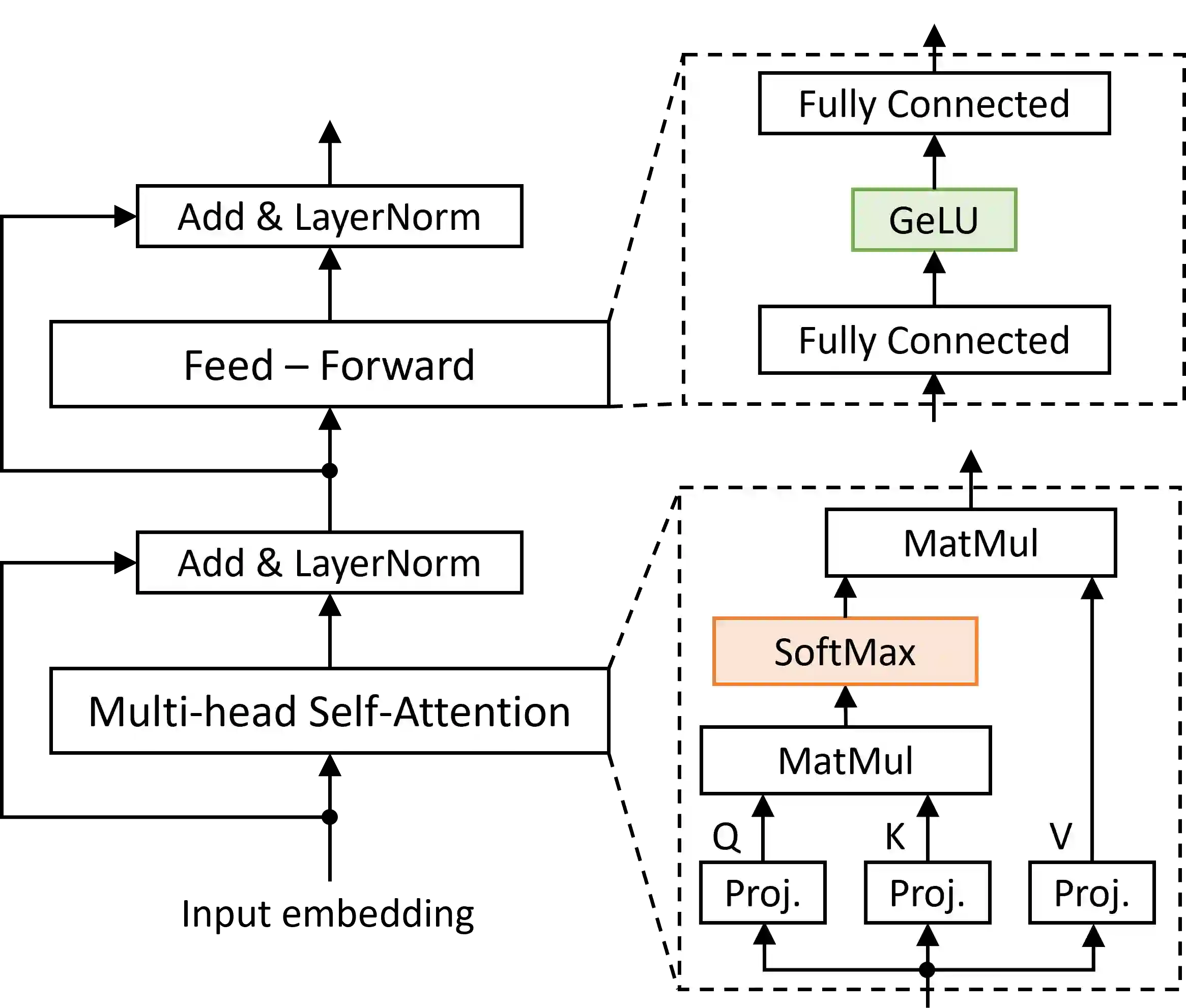
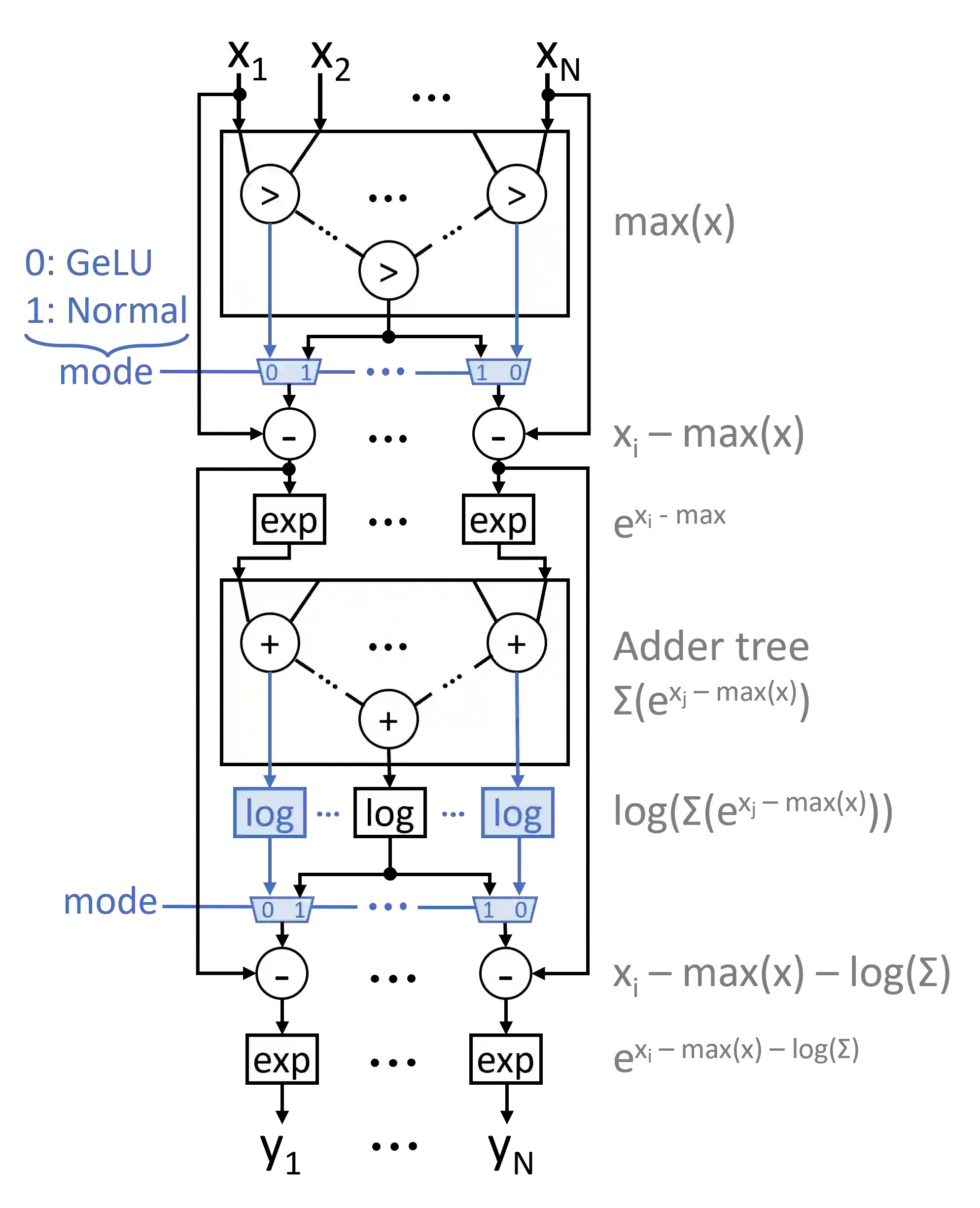
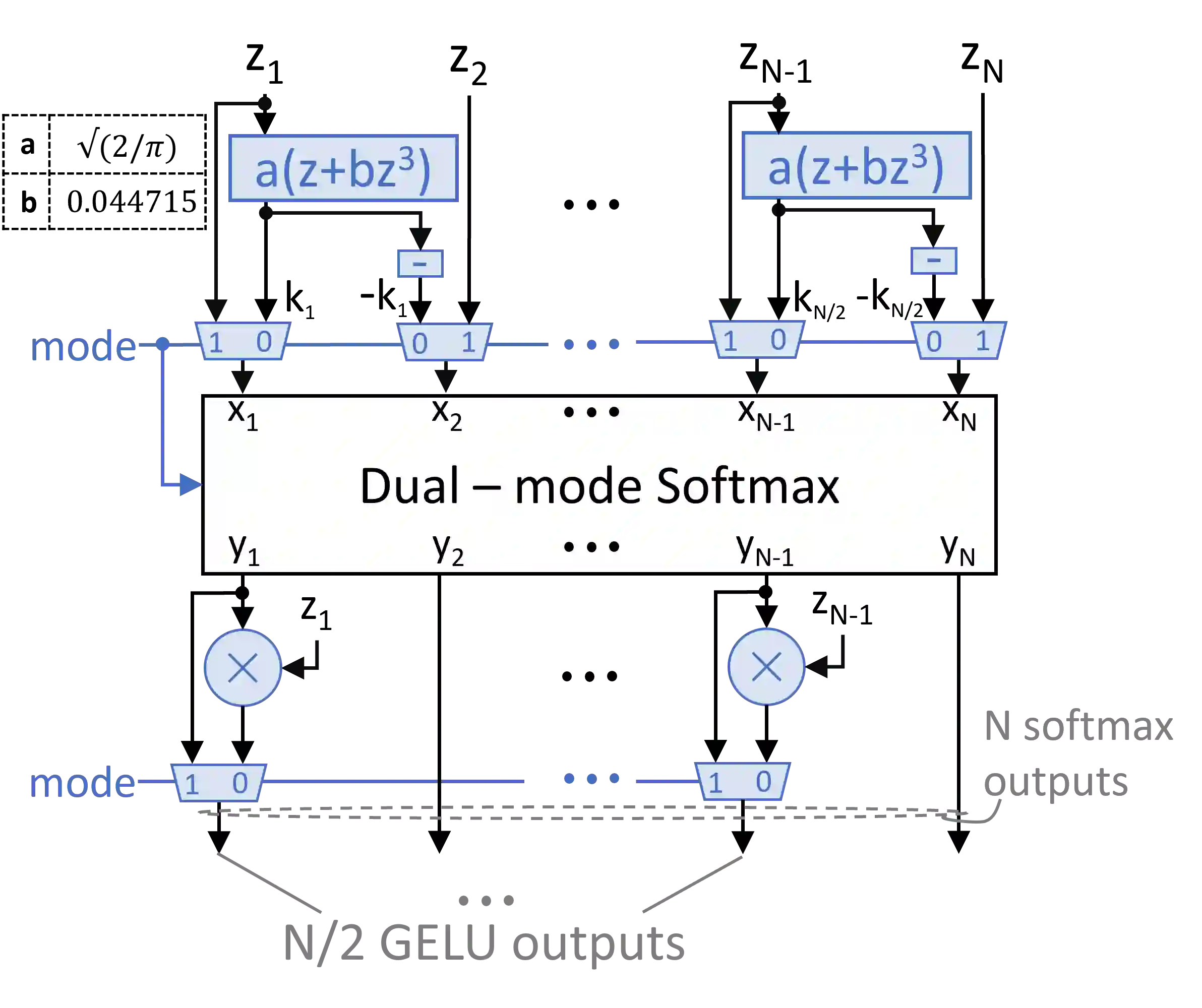
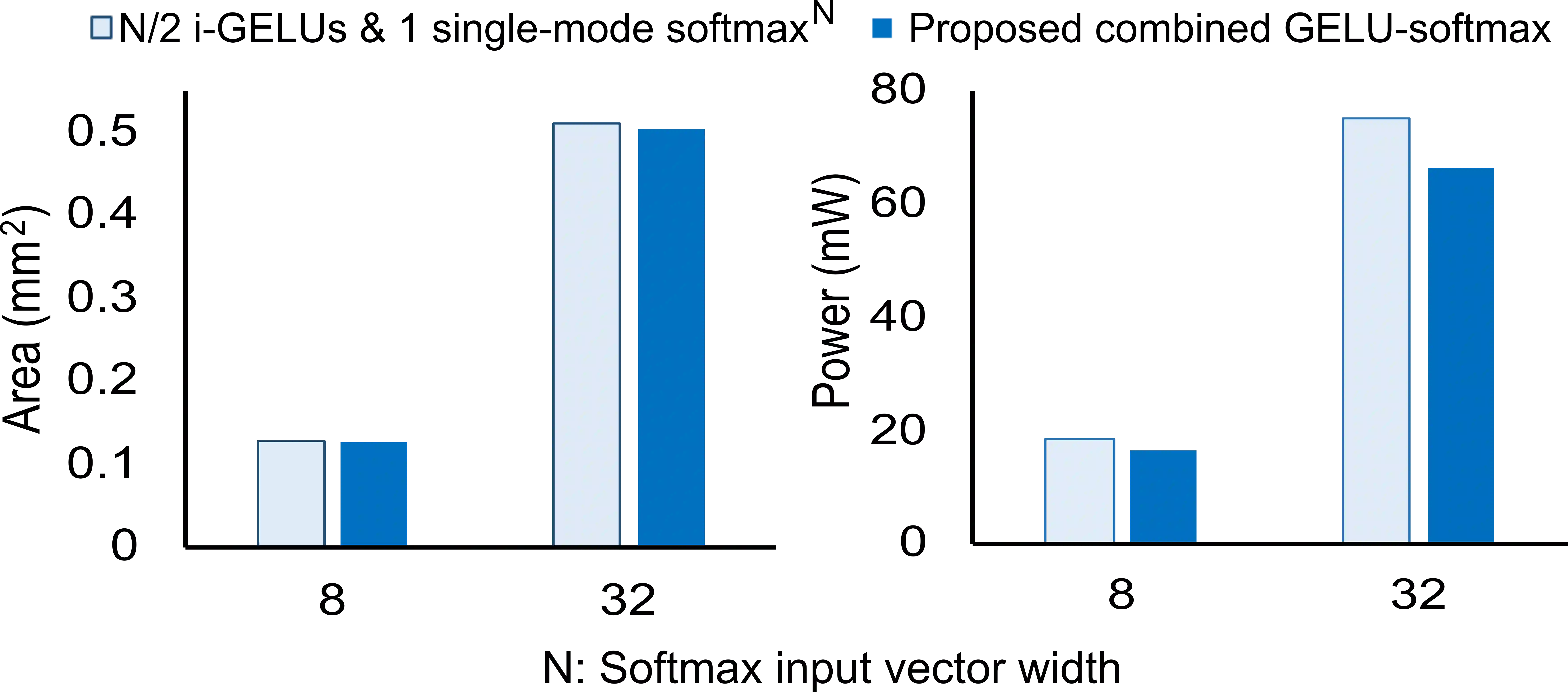Transformers have improved drastically the performance of natural language processing (NLP) and computer vision applications. The computation of transformers involves matrix multiplications and non-linear activation