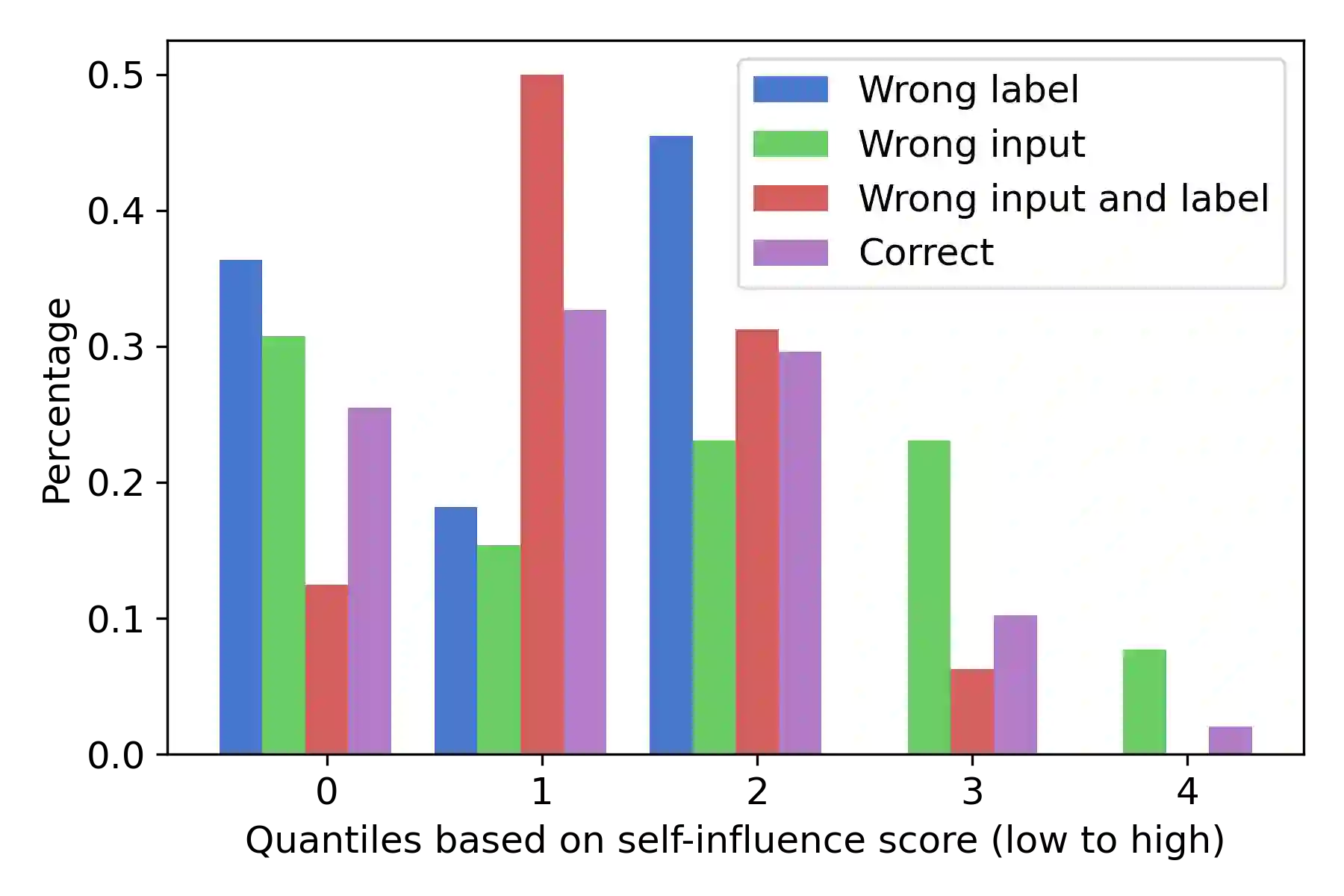
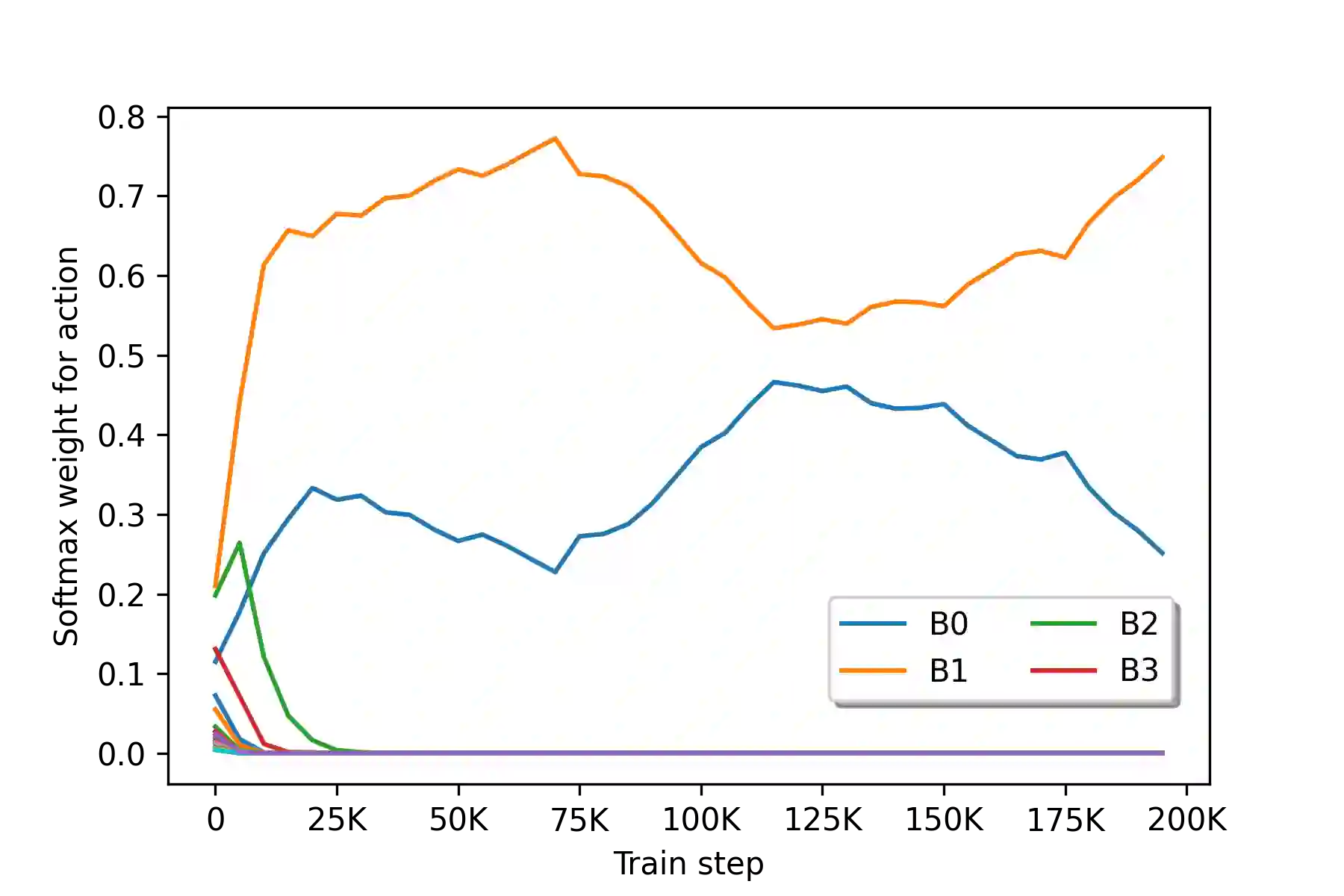
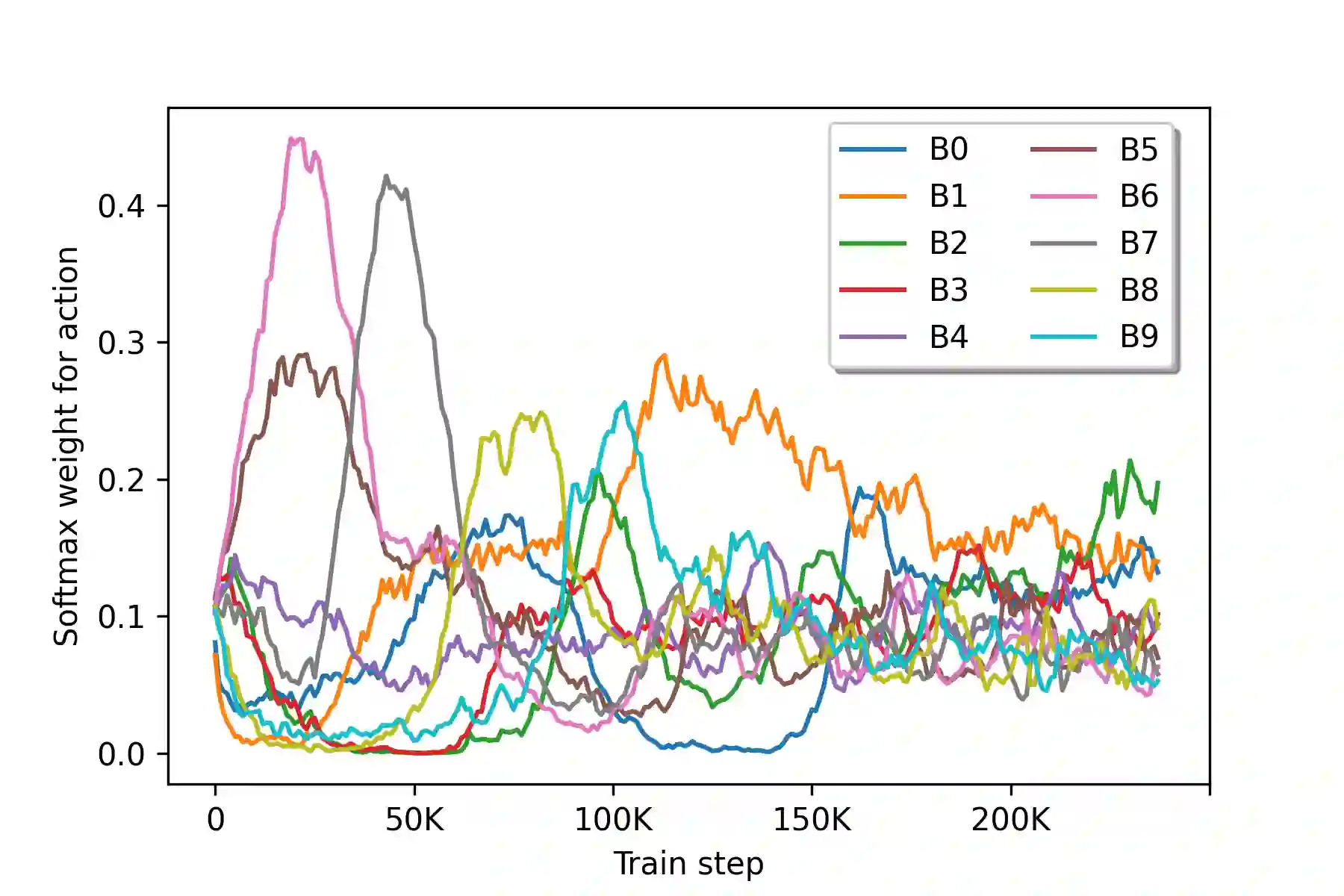
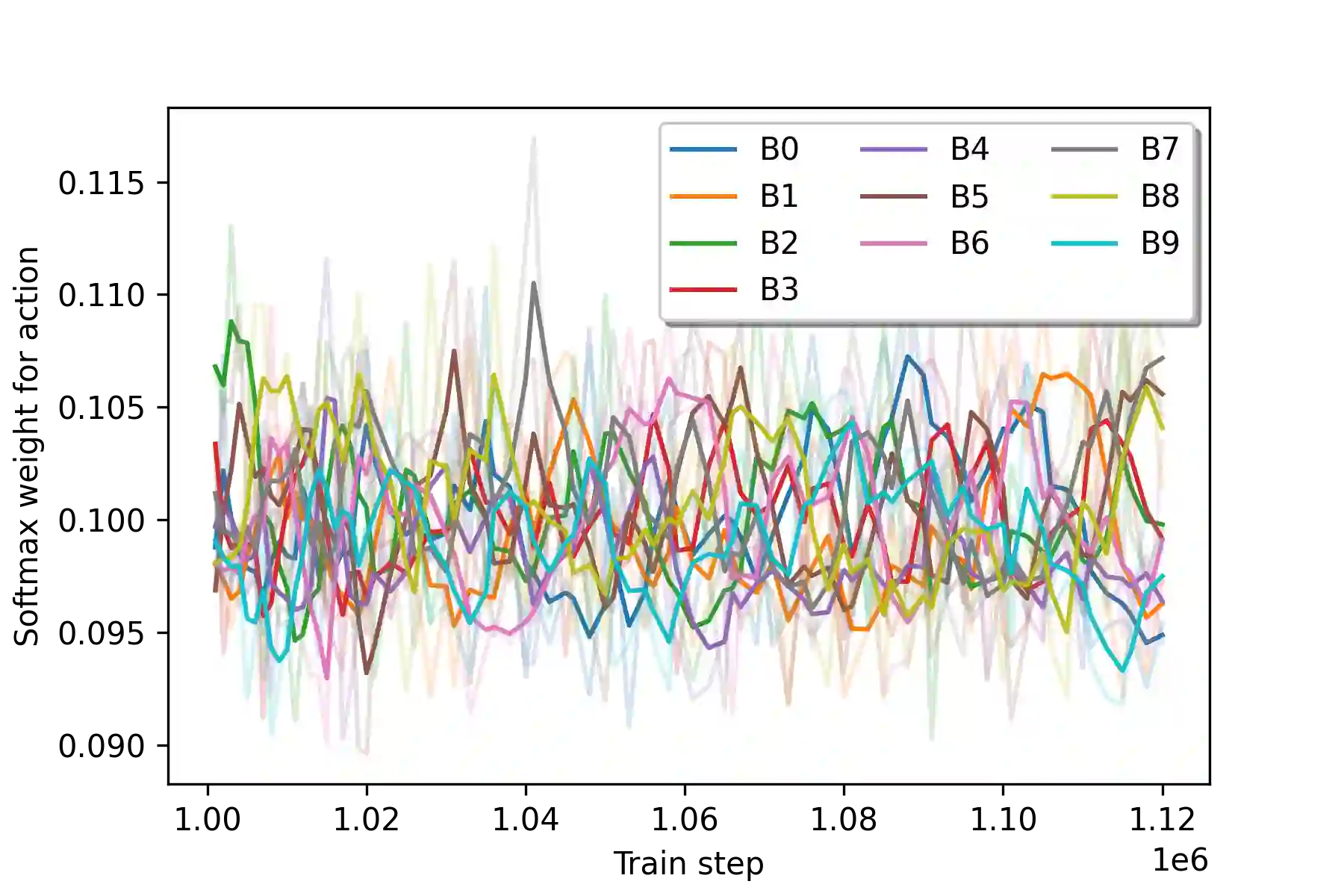
Increasingly larger datasets have become a standard ingredient to advancing the state-of-the-art in NLP. However, data quality might have already become the bottleneck to unlock further gains. Given the diversity and the sizes of modern datasets, standard data filtering is not straight-forward to apply, because of the multifacetedness of the harmful data and elusiveness of filtering rules that would generalize across multiple tasks. We study the fitness of task-agnostic self-influence scores of training examples for data cleaning, analyze their efficacy in capturing naturally occurring outliers, and investigate to what extent self-influence based data cleaning can improve downstream performance in machine translation, question answering and text classification, building up on recent approaches to self-influence calculation and automated curriculum learning.
翻译:日益庞大的数据集已成为推动自然语言处理领域前沿进展的标准要素,但数据质量可能已成为制约性能进一步提升的瓶颈。鉴于现代数据集的多样性与庞大规模,标准数据过滤方法因有害数据的多面性及难以提炼跨任务通用过滤规则而难以直接应用。本研究基于近期自影响计算与自动课程学习的方法,探索训练样本的任务无关自影响分数在数据清洗中的适用性,分析其捕捉自然异常值的能力,并系统评估基于自影响的数据清洗对机器翻译、问答与文本分类下游任务的改进效果。