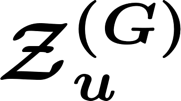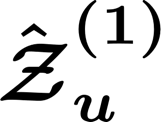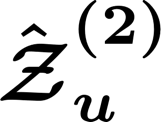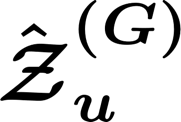News recommendation plays a critical role in online news platforms by helping users discover relevant content. Cross-domain news recommendation further requires inferring user's underlying information needs from heterogeneous signals that often extend beyond direct news consumption. A key challenge lies in moving beyond surface-level behaviors to capture deeper, reusable user interests while maintaining scalability in large-scale production systems. In this paper, we present a reinforcement learning framework that trains large language models to generate high-quality lists of interest-driven news search queries from cross-domain user signals. We formulate query-list generation as a policy optimization problem and employ GRPO with multiple reward signals. We systematically study two compute dimensions: inference-time sampling and model capacity, and empirically observe consistent improvements with increased compute that exhibit scaling-like behavior. Finally, we perform on-policy distillation to transfer the learned policy from a large, compute-intensive teacher to a compact student model suitable for scalable deployment. Extensive offline experiments, ablation studies and large-scale online A/B tests in a production news recommendation system demonstrate consistent gains in both interest modeling quality and downstream recommendation performance.
翻译:新闻推荐在在线新闻平台中扮演着关键角色,帮助用户发现相关内容。跨领域新闻推荐进一步要求从通常超出直接新闻消费的异构信号中推断用户的潜在信息需求。一个核心挑战在于超越表层行为,以捕捉更深层次、可复用的用户兴趣,同时在大规模生产系统中保持可扩展性。本文提出一种强化学习框架,训练大型语言模型从跨领域用户信号中生成高质量的兴趣驱动新闻搜索查询列表。我们将查询列表生成构建为一个策略优化问题,并采用具有多重奖励信号的GRPO。我们系统地研究了两个计算维度:推理时采样与模型容量,并通过实证观察到随着计算量增加带来的持续改进呈现出类似缩放的行为。最后,我们执行同策略蒸馏,将学习到的策略从一个计算密集型的大型教师模型迁移到一个适用于可扩展部署的紧凑学生模型。在生产新闻推荐系统中进行的广泛离线实验、消融研究和大规模在线A/B测试,均证明了该方法在兴趣建模质量和下游推荐性能上的一致提升。