functions such as softmax and GELU (Gaussion Error Linear Unit) that are accelerated directly in hardware. Currently, function evaluation is done separately for each function and rarely allows for hardware reuse. To mitigate this problem, in this work, we map the computation of GELU to a softmax operator. In this way, the efficient hardware units designed already for softmax can be reused for computing GELU as well. Computation of GELU can enjoy the inherent vectorized nature of softmax and produce in parallel multiple GELU outcomes. Experimental results show that computing GELU via a pre-existing and incrementally modified softmax hardware unit (a) does not reduce the accuracy of representative NLP applications and (b) allows the reduction of the overall hardware area and power by 6.1% and 11.9%, respectively, on average.
翻译:Transformer极大提升了自然语言处理(NLP)与计算机视觉应用的性能。其计算涉及矩阵乘法及SoftMAX和GELU(高斯误差线性单元)等非线性激活函数,这些函数直接在硬件中加速实现。当前,各函数的计算独立进行,难以实现硬件复用。为解决此问题,本研究将GELU计算映射至SoftMAX算子,从而复用已为SoftMAX设计的高效硬件单元计算GELU。GELU计算可继承SoftMAX固有的向量化特性,并行生成多个GELU结果。实验表明,通过预存且渐进式修改的SoftMAX硬件单元计算GELU:(a)不会降低代表性NLP应用的精度;(b)可使整体硬件面积与功耗平均分别降低6.1%和11.9%。