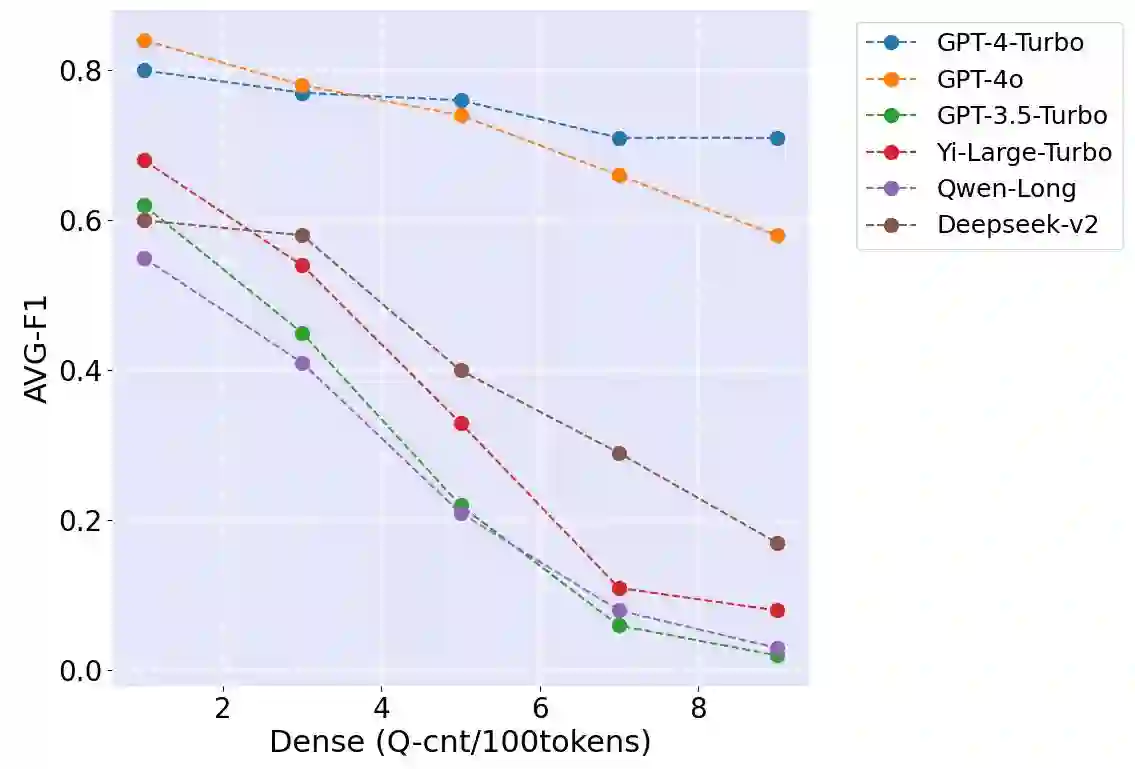
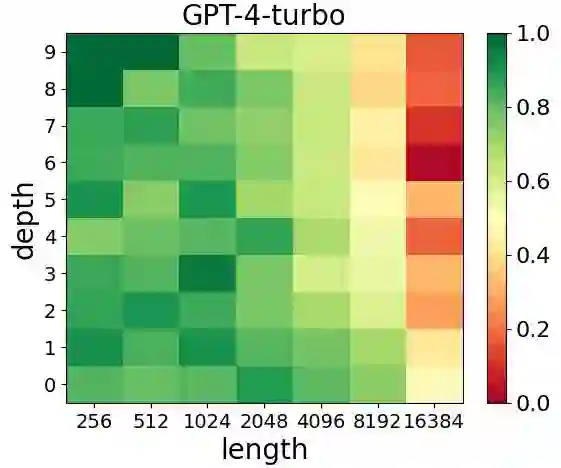
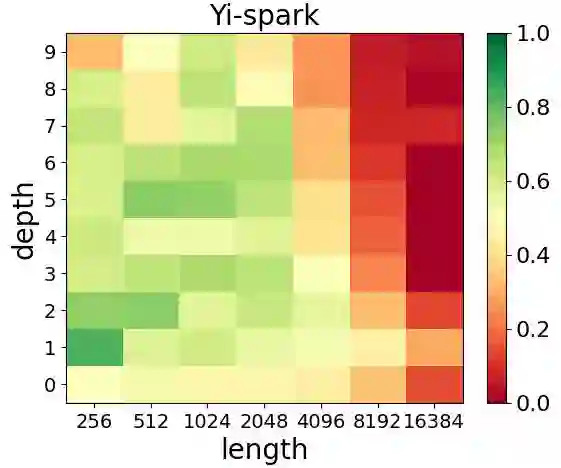
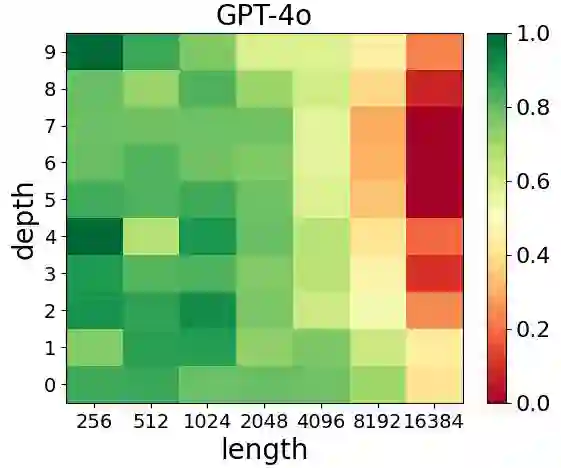
The long-context capabilities of large language models (LLMs) have been a hot topic in recent years. To evaluate the performance of LLMs in different scenarios, various assessment benchmarks have emerged. However, as most of these benchmarks focus on identifying key information to answer questions, which mainly requires the retrieval ability of LLMs, these benchmarks can partially represent the reasoning performance of LLMs from large amounts of information. Meanwhile, although LLMs often claim to have context windows of 32k, 128k, 200k, or even longer, these benchmarks fail to reveal the actual supported length of these LLMs. To address these issues, we propose the LongIns benchmark dataset, a challenging long-context instruction-based exam for LLMs, which is built based on the existing instruction datasets. Specifically, in