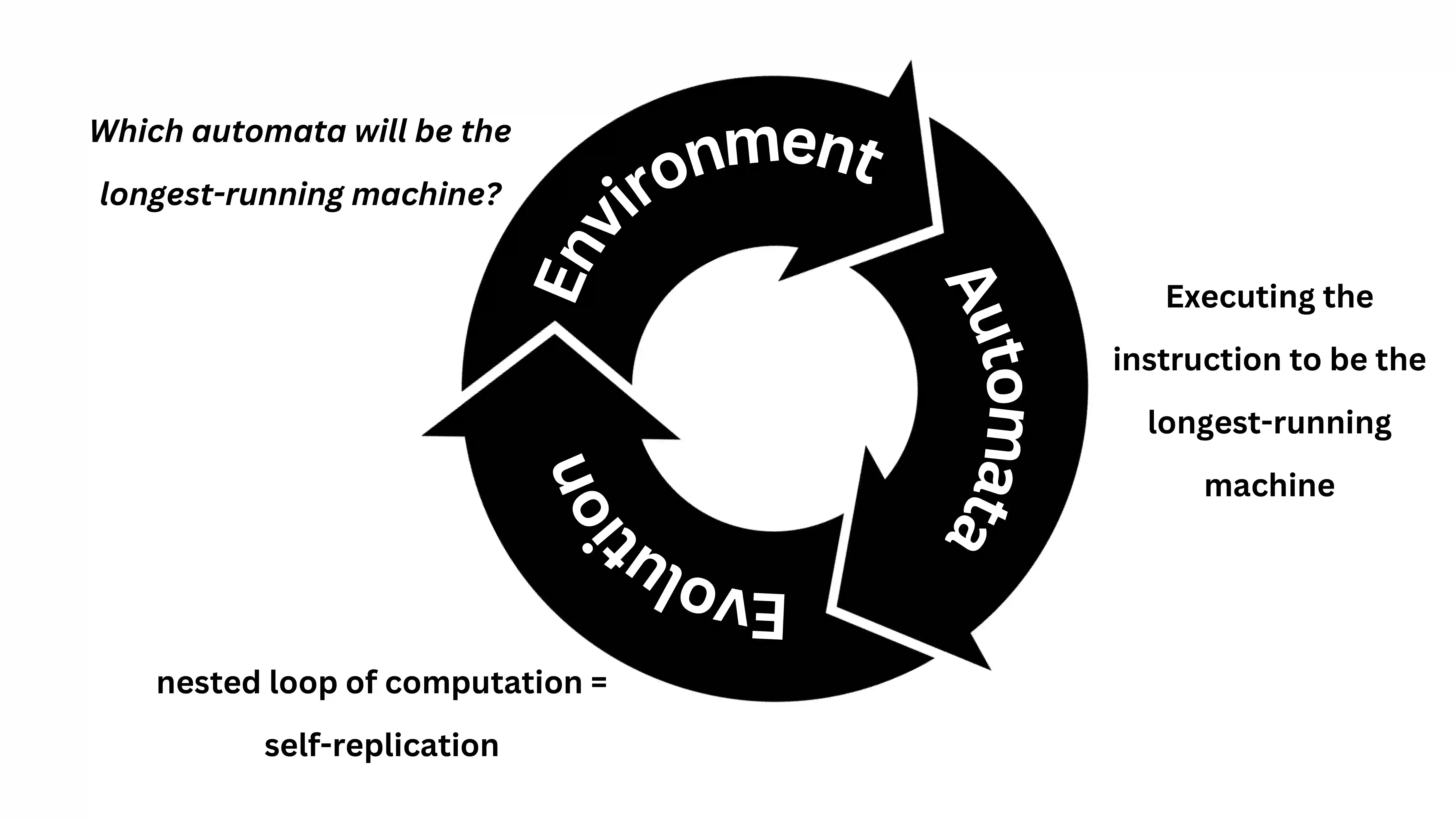
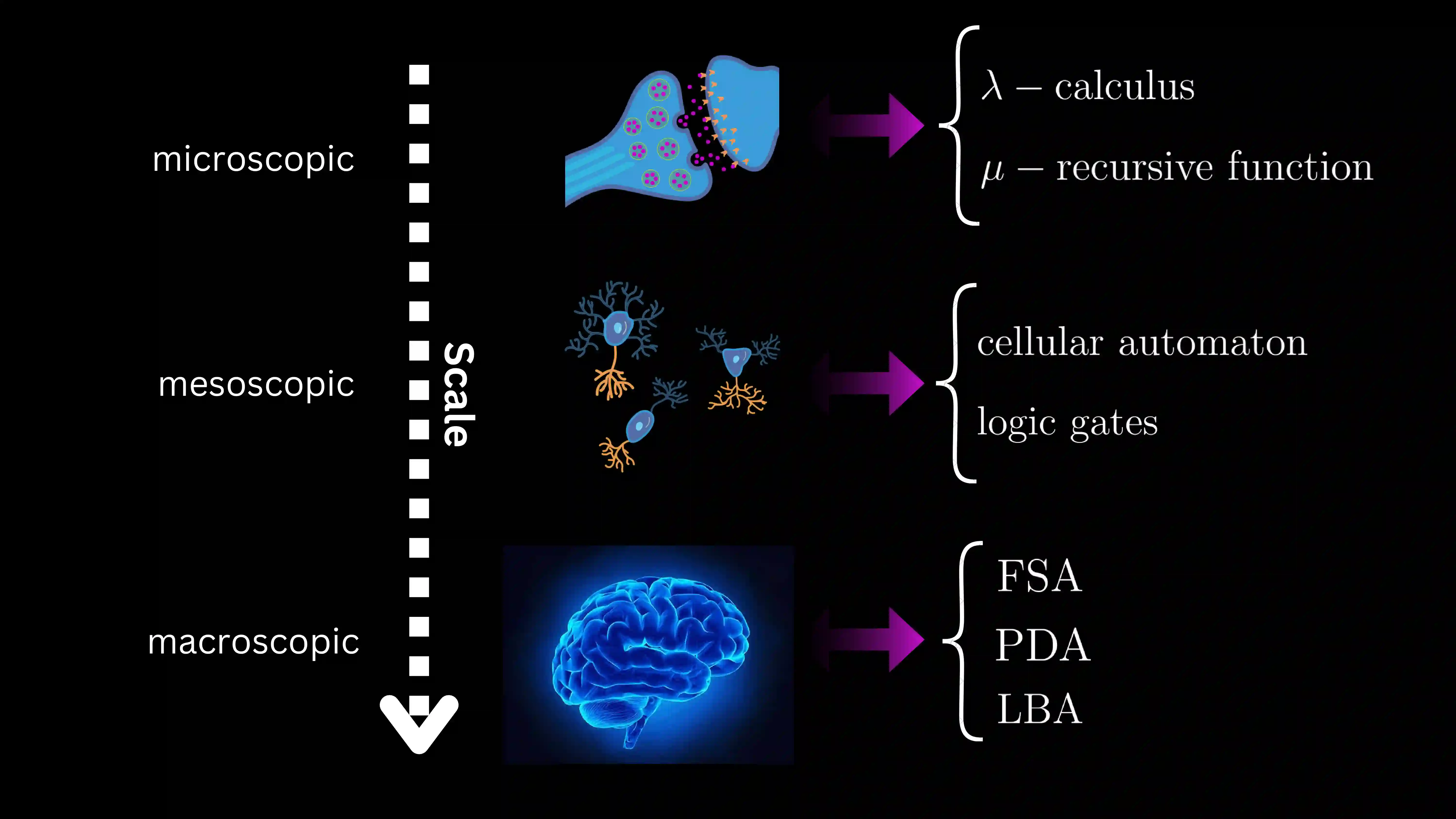
A major challenge when describing the origin of life is to explain how instructional information control systems emerge naturally and spontaneously from mere molecular dynamics. So far, no one has clarified how information control emerged ab initio and how primitive control mechanisms in life might have evolved, becoming increasingly refined. Based on recent experimental results showing that chemical computation does not require the presence of life-related chemistry, we elucidate the origin and early evolution of information handling by chemical automata, from information processing (computation) to information storage (memory) and information transmission (communication). In contrast to other theories that assume the existence of initial complex structures, our narrative starts from trivial