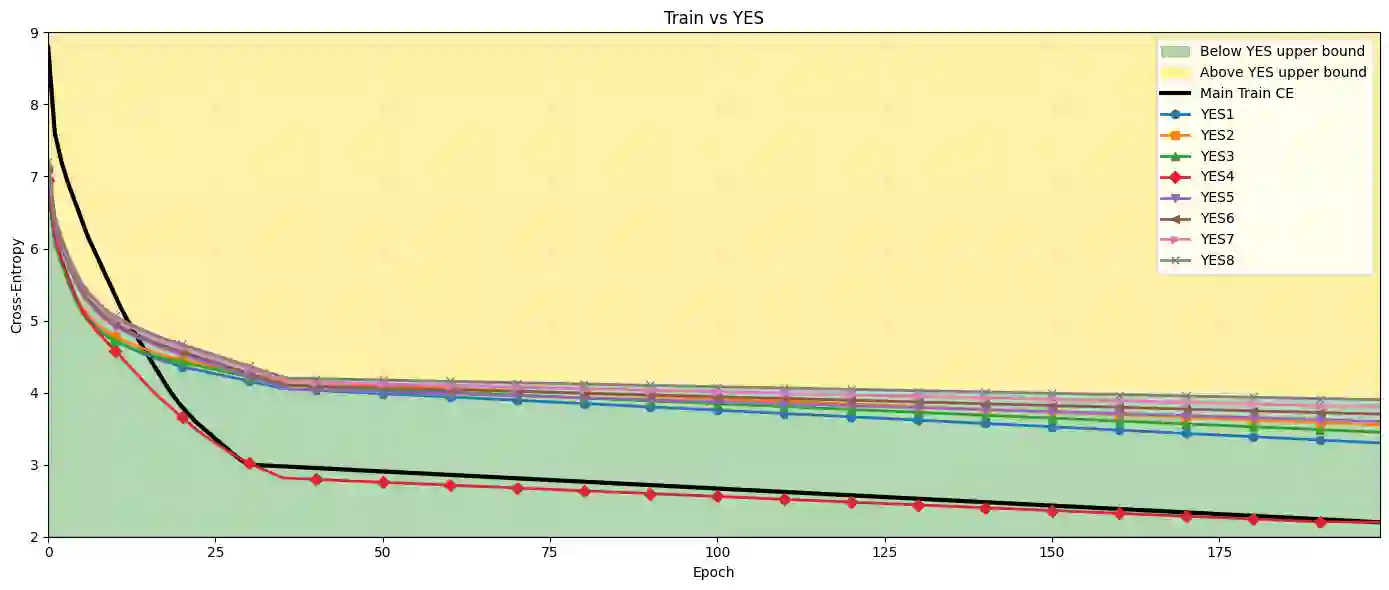
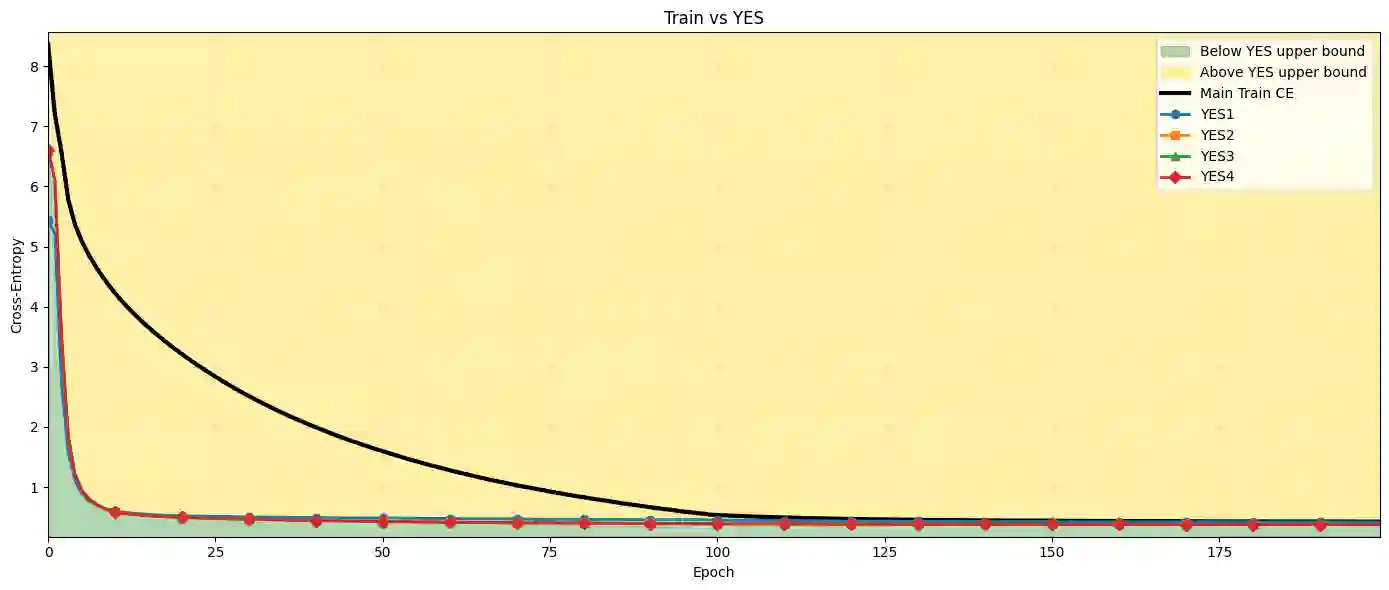
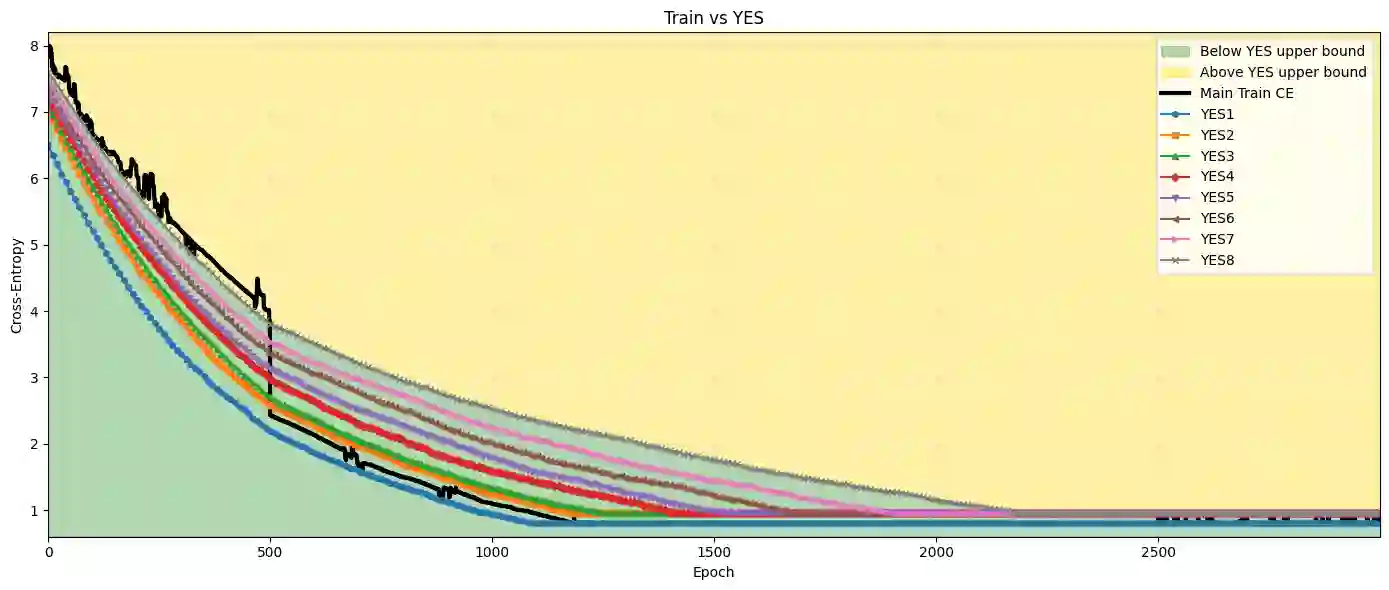
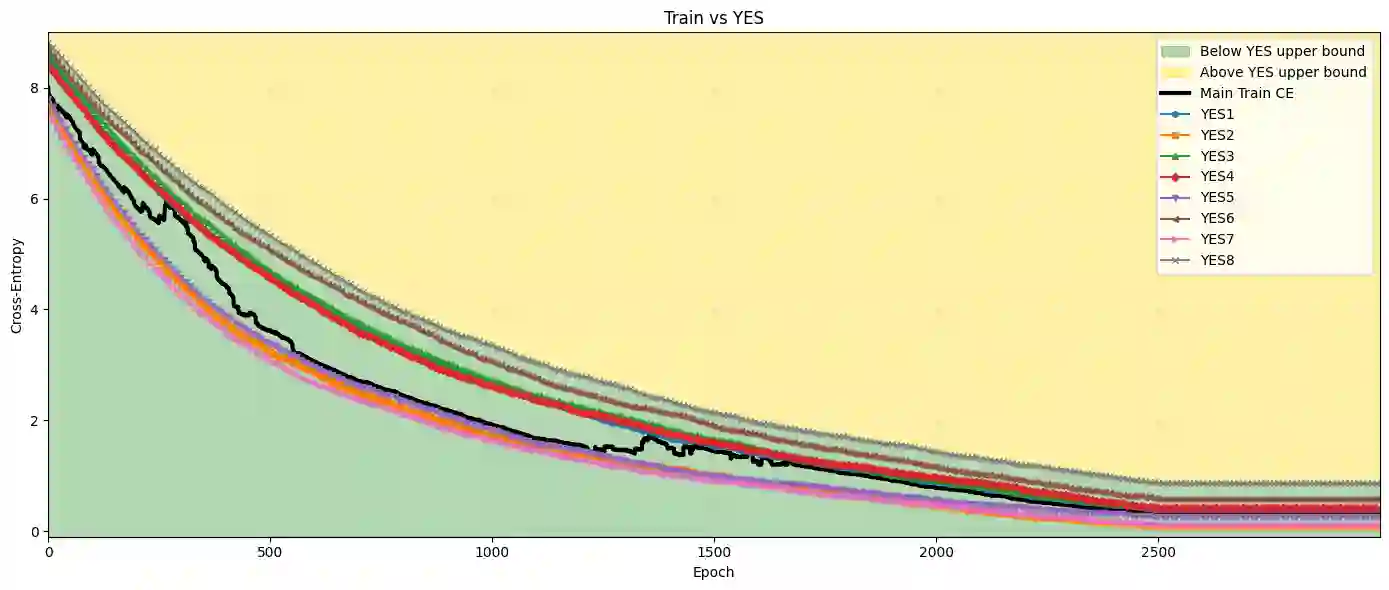
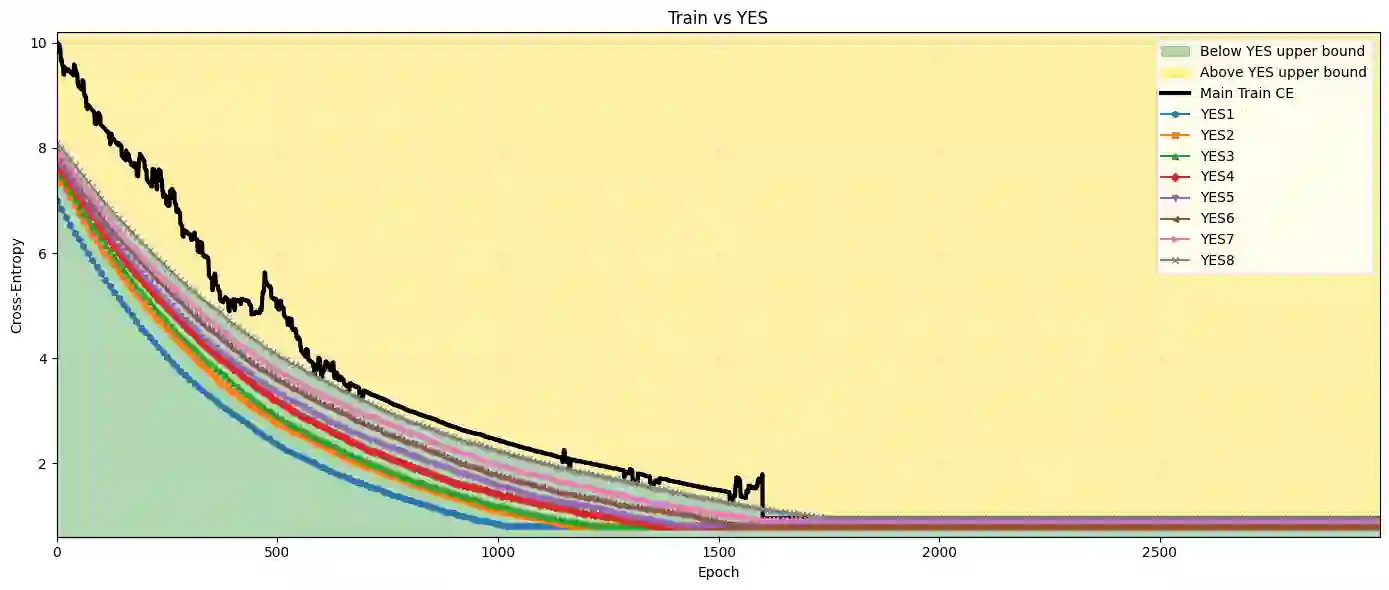
Understanding whether deep neural networks are effectively optimized remains challenging, as training occurs in highly nonconvex landscapes and standard metrics provide limited visibility into layer-wise learning quality. This challenge is particularly acute for transformer-based language models, where training is