our LongIns, we introduce three evaluation settings: Global Instruction & Single Task (GIST), Local Instruction & Single Task (LIST), and Local Instruction & Multiple Tasks (LIMT). Based on LongIns, we perform comprehensive evaluations on existing LLMs and have the following important findings: (1). The top-performing GPT-4 with 128k context length performs poorly on the evaluation context window of 16k in our LongIns. (2). For the multi-hop reasoning ability of many existing LLMs, significant efforts are still needed under short context windows (less than 4k).
翻译:近年来,大语言模型的长上下文处理能力已成为研究热点。为评估大语言模型在不同场景下的性能,各类评测基准相继涌现。然而,由于现有基准大多聚焦于通过关键信息检索回答问题,主要考察模型的检索能力,这些基准仅能部分反映大语言模型从海量信息中进行推理的性能。同时,尽管大语言模型常宣称支持32k、128k、200k甚至更长的上下文窗口,现有基准却难以揭示这些模型实际支持的有效长度。为应对这些问题,我们提出LongIns基准数据集——一个基于现有指令数据集构建的、具有挑战性的长上下文指令理解评测体系。具体而言,LongIns包含三种评估设置:全局指令单任务、局部指令单任务以及局部指令多任务。基于该基准,我们对现有大语言模型进行了全面评估,并获得以下重要发现:(1)在128k上下文窗口下表现最优的GPT-4模型,在LongIns的16k评估上下文窗口中表现欠佳;(2)对于多数现有大语言模型的多跳推理能力,在短上下文窗口(小于4k)下仍需显著提升。