self-replicators whose interaction leads to the arising of more powerful molecular machines. By describing precisely the primordial transitions in chemistry-based computation, our metaphor is capable of explaining the above-mentioned gaps and can be translated to other models of computation, which allow us to explore biological phenomena at multiple spatial and temporal scales. At the end of our manuscript, we propose some ways to extend our ideas, including experimental validation of our theory (both in vitro and in silico).
翻译:描述生命起源时面临的一个主要挑战是解释指令性信息控制系统如何从单纯的分子动力学中自然且自发地涌现。迄今为止,尚未有人阐明信息控制如何从最初开始出现,以及生命中的原始控制机制如何可能演化并逐渐变得精妙。基于近期显示化学计算无需依赖生命相关化学的实验结果,我们阐明了化学自动机信息处理的起源与早期演化过程——从信息处理(计算)到信息存储(记忆)再到信息传输(通信)。与其他假设存在初始复杂结构的理论不同,我们的论述始于简单的自我复制体,其相互作用催生了更强大的分子机器。通过精确描述基于化学的计算中的原始转变过程,我们的理论模型能够解释上述空白,并可推广至其他计算模型,从而允许我们在多时空尺度上探索生物现象。在本文结尾,我们提出了若干拓展本思想的途径,包括对本理论进行实验验证(体外与计算机模拟)。