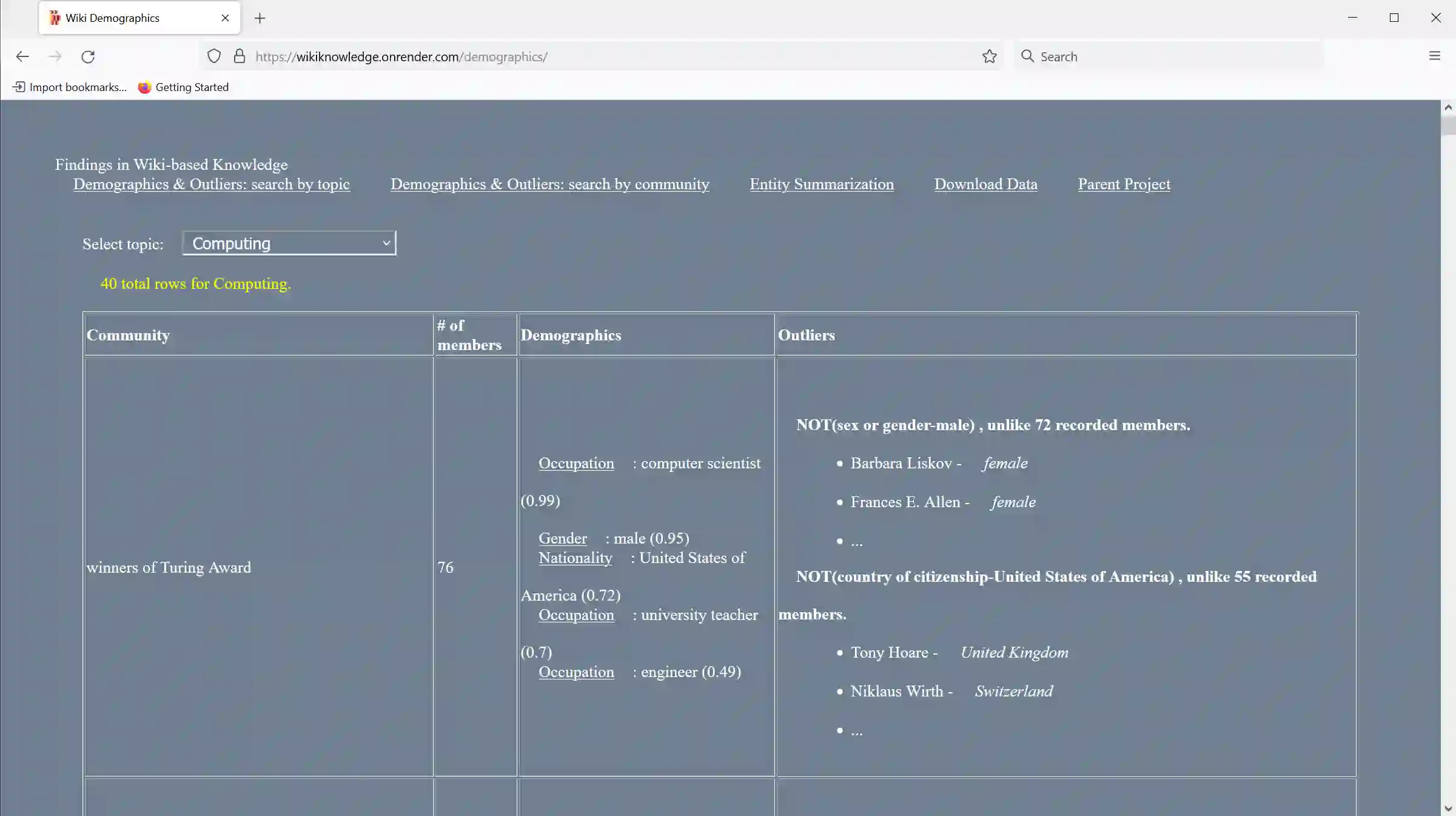
In this paper, we release data about demographic information and outliers of communities of interest. Identified from Wiki-based sources, mainly Wikidata, the data covers 7.5k communities, such as members of the White House Coronavirus Task Force, and 345k subjects, e.g., Deborah Birx. We describe the statistical inference methodology adopted to mine such data. We release subject-centric and group-centric datasets in JSON format, as well as a browsing interface. Finally, we forsee three areas this research can have an impact on: in social sciences research, it provides a resource for demographic analyses; in web-scale collaborative encyclopedias, it serves as an edit recommender to fill knowledge gaps; and in web search, it offers lists of salient statements about queried subjects for higher user engagement.
翻译:本文发布了兴趣社区的人口统计信息及离群点数据集。该数据集源自维基百科系统(主要为维基数据),涵盖7,500个社区(如白宫冠状病毒工作组成员)及345,000个主体(如黛博拉·伯克斯)。我们描述了用于挖掘此类数据的统计推断方法,并以JSON格式发布了面向主体和面向群体的数据集及浏览接口。最后,我们预见本研究可在三个领域产生应用价值:在社会学研究中,为人口统计分析提供资源;在网络百科协作系统中,可作为填补知识空白的编辑推荐工具;在网络搜索中,可为查询主体提供关键事实列表以提升用户参与度。