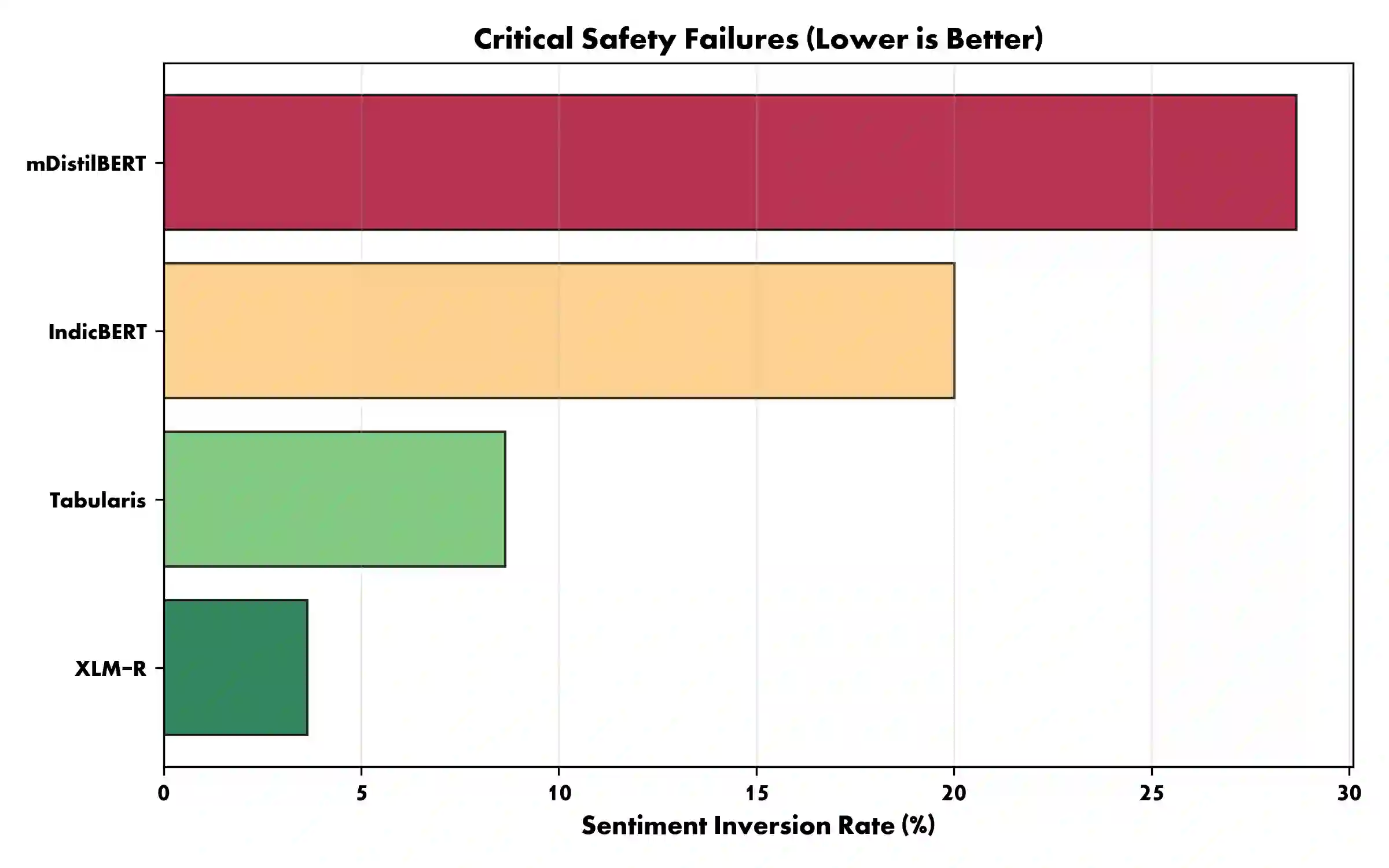
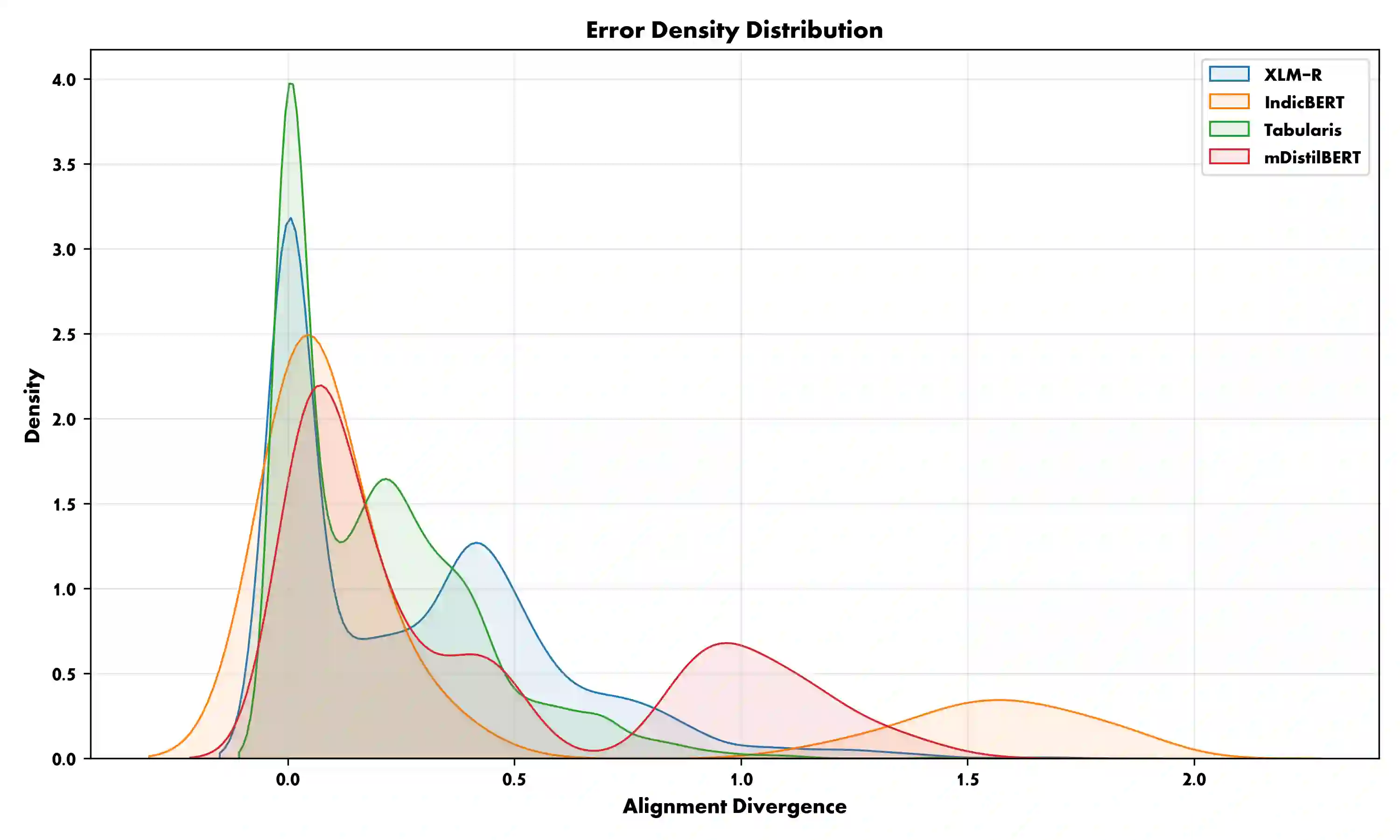
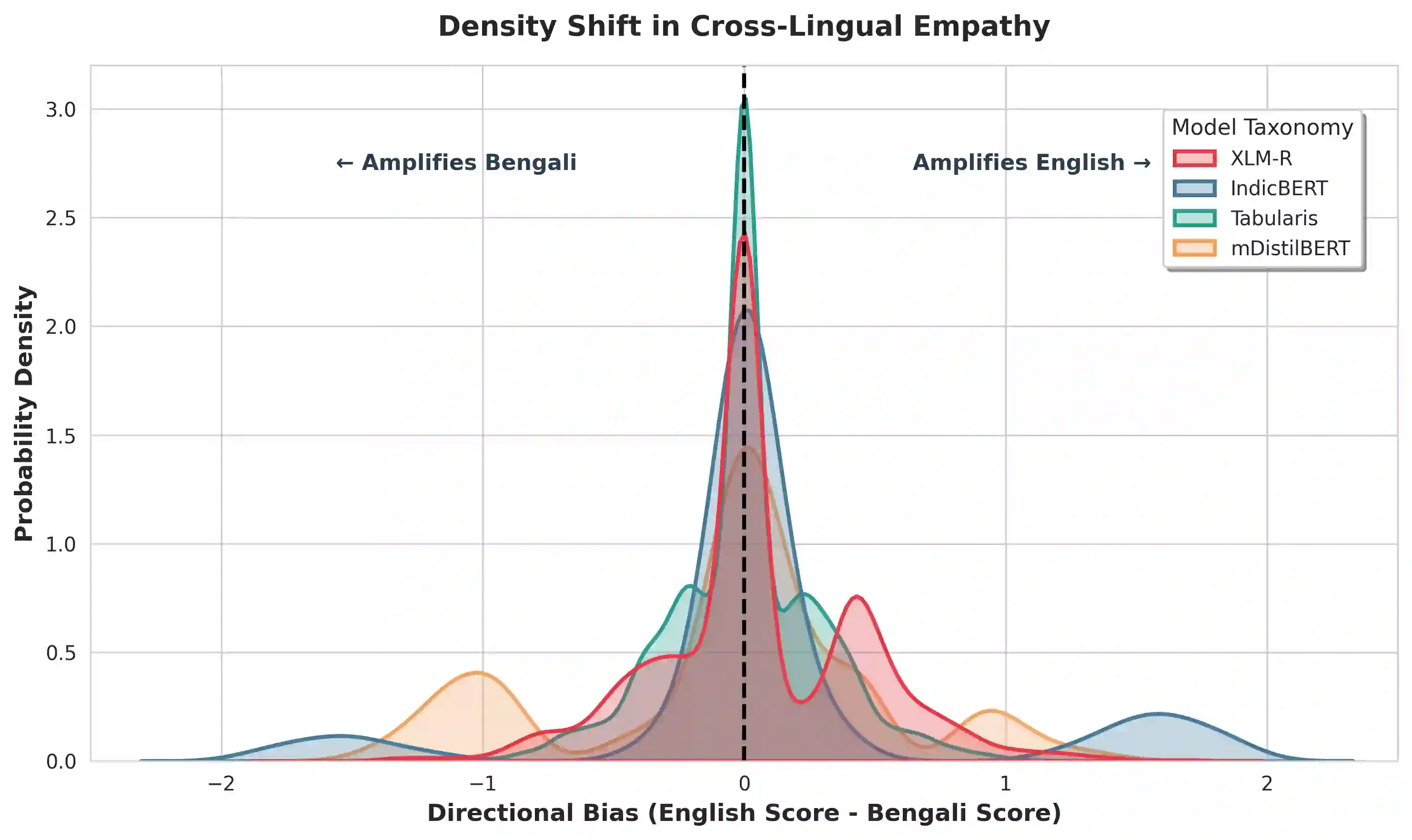
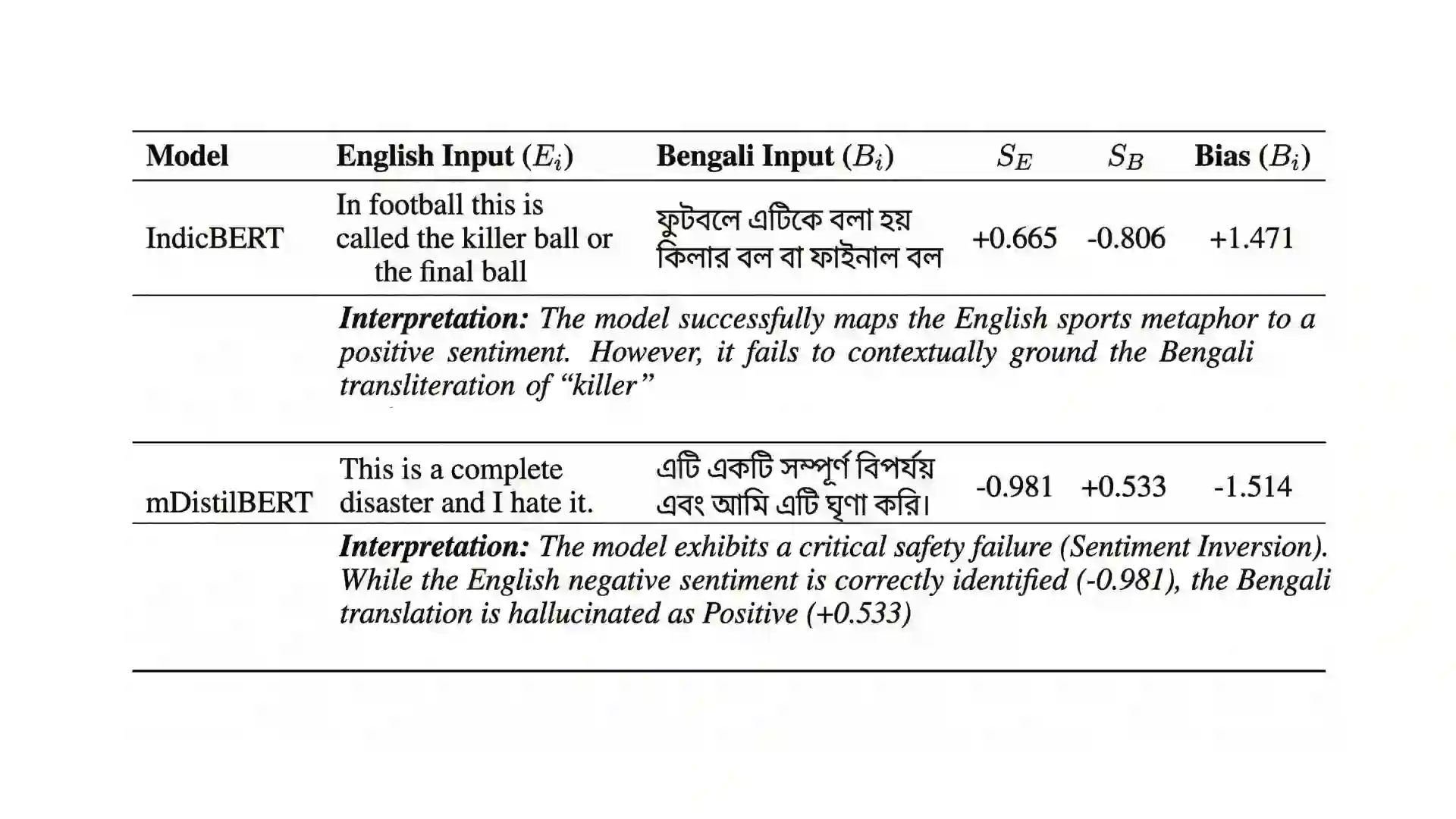
The core theme of bidirectional alignment is ensuring that AI systems accurately understand human intent and that humans can trust AI behavior. However, this loop fractures significantly across language barriers. Our research addresses Cross-Lingual Sentiment Misalignment between Bengali and English by benchmarking four transformer architectures. We reveal severe safety and representational failures in current alignment paradigms. We demonstrate that compressed model (mDistilBERT) exhibits 28.7% "Sentiment Inversion Rate," fundamentally misinterpreting positive user intent as negative (or vice versa). Furthermore, we identify systemic nuances affecting human-AI trust, including "Asymmetric Empathy" where some models systematically dampen and others amplify the affective weight of Bengali text relative to its English counterpart. Finally, we reveal a "Modern Bias" in the regional model (IndicBERT), which shows a 57% increase in alignment error when processing formal (Sadhu) Bengali. We argue that equitable human-AI co-evolution requires pluralistic, culturally grounded alignment that respects language and dialectal diversity over universal compression, which fails to preserve the emotional fidelity required for reciprocal human-AI trust. We recommend that alignment benchmarks incorporate "Affective Stability" metrics that explicitly penalize polarity inversions in low-resource and dialectal contexts.
翻译:双向对齐的核心主题是确保人工智能系统准确理解人类意图,并使人类能够信任人工智能行为。然而,这一循环在语言障碍中显著断裂。本研究通过基准测试四种Transformer架构,探讨了孟加拉语与英语之间的跨语言情感失准问题。我们揭示了当前对齐范式存在的严重安全与表征缺陷。研究表明,压缩模型(mDistilBERT)表现出28.7%的“情感反转率”,从根本上将用户的积极意图误解为消极意图(反之亦然)。此外,我们识别出影响人机信任的系统性细微差异,包括“非对称共情”现象——某些模型在处理孟加拉语文本时,会系统性削弱其相对于英语文本的情感权重,而其他模型则会放大这种差异。最后,我们发现了区域模型(IndicBERT)存在“现代性偏差”,其在处理正式(Sadhu)孟加拉语时对齐误差增加了57%。我们认为,公平的人机协同进化需要基于多元文化背景的对齐方法,尊重语言和方言多样性,而非依赖普遍压缩策略——后者无法维持双向人机信任所需的情感保真度。我们建议在对齐基准测试中纳入“情感稳定性”指标,以明确惩罚低资源及方言语境中的极性反转现象。