
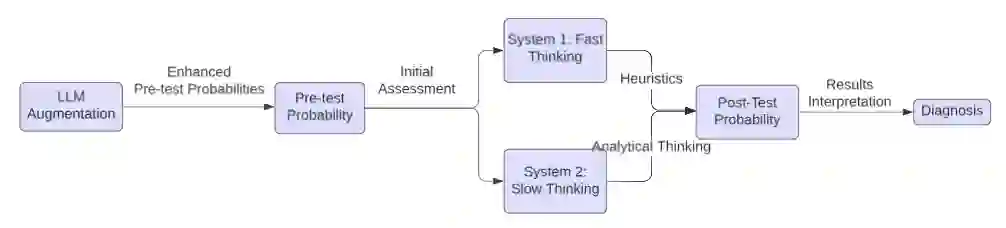
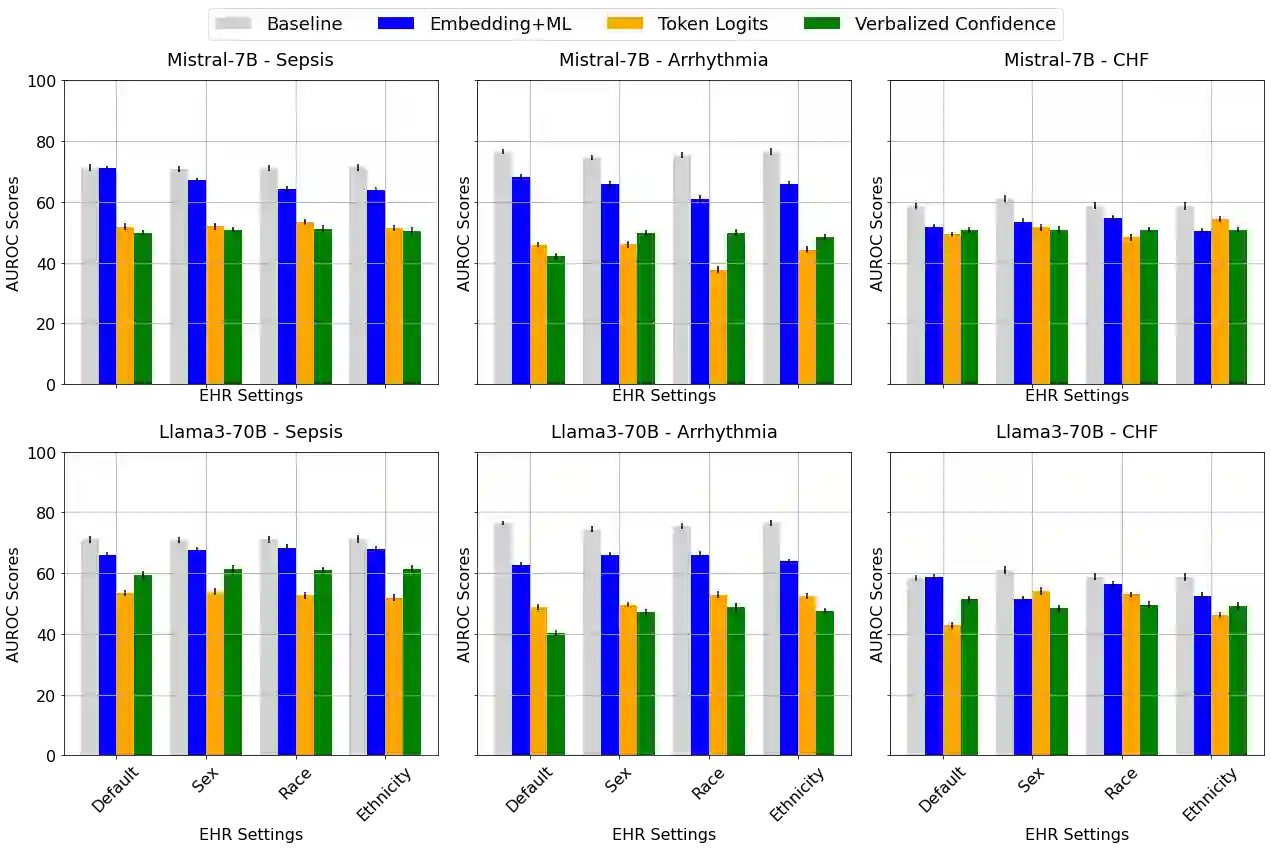
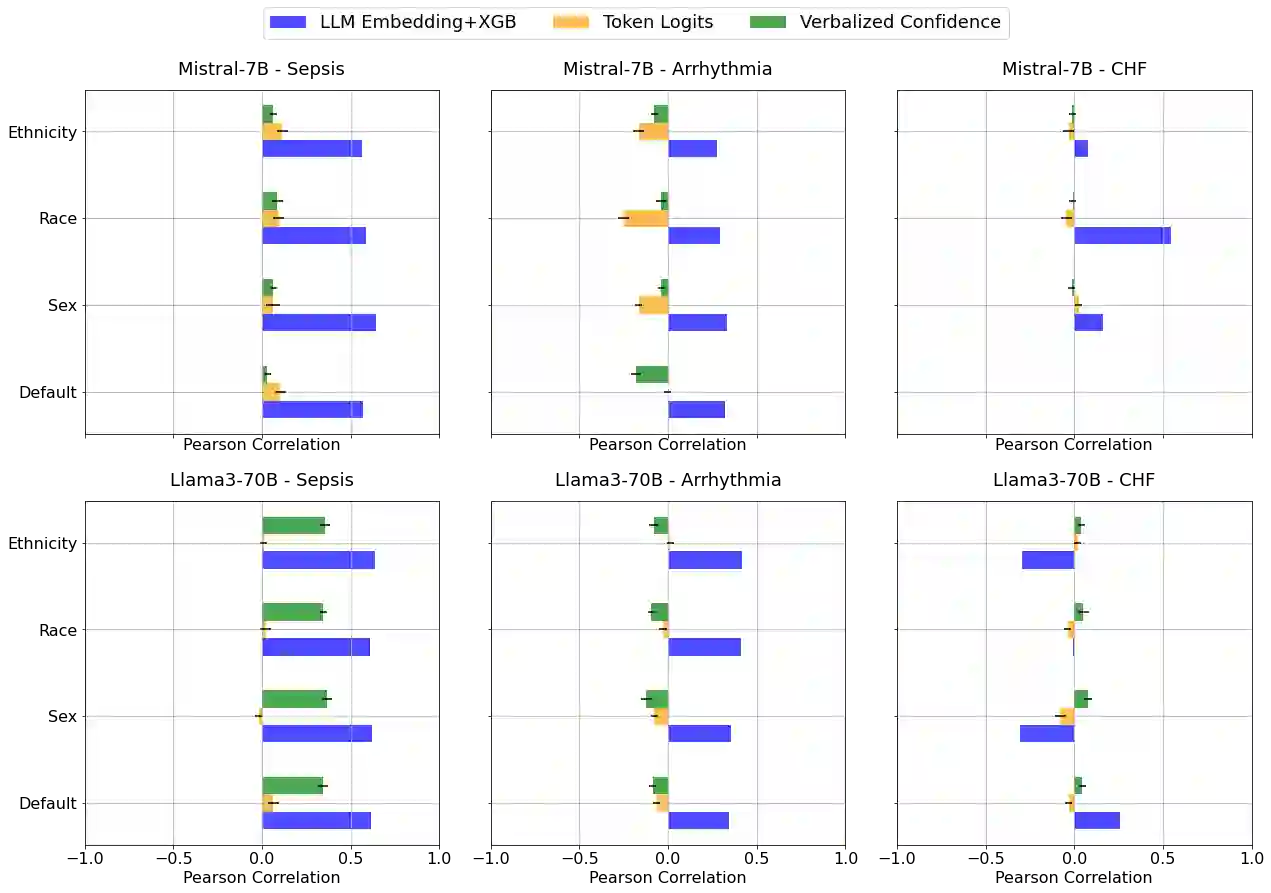
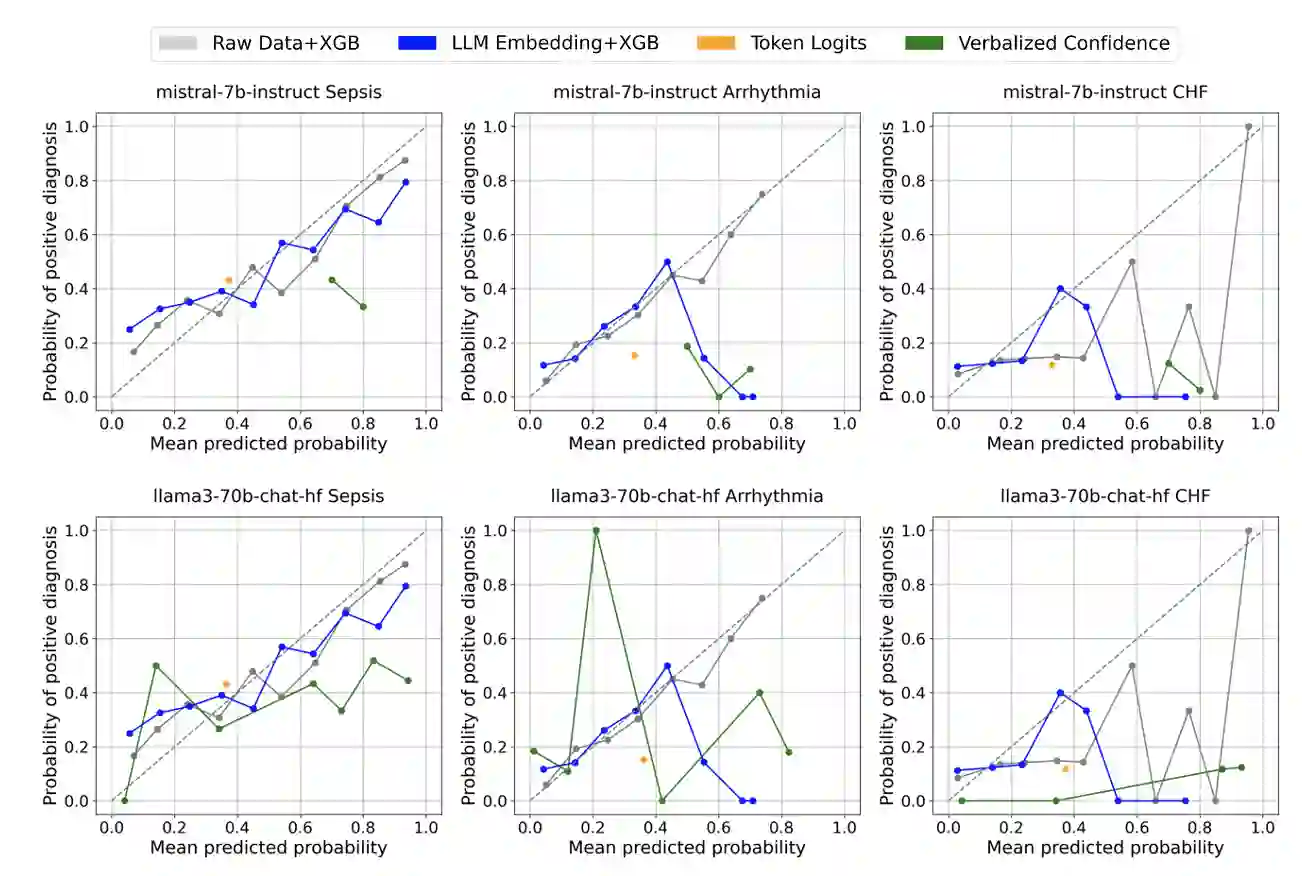
Large language models (LLMs) are being explored for diagnostic decision support, yet their ability to estimate pre-test probabilities, vital for clinical decision-making, remains limited. This study evaluates two LLMs, Mistral-7B and Llama3-70B, using structured electronic health record data on three diagnosis tasks. We examined three current methods of extracting LLM probability estimations and revealed their limitations. We aim to highlight the need for improved techniques in LLM confidence estimation.
翻译:大语言模型(LLMs)正被探索用于诊断决策支持,但其估算验前概率的能力——这对临床决策至关重要——仍然有限。本研究使用结构化电子健康记录数据,在三个诊断任务上评估了Mistral-7B和Llama3-70B两种大语言模型。我们检验了当前三种提取大语言模型概率估计的方法,并揭示了其局限性。我们旨在强调改进大语言模型置信度估计技术的必要性。
相关内容

专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月19日
Arxiv
66+阅读 · 2023年5月31日



最新内容
相关VIP内容
专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
相关资讯