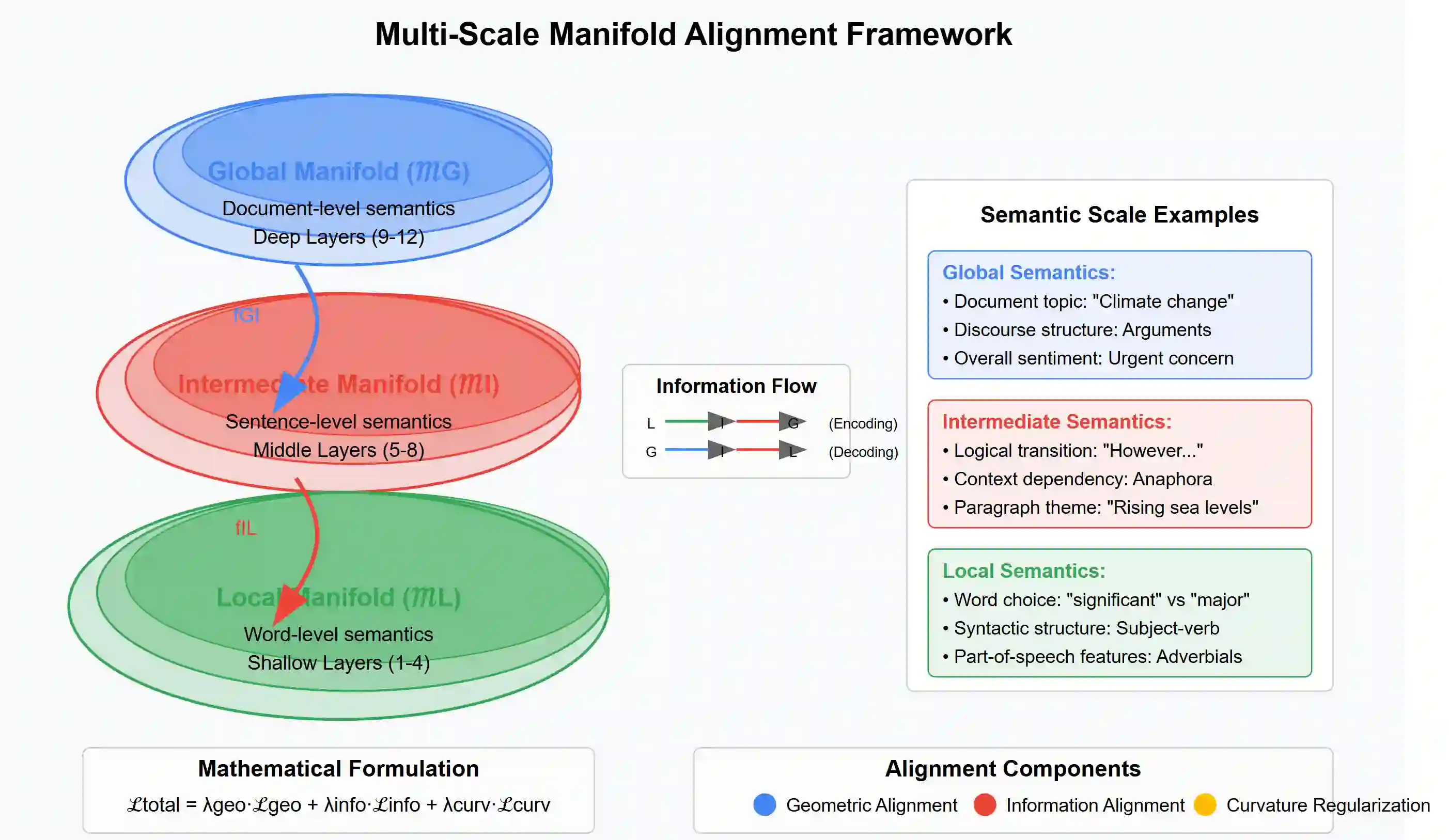
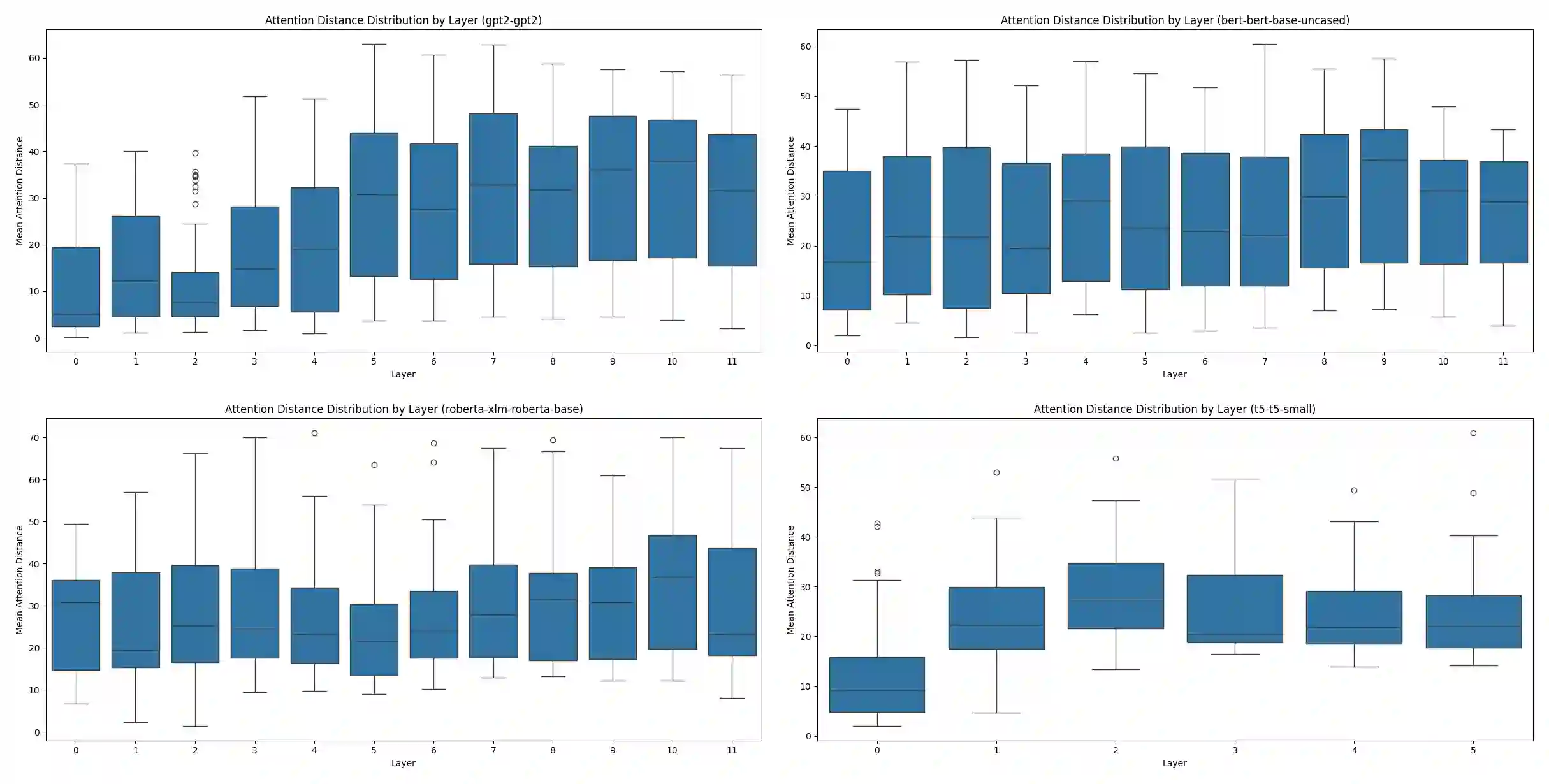
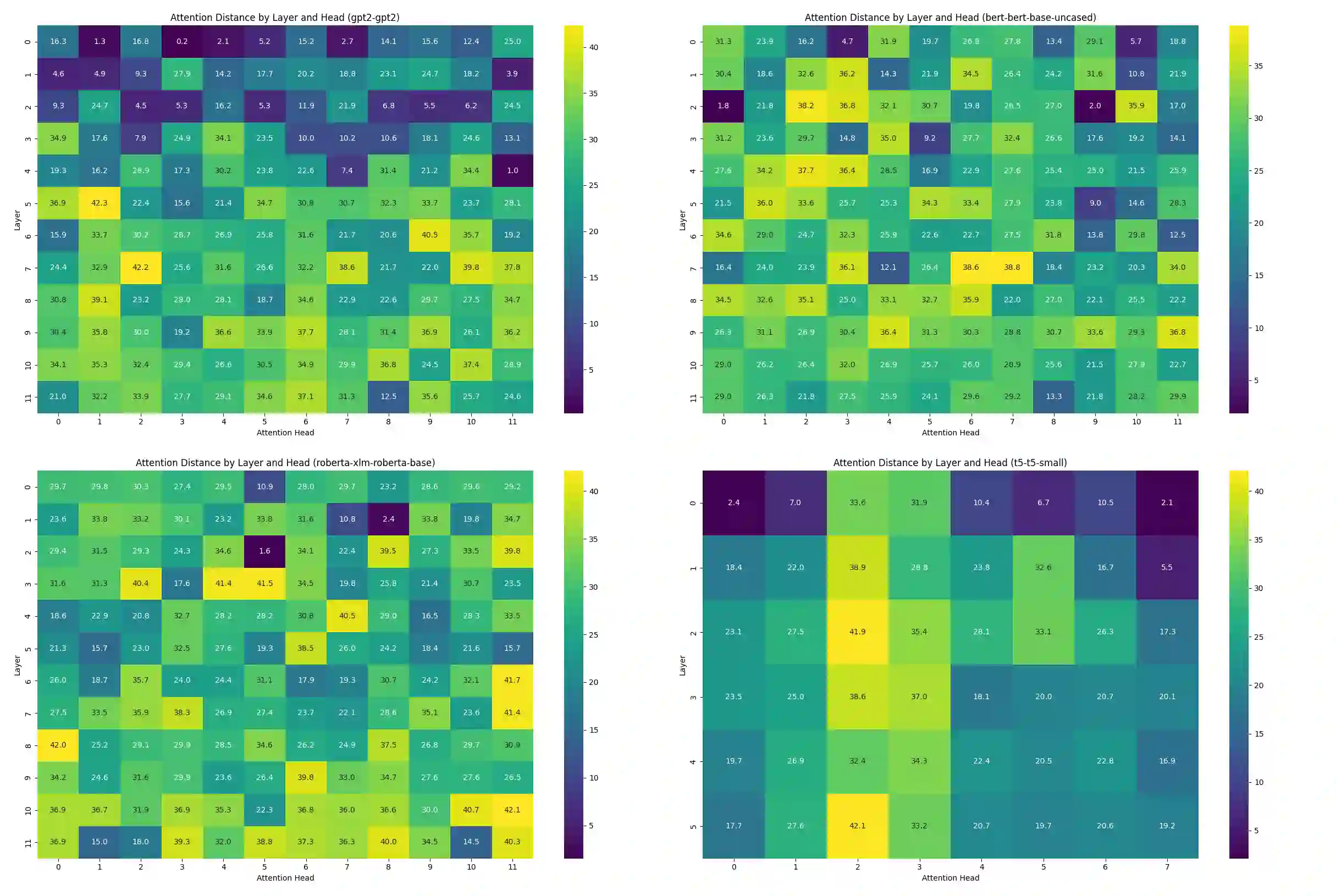
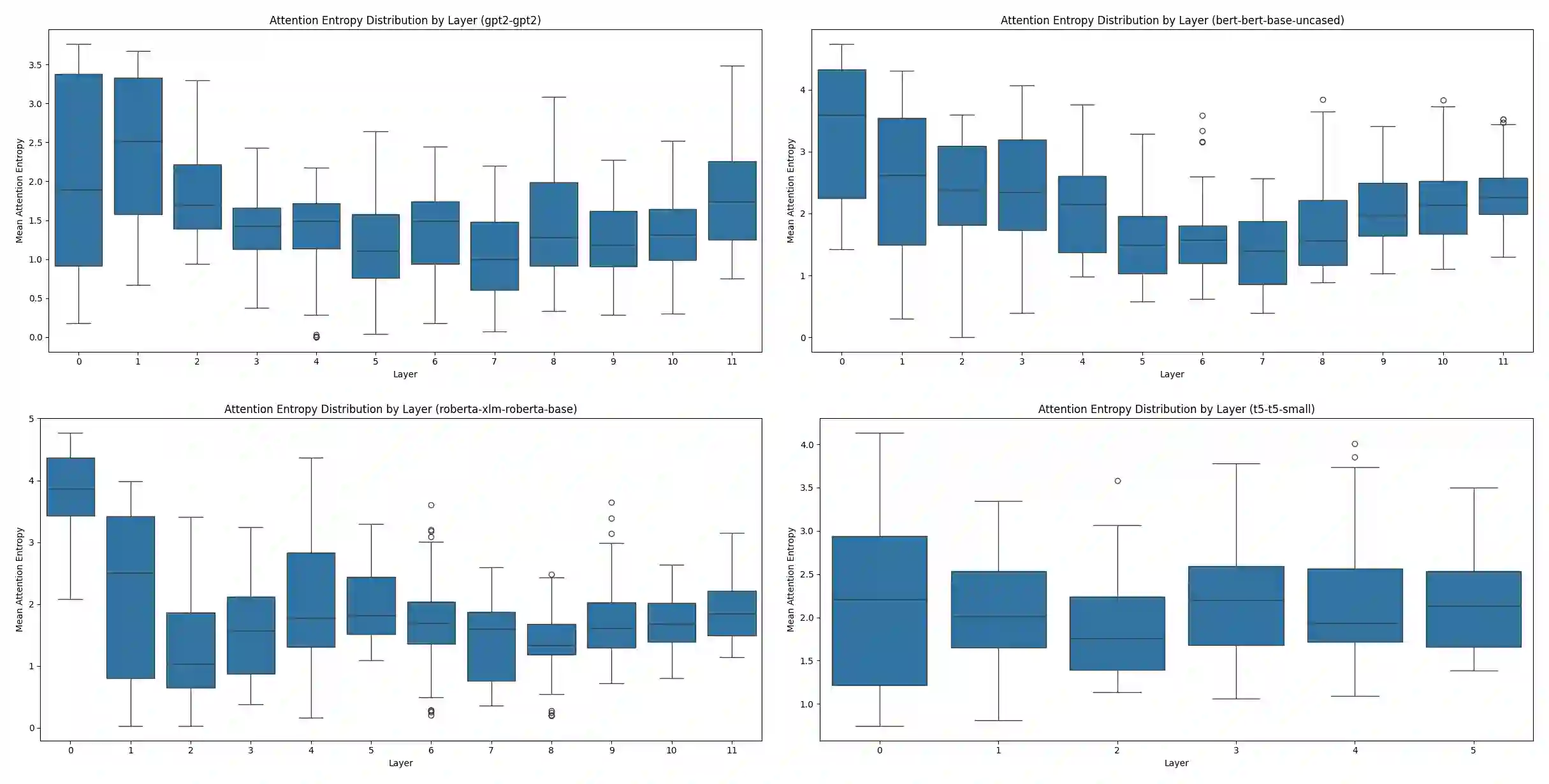
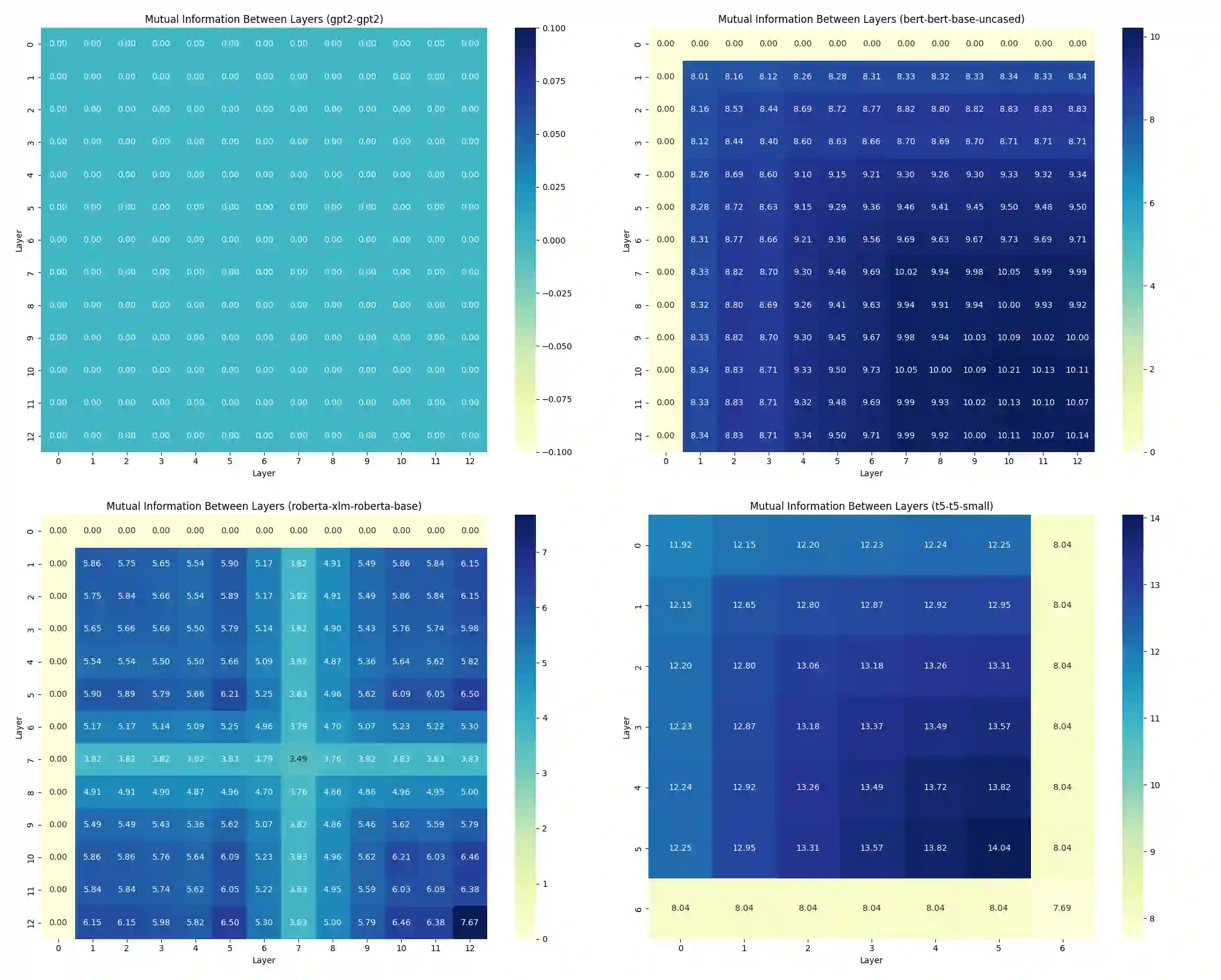
We present Multi-Scale Manifold Alignment(MSMA), an information-geometric framework that decomposes LLM representations into local, intermediate, and global manifolds and learns cross-scale mappings that preserve geometry and information. Across GPT-2, BERT, RoBERTa, and T5, we observe consistent hierarchical patterns and find that MSMA improves alignment metrics under multiple estimators (e.g., relative KL reduction and MI gains with statistical significance across seeds). Controlled interventions at different scales yield distinct and architecture-dependent effects on lexical diversity, sentence structure, and discourse coherence. While our theoretical analysis relies on idealized assumptions, the empirical results suggest that multi-objective alignment offers a practical lens for analyzing cross-scale information flow and guiding representation-level control.
翻译:我们提出了多尺度流形对齐(MSMA),这是一个信息几何框架,它将大语言模型(LLM)的表征分解为局部、中间和全局流形,并学习能够保持几何结构与信息的跨尺度映射。在GPT-2、BERT、RoBERTa和T5等模型上的实验表明,我们观察到一致的层次化模式,并发现MSMA在多种估计器下(例如,相对KL减少和具有跨种子统计显著性的互信息增益)均提升了对齐度量指标。在不同尺度上进行的受控干预,对词汇多样性、句子结构和语篇连贯性产生了明显且依赖于模型架构的影响。虽然我们的理论分析依赖于理想化假设,但实证结果表明,多目标对齐为分析跨尺度信息流和指导表征层面的控制提供了一个实用的视角。