expensive, models are often reused in frozen form, and poorly optimized layers can silently degrade performance. We propose a layer-wise peeling framework for monitoring training dynamics, in which each transformer layer is locally optimized against intermediate representations of the trained model. By constructing lightweight, layer-specific reference solutions and projecting layers onto multiple intermediate outputs via different permutations, we obtain achievable baselines that enable fine-grained diagnosis of under-optimized layers. Experiments on decoder-only transformer models show that these layer-wise reference bounds can match or even surpass the trained model at various stages of training, exposing inefficiencies that remain hidden in aggregate loss curves. We further demonstrate that this analysis remains effective under binarization and quantized settings, where training dynamics are particularly fragile. Across all numerical results, the proposed bounds consistently separate apparent convergence from effective optimality, highlighting optimization opportunities that are invisible when relying on training loss alone.
翻译:理解深度神经网络是否被有效优化仍具挑战性,因为训练发生在高度非凸的景观中,且标准指标对逐层学习质量的可见性有限。这一问题在基于Transformer的语言模型中尤为突出,因为训练成本高昂,模型常以冻结形式复用,优化不良的层会悄然降低性能。我们提出了一种逐层拆解框架以监控训练动态,其中每个Transformer层针对训练模型的中间表示进行局部优化。通过构建轻量级、特定层的参考解,并利用不同排列将层投影到多个中间输出上,我们获得了可实现的基线,从而能够对未充分优化的层进行细粒度诊断。在解码器仅Transformer模型上的实验表明,这些逐层参考界限在训练的不同阶段可以匹配甚至超越训练模型,揭示了隐藏在聚合损失曲线中的低效问题。我们进一步证明,在二值化和量化设置下(其中训练动态尤为脆弱),这一分析仍然有效。在所有数值结果中,所提出的界限始终将表面收敛与有效最优性区分开来,凸显了仅依赖训练损失时无法察觉的优化机会。