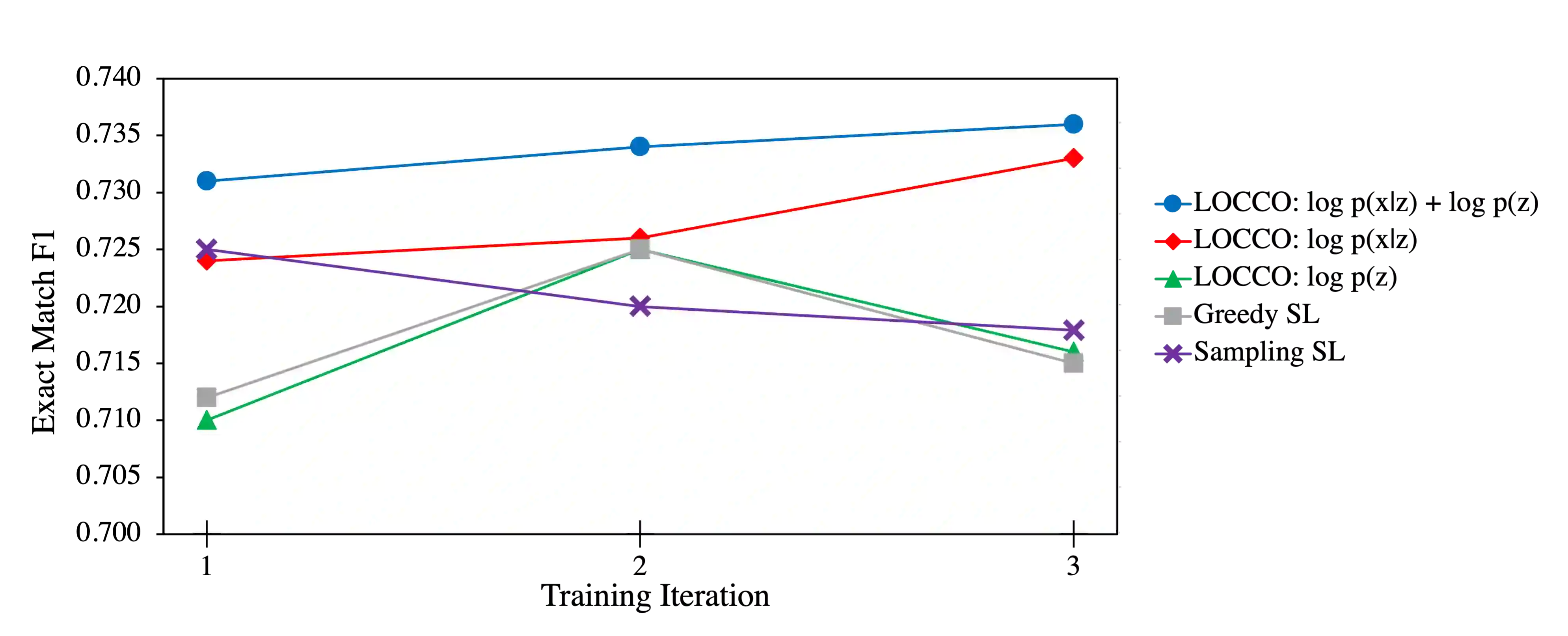
We introduce Logical Offline Cycle Consistency Optimization (LOCCO), a scalable, semi-supervised method for training a neural semantic parser. Conceptually, LOCCO can be viewed as a form of self-learning where the semantic parser being trained is used to generate annotations for unlabeled text that are then used as new supervision. To increase the quality of annotations, our method utilizes a count-based prior over valid formal meaning representations and a cycle-consistency score produced by a neural text generation model as additional signals. Both the prior and semantic parser are updated in an alternate fashion from full passes over the training data, which can be seen as approximating the marginalization of latent structures through stochastic variational inference. The use of a count-based prior, frozen text generation model, and offline annotation process yields an approach with negligible complexity and latency increases as compared to conventional self-learning. As an added bonus, the annotations produced by LOCCO can be trivially repurposed to train a neural text generation model. We demonstrate the utility of LOCCO on the well-known WebNLG benchmark where we obtain an improvement of 2 points against a self-learning parser under equivalent conditions, an improvement of 1.3 points against the previous state-of-the-art parser, and competitive text generation performance in terms of BLEU score.
翻译:我们提出逻辑离线循环一致性优化(LOCCO),这是一种可扩展的半监督方法,用于训练神经语义解析器。从概念上讲,LOCCO可视为一种自学习形式:训练中的语义解析器被用于为未标注文本生成注释,这些注释进而被用作新的监督信号。为提升注释质量,本方法利用基于计数的有效形式意义先验知识以及神经文本生成模型产生的循环一致性得分作为额外信号。先验知识与语义解析器通过遍历训练数据的完整轮次以交替方式更新,这可视作通过随机变分推断对潜在结构进行边际化近似。采用基于计数的先验知识、冻结的文本生成模型以及离线注释流程,使得该方法与传统自学习相比,复杂度与延迟增量可忽略不计。作为额外优势,LOCCO产生的注释可轻易复用于训练神经文本生成模型。我们在著名的WebNLG基准上验证了LOCCO的有效性:在同等条件下,相较于自学习解析器取得2个百分点的提升;相较于先前最优解析器提升1.3个百分点;在BLEU评分方面获得具有竞争力的文本生成性能。