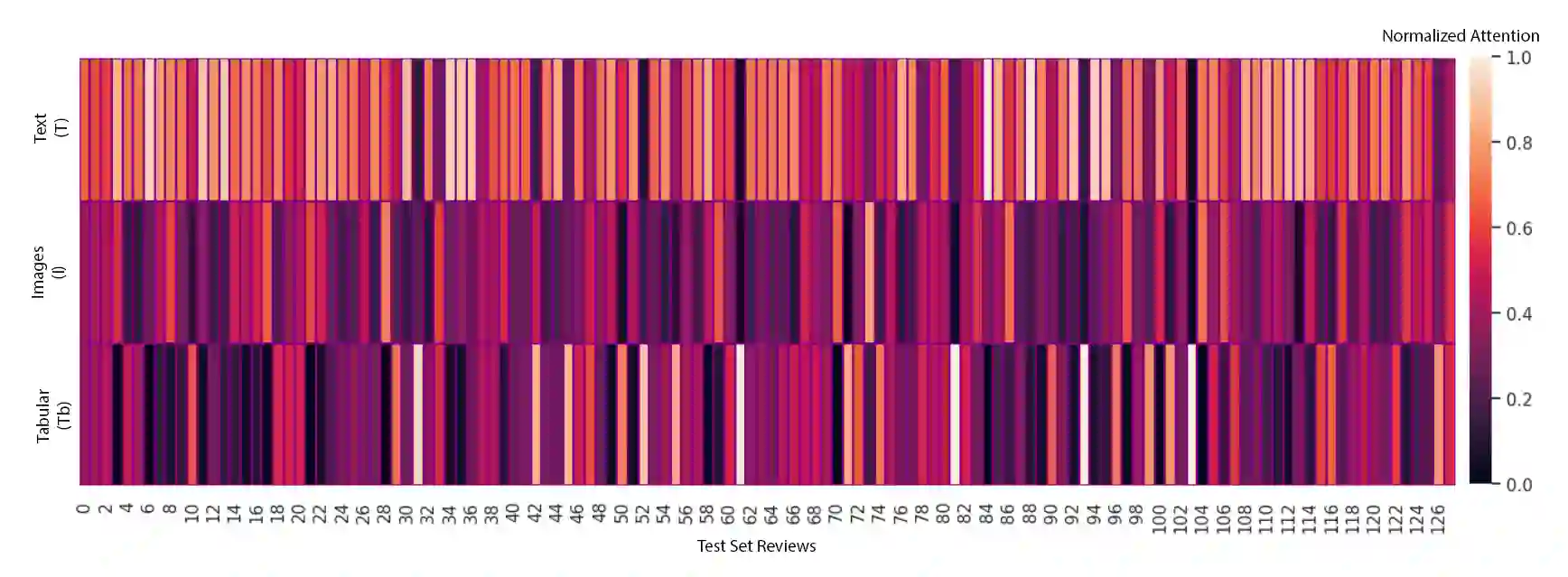
Multimodal learning models have become increasingly important as they surpass single-modality approaches on diverse tasks ranging from question-answering to autonomous driving. Despite the importance of multimodal learning, existing efforts focus on NLP applications, where the number of modalities is typically less than four (audio, video, text, images). However, data inputs in other domains, such as the medical field, may include X-rays, PET scans, MRIs, genetic screening, clinical notes, and more, creating a need for both efficient and accurate information fusion. Many state-of-the-art models rely on pairwise cross-modal attention, which does not scale well for applications with more than three modalities. For $n$ modalities, computing attention will result in $n \choose 2$ operations, potentially requiring considerable amounts of computational resources. To address this, we propose a new domain-neutral attention mechanism, One-Versus-Others (OvO) attention, that scales linearly with the number of modalities and requires only $n$ attention operations, thus offering a significant reduction in computational complexity compared to existing cross-modal attention algorithms. Using three diverse real-world datasets as well as an additional simulation experiment, we show that our method improves performance compared to popular fusion techniques while decreasing computation costs.
翻译:多模态学习模型因其在从问答到自动驾驶等多种任务中超越单模态方法而变得日益重要。尽管多模态学习具有重要意义,但现有研究主要聚焦于自然语言处理应用,其中模态数量通常少于四种(音频、视频、文本、图像)。然而,其他领域的数据输入,例如医学领域,可能包括X光片、PET扫描、MRI、基因筛查、临床记录等,因此需要高效且准确的信息融合。许多最先进的模型依赖于成对跨模态注意力,这在模态数量超过三种的应用中扩展性不佳。对于$n$种模态,计算注意力将产生$\binom{n}{2}$次操作,可能消耗大量计算资源。为解决这一问题,我们提出了一种新的领域无关注意力机制——一对多(OvO)注意力,其计算复杂度随模态数量线性增长,仅需$n$次注意力操作,从而相比现有跨模态注意力算法显著降低了计算复杂度。通过使用三个不同的真实世界数据集以及一项额外的模拟实验,我们展示了该方法在降低计算成本的同时,相比流行的融合技术提升了性能。