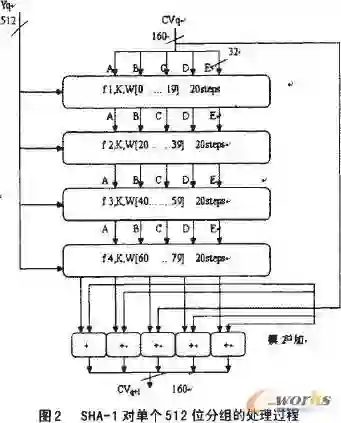
Generative pre-trained transformers (GPT's) are a type of large language machine learning model that are unusually adept at producing novel, and coherent, natural language. In this study the ability of GPT models to generate novel and correct versions, and notably very insecure versions, of implementations of the cryptographic hash function SHA-1 is examined. The GPT models Llama-2-70b-chat-h, Mistral-7B-Instruct-v0.1, and zephyr-7b-alpha are used. The GPT models are prompted to re-write each function using a modified version of the localGPT framework and langchain to provide word embedding context of the full source code and header files to the model, resulting in over 130,000 function re-write GPT output text blocks, approximately 40,000 of which were able to be parsed as C code and subsequently compiled. The generated code is analyzed for being compilable, correctness of the algorithm, memory leaks, compiler optimization stability, and character distance to the reference implementation. Remarkably, several generated function variants have a high implementation security risk of being correct for some test vectors, but incorrect for other test vectors. Additionally, many function implementations were not correct to the reference algorithm of SHA-1, but produced hashes that have some of the basic characteristics of hash functions. Many of the function re-writes contained serious flaws such as memory leaks, integer overflows, out of bounds accesses, use of uninitialised values, and compiler optimization instability. Compiler optimization settings and SHA-256 hash checksums of the compiled binaries are used to cluster implementations that are equivalent but may not have identical syntax - using this clustering over 100,000 novel and correct versions of the SHA-1 codebase were generated where each component C function of the reference implementation is different from the original code.
翻译:生成式预训练Transformer(GPT)是一种大型语言机器学习模型,其在生成新颖且连贯的自然语言方面表现出非凡的能力。本研究考察了GPT模型为加密哈希函数SHA-1生成新颖且正确版本(尤其是极不安全的版本)的能力。研究中使用了Llama-2-70b-chat-h、Mistral-7B-Instruct-v0.1和zephyr-7b-alpha等GPT模型。通过改进版localGPT框架和langchain,将完整源代码和头文件的词嵌入上下文提供给GPT模型,提示其重写每个函数,最终获得超过13万个函数重写GPT输出文本块,其中约4万个可解析为C代码并成功编译。对生成的代码从可编译性、算法正确性、内存泄漏、编译器优化稳定性以及与参考实现的字符距离等方面进行了分析。值得注意的是,多个生成的函数变体存在高风险安全隐患:对某些测试向量正确,但对其他测试向量错误。此外,许多函数实现虽然与SHA-1参考算法不一致,但生成的哈希值具有哈希函数的部分基本特征。大量函数重写版本存在严重缺陷,如内存泄漏、整数溢出、越界访问、未初始化值使用以及编译器优化不稳定性。通过编译器优化设置和编译后二进制文件的SHA-256哈希校验和,对语法不同但功能等价的实现进行聚类分析。利用该聚类方法,生成了超过10万个新颖且正确的SHA-1代码库版本,其中参考实现的每个C函数组件均与原始代码存在差异。