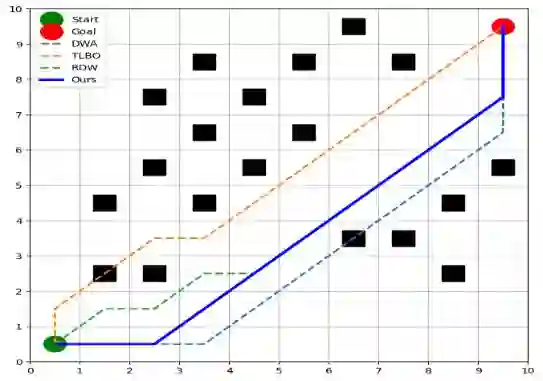
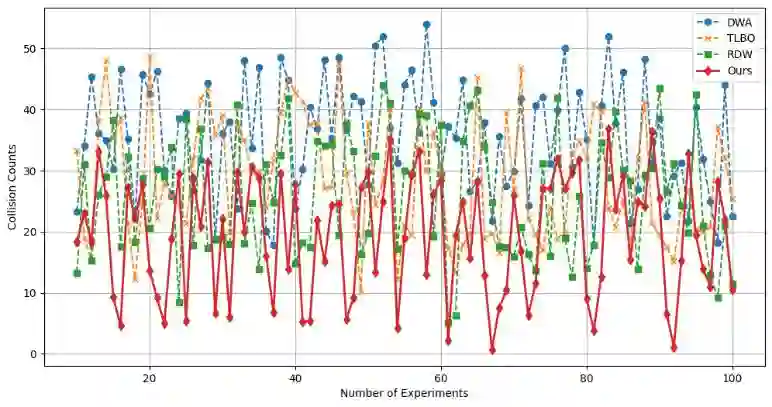
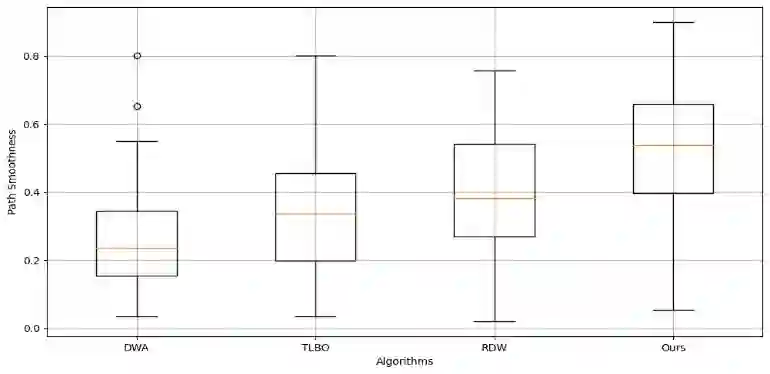
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
翻译:强化学习通过与环境的持续交互,依据实时反馈的奖励信号不断优化决策过程,展现出强大的自适应与自学习能力。近年来,它已成为实现机器人自主导航的关键方法之一。本文提出了一种基于强化学习的自主机器人导航方法。我们采用深度Q网络(DQN)与近端策略优化(PPO)模型,通过机器人与环境的持续交互以及实时反馈的奖励信号,优化路径规划与决策过程。深度Q网络将Q值函数与深度神经网络相结合,能够处理高维状态空间,从而实现在复杂环境中的路径规划。近端策略优化是一种基于策略梯度的方法,通过优化策略函数使机器人能更高效地探索和利用环境信息。这些方法不仅提升了机器人在未知环境中的导航能力,也增强了其自适应与自学习能力。通过多次训练与仿真实验,我们验证了这些模型在多种复杂场景下的有效性与鲁